




摘要: Web日誌記錄了網站被訪問的情況,在Web安全的應用中,Web日誌常被用來進行攻擊事件的回溯和取證。Webshell大多由網頁腳本語言編寫,常被入侵者用作對網站服務器操作的後門程序,網站被植入Webshell就說明網站已被入侵。Webshell檢測手段常見的有運行後門查殺工具,比如D盾,或者部署防護軟硬件對網站流量和本地文件進行檢查,代價較大且對網站的訪問性能有影響。因此,結合作者這幾年做服務器入侵分析的一點經驗,總結幾點基於Web日誌的輕量級的Webshell檢測思路,通過對服務器日誌文本文件進行分析,發現被植入的Webshell。 本文有點學術化,主要是提出幾種簡單易操作的思路。
1 Web日誌與Webshell的關聯
Web日誌是 Web 服務器(如IIS、Apache)記錄用戶訪問行爲產生的文件,標準的Web日誌是純文本格式,每行一條記錄,對應客戶端瀏覽器對服務器
資源的一次訪問典型的日誌包括來源地址、訪問日期、訪問時間、訪問URL等豐富的信息,對日誌數據進行分析,不僅可以檢測到可疑的漏洞攻擊行爲,還可以提取特定時間段特定 IP 對應用的訪問行爲。
Web日誌的格式雖略有不同,但記錄的內容基本一致。這裏以IIS服務器下W3C格式的日誌爲例,如圖1。
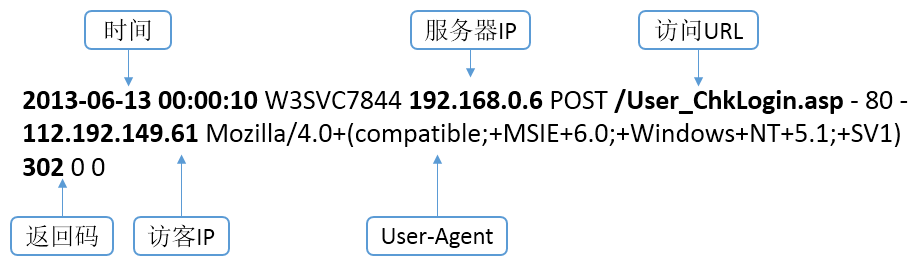
圖1 日誌示例
本文實驗數據來自一臺曾被入侵的IIS服務器脫敏後的日誌文件,日誌時間範圍爲2013年6月-2014年6月,該服務器採用W3C日誌格式,默認記
錄字段如圖2。
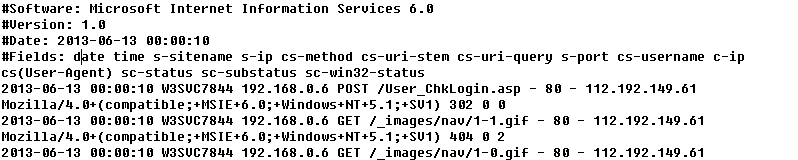
圖2 日誌文件實例
各字段說明如下。
date:發出請求時候的日期。
time:發出請求時候的時間。
s-sitename:服務名,記錄當記錄事件運行於客戶端上的Internet服務的名稱和實例的編號。
s-ip:服務器的IP地址。
cs-method:請求中使用的HTTP方法,GET/POST。
cs-uri-stem:URI資源,記錄做爲操作目標的統一資源標識符(URI),即訪問的頁面文件。
cs-uri-query:URI查詢,記錄客戶嘗試執行的查詢,只有動態頁面需要URI查詢,如果有則記錄,沒有則以連接符-表示。即訪問網址的附帶參數。
s-port:爲服務配置的服務器端口號。
cs-username:用戶名,訪問服務器的已經過驗證用戶的名稱,匿名用戶用連接符-表示。
c-ip:客戶端IP地址。
cs(User-Agent):用戶代理,客戶端瀏覽器、操作系統等情況。
sc-status:協議狀態,記錄HTTP狀態代碼,200表示成功,403表示沒有權限,404表示找不到該頁面,具體說明在下面。
sc-substatus:協議子狀態,記錄HTTP子狀態代碼。
sc-win32-status:Win32狀態,記錄Windows狀態代碼。
通過Web日誌,我們可以知道在某一個時刻,某個訪客訪問了服務器的某個文件。經過分析,Webshell的訪問特徵通常包括特徵文件名、特徵參數
、訪問頻率、是否爲孤立頁面等。說明如表1所示。

上述特徵皆可通過對Web日誌條目進行特徵匹配和訪問頻率統計得到。
2 檢測思路的提出
本文對基於Web日誌的Webshell檢測思路如下,在對日誌文件進行預處理後,分別對日誌記錄進行文本特徵匹配、統計特徵計算與文件關聯性分析,
最後對檢測結果彙總,列出疑似的Webshell文件。
2.1日誌預處理
基於檢測Webshell的目的,需要對原始的Web日誌記錄進行提取、分解、過濾、刪除和合並,再轉化成適合進行程序處理的格式。
日誌預處理的步驟如下,
1) 數據清理
首先,由於Webshell通常爲腳本頁面,因此可刪除靜態的網站文件訪問記錄,如文件後綴爲html、jpg、ico、css、js等,但需要注意,當網站存在文件包含漏洞或服務器解析漏洞的時候,需要注意異常文件名或URL,如“bg.asp:.jpg”和“/databackup/1.asp/imges/page_1.html”,此類文件名或URL也能具備Webshell功能,因此需對此種情況建立特徵庫進行排除。其次,刪除日誌記錄的多餘字段,包括空字段以及和Webshell訪問無關的字段,比如s-sitename、sc-substatus和sc-win32-status。最後,需要刪除用戶訪問失敗的記錄,比如sc-status字段值爲404,表示該文件不存在,此條記錄可以刪除,儘可能多得排除冗餘日誌記錄。
2) 訪客識別
訪客識別的目的是從每條日誌記錄裏把訪客和被訪問頁面關聯起來,通常情況下可以通過cs-username、c-ip和cs(User-Agent)標識一個訪客,網站未設置登錄功能時,可以採用IP和User-Agent來標識一個訪客。初步分析時,可以認爲不同的IP地址代表不同的用戶,其次,在NAT(NetworkAddressTranslation,網絡地址轉換)技術普遍應用的情況下,同一IP下可能存在多個用戶,這個時候可以結合User-Agent進行判斷,User-Agent通常會因爲操作系統版本和瀏覽器版本而有所變化。如果IP地址和User-Agent都一樣,也可以通過分析頁面訪問的規律來分析是否存在多個訪客。在訪客識別中,可以注意識別網絡爬蟲程序,如cs(User-Agent)字段爲“Baiduspider”,可以認爲是百度爬蟲,在Webshell的檢測中,這裏日誌記錄可以排除。
3) 會話識別
會話(session)識別的目的是爲了分析訪客在瀏覽站點期間的一系列活動,比如訪客首先訪問了什麼頁面,其次訪問了什麼頁面,在某個頁面提交了某個參數。通過分析多個用戶的訪問序列和頁面停留時間,可以從日誌中統計頁面的訪問頻率和判斷孤立頁面。
2.2文本特徵匹配
通過本地搭建服務器環境,對大量Webshell頁面進行訪問測試和記錄,建立Web日誌的文本特徵庫,在所有文本信息中,主要提取Webshell在Web日誌訪問中的URI資源(對應字段cs-uri-stem)特徵和URI查詢(對應字段cs-uri-query)特徵。特徵示例如表2。
爲了提高匹配覆蓋率,通常將一類靜態特徵歸納成正則表達式的方式進行匹配,例如正則表達式“0-9]{1,5}\.asp”表示匹配文件名爲一到五位阿拉伯數字的後綴爲asp的文件。除了基本的特徵庫的檢測,爲提高Webshell文件的覆蓋面和對未知Webshell 的檢測能力,可採用支持向量機(Support Vector Machine,SVM)機器學習算法,通過對正常網站文件的訪問特徵集和Webshell文件訪問特徵集進行訓練,來提高從Web日誌中檢測Webshell的能力。

2.3基於統計特徵的異常文件檢測
在統計特徵中,主要考慮網頁文件的訪問頻率,訪問頻率指的是一個網頁文件在單位時間內的訪問次數,通常正常的網站頁面由於向訪客提供服務因此受衆較廣,所以訪問頻率相對較高。而Webshell是由攻擊者植入,通常只有攻擊者清楚訪問路徑,因此訪問頻率相對較低。值得注意的是,網站開始運營時就會存在一定數量的正常頁面,而Webshell通常在一段時間後纔會出現,因此統計和計算頁面訪問頻率的時候,針對某一頁面,要採用該頁面第一次被訪問到最後一次被訪問的時間段作爲統計區間,然後計算單位時間內的訪問次數,得到訪問頻率。需要說明的是,單憑訪問頻率特徵,只能找出異常文件,無法確定一定是Webshell,一些正常頁面的訪問頻率也會較低,比如後臺管理頁面或者網站建設初期技術人員留下的測試頁面訪問頻率也較低。這裏用f(A) 表示計算後的網站頁面A的訪問頻率,Tfirst(A)表示網站頁面A首次被訪問的時間,Tend(A) 表示網站頁面A最後一次被訪問的時間,COUNTFE(A)表示網站頁面A在時間Tfirst(A)到Tend(A)期間的被訪問次數。因此,網站頁面A的訪問頻率計算如下,
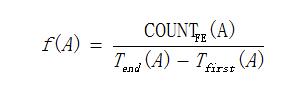
時間單位可根據需要選擇小時、天、星期、月等。
2.4基於文件出入度的文件關聯性檢測
文件關聯性主要是指網頁文件之間是否有交互,即是否通過超鏈接關聯起來引導用戶訪問。而孤立文件通常是指沒有與其他頁面存在交互的頁面,一個網頁文件的入度衡量的是訪客是否從其他頁面跳轉到該頁面,同理,一個網頁文件的出度衡量的是訪客是否會從該頁面跳轉到其他頁面。正常網站頁面會互相鏈接,因此會有一定的出入度,而Webshell通常與其他網站頁面沒有超鏈接,通常出入度爲0。需要注意的是,什麼是孤立,與其他頁面的交互度爲多少算孤立,都是相對的。而且,有的Webshell也會有一定的出入度,比如當Webshell採用超鏈接列出網站目錄中的文件的時候,就會產生與其他頁面的交互。當需要多個腳本協同作用的Webshell 也會產生交互。同樣,單憑文件出入度特徵,只能找出異常文件,無法確定一定是Webshell,一些正常頁面的出入度也會較低,比如特意隱藏的獨立後臺管理頁面或者網站建設初期技術人員留下的獨立測試頁面出入度也較低。網頁文件相互鏈接示意圖如圖3所示。
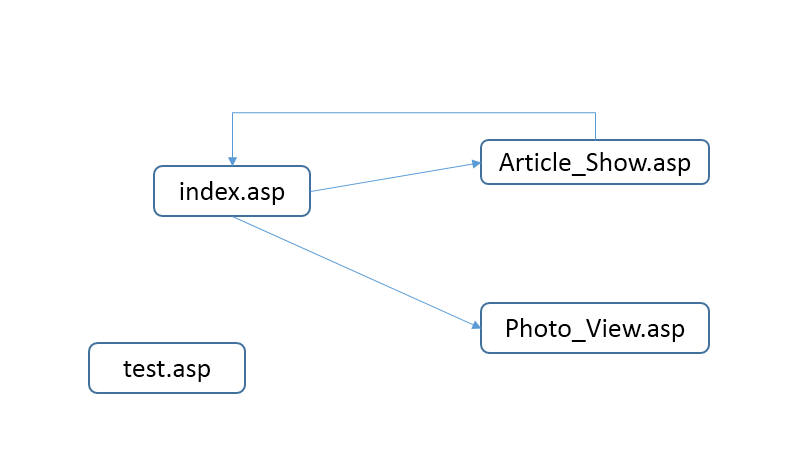
圖3網頁文件鏈接示意
如上例所示,本文對上述網頁文件出入度的統計如下,
index.asp:出度爲2,入度爲1;
Article_Show.asp:出度爲1,入度爲1;
Photo_View.asp:出度爲0,入度爲1;
test.asp:出度爲0,入度爲0 ,判斷爲孤立文件。
3 檢測方法可行性驗證
本文的重點在於提出一種從Web日誌中檢測Webshell的思路,找出可行的檢測方法。本章節通過對實際的被入侵站點的日誌記錄進行分析,通過對比正常網頁文件與Webshell在文本特徵、統計特徵和文件關聯性特徵,對第2章節提出的檢測方法進行可行性驗證。首先要考慮的是對照組的設置,也就是正常文件組和Webshell文件組的選取,本文實驗數據來自一臺曾被入侵的IIS服務器脫敏後的日誌文件與Web目錄文件。首先採用基於本地文件特徵的Webshell查殺工具“D盾Webshell查殺工具”,對測試的Web目錄文件進行檢測,檢測結果如圖5所示。
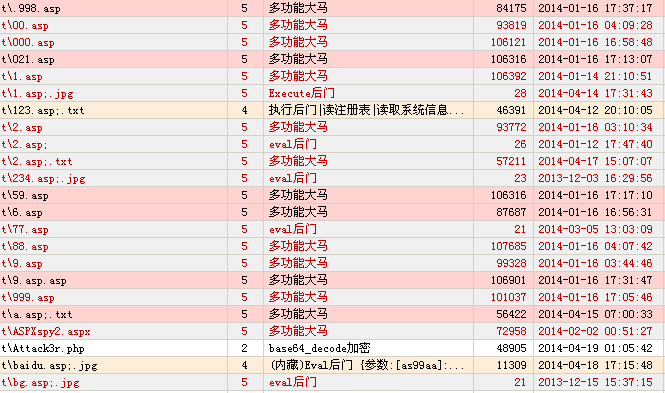
圖5 D盾查殺結果
在“D盾Webshell查殺工具”檢測結果的基礎上,結合人工判斷,最終選取10個確定的Webshell文件作爲Webshell文件組。然後對正常網頁文件,根據對網站目錄的分析,基於涵蓋不同目錄深度和頁面功能的考慮下,人工選取10個文件作爲正常文件組。正常文件組和Webshell文件組選取情況如表3所示。

3.1文本特徵對比
分別統計正常文件組和Webshell文件組的URI資源(對應字段cs-uri-stem)特徵和URI查詢(對應字段cs-uri-query)特徵,看是否有較爲明顯的區別。
如表4所示。

由上圖可以知道,Webshell文件和正常網頁文件在日誌中的訪問特徵有較爲明顯的區別,採用模式匹配和機器學習的方式進行分類檢測思路可行,
且便於實施。
3.2統計特徵計算和對比
分別統計正常文件組和Webshell文件組的訪問頻率,看是否有較爲明顯的區別。如表5所示。
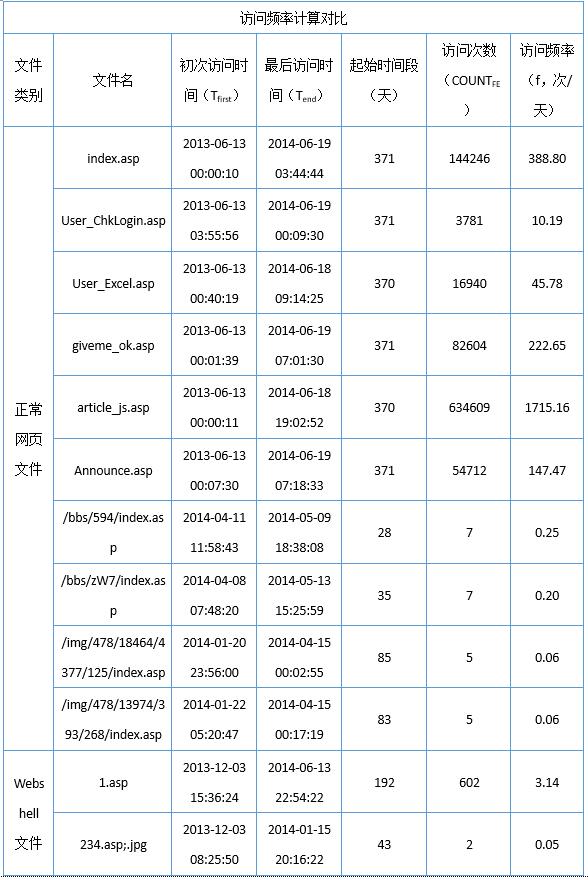
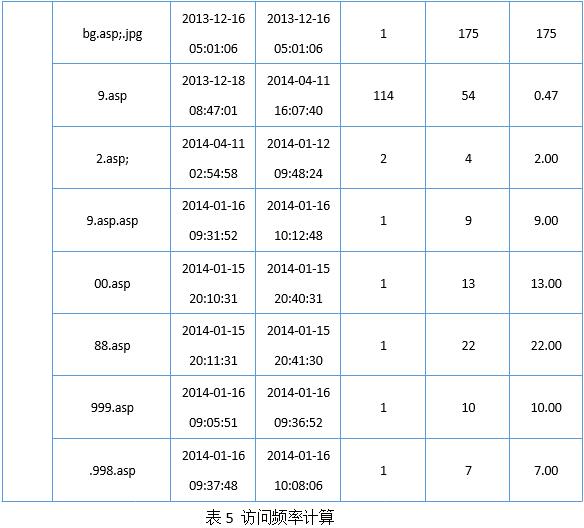
通過對實驗數據進行分析,可得出如下結論。
1) 在目錄深度一致,和起始時間段較長的情況下(以大於30天爲判斷依據),正常網頁文件的訪問頻率明顯高於Webshell文件。
2) 目錄深度較高的正常網頁文件,index.asp在三級目錄下,訪問頻率也會較低,因此判斷是否爲Webshell文件時,要把訪問頻率和目錄深度結合起來進行考慮。
3) 單從Webshell文件的訪問頻率來看,有的數據特徵呈現訪問頻率較高,仔細分析日誌發現,該類Webshell往往是被攻擊者當做一次性後門使用,起始階段只有1天,而且訪客單一,且有時攻擊者會對自己上傳的Webshell文件進行自動化的利用和掃描,導致較短時間內出現大量訪問行爲,呈現高頻訪問,特徵,如bg.asp;.jpg。在這種情況下,僅憑藉訪問頻率難以判斷。經過分析和思考,爲了準確判斷此類Webshell,需要再結合文件的起始時間段和單位時間的獨立訪客數進行綜合判斷,當某個網頁文件的呈現起始時間段較短,單位時間獨立訪客數較少的特徵時,可首先判定爲異常文件,再結合訪問頻率進行分析。這樣便能有效解決誤報問題。通過測試數據可以看出,在基於Web日誌進行Webshell檢測的過程中,單憑網頁文件訪問頻率特徵,誤報率較高。需要結合網頁文件目錄深度、起始時間段和單位時間獨立訪客數等特徵進行綜合判斷。而這3類特徵,也可從Web日誌中輕易得到。
綜上所述,基於訪問頻率計算與網頁文件目錄深度、起始時間段和單位時間獨立訪客數等特徵相結合的Webshell檢測方法可行。
3.3頁面關聯性分析對比
分別統計正常文件組和Webshell文件組文件是否能從Web日誌中發現多次出現的訪問序列,訪問序列反應當前頁面與網站其他頁面的關聯性,若無,則判斷爲孤立文件。如表6所示。
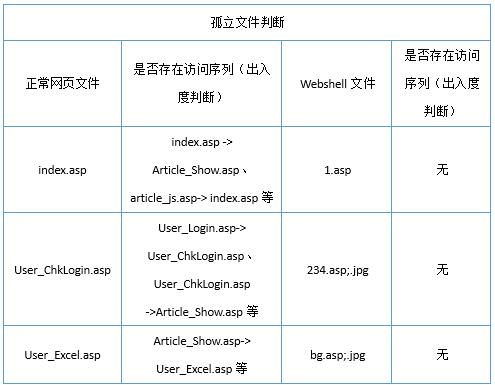
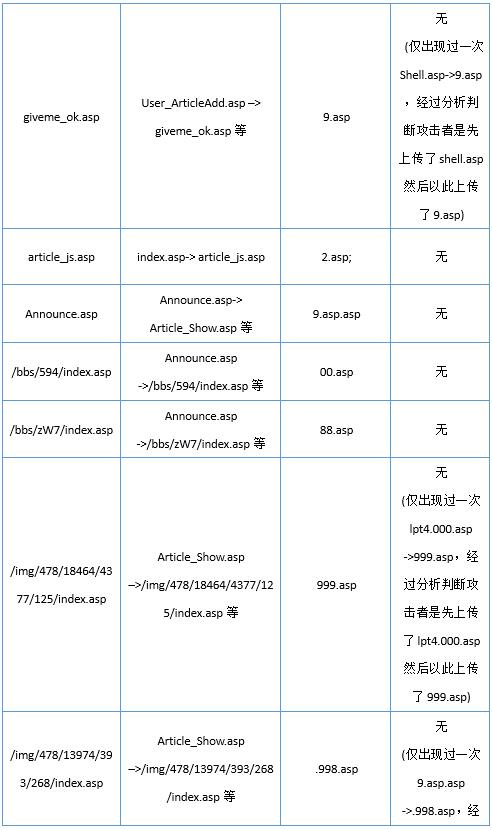

實驗數據顯示,正常網頁文件通常存在互相關聯,而Webshell文件通常不存在文件之前的關聯,關聯性區分明顯。原因是正常網頁文件處於網站架構設計會互相設置超鏈接,而Webshell文件往往是攻擊者通過網站漏洞直接上傳或者通過已存在的Webshell上傳到站點目錄下的。而通過對Web日誌進行分析發現,Web日誌中保留了曾經存在過但是之後被刪除的Webshell的訪問記錄,使得通過Web日誌檢測Webshell文件更加全面,彌補了本地Webshell文件檢測無法追溯歷史攻擊的不足。
綜上說述,通過從Web日誌中分析頁面關聯性來檢測異常文件或Webshell的方法可行。
4 結語
本文首先闡述了Web日誌和Webshell的關聯,然後提出了幾點基於Web日誌檢測Webshell後門程序的檢測思路,從文本特徵、統計特徵和關聯性特徵三個維度對正常網頁文件和Webshell文件進行區分和判斷,在初期方法設計的基礎上,通過對實際的被入侵服務器的Web日誌進行實驗和驗證,發現並彌補了方法設計的疏漏,證明了上述幾點基於Web日誌的Webshell檢測方法的可行性和有效性。