




一、PyCharm基本设置
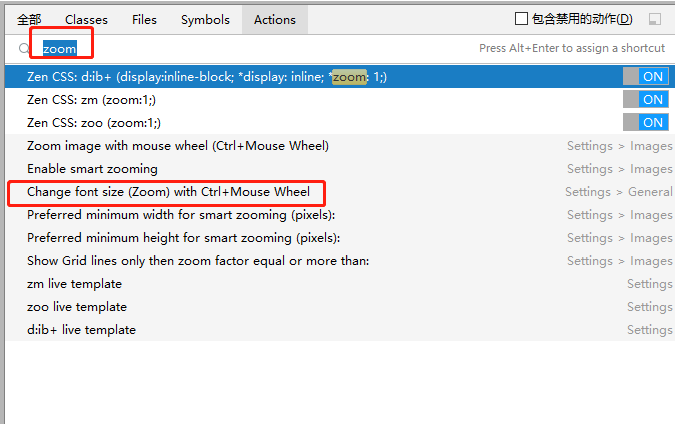
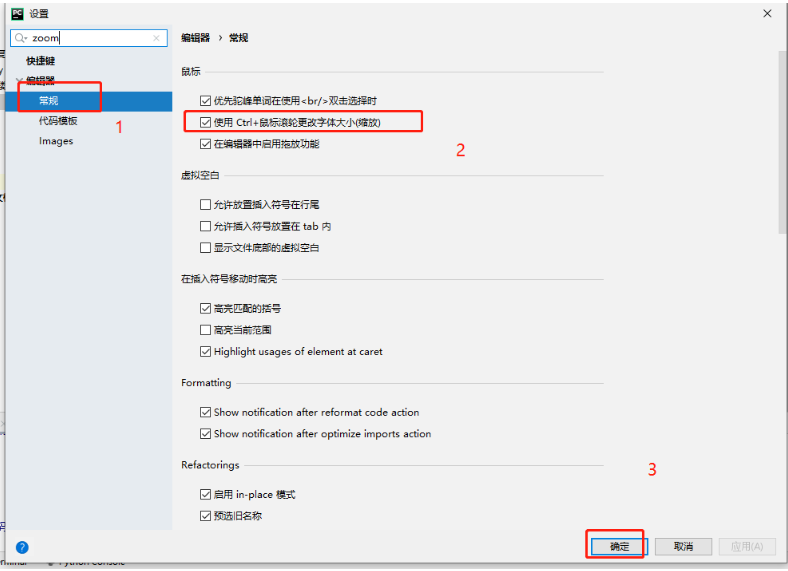
1、用Ctrl+鼠标滚轮--放大或缩小字体

搜索zoom
2、在Windows资源管理器打开文件或目录
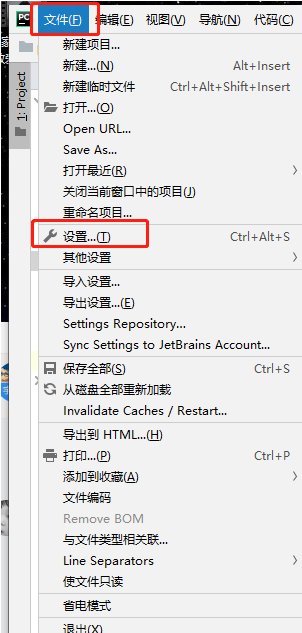
搜索keymap
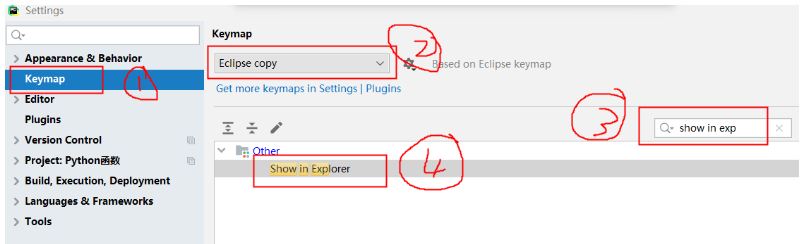
设置成不常用的键即可,如F3。
3、代码提示
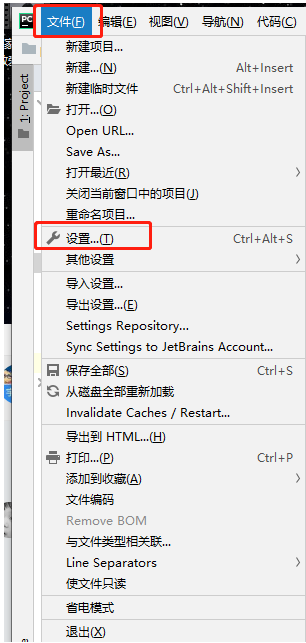
搜索letter
二、自定义函数
1.为什么要使用函数
函数中的代码一次编写,多处运行;
函数可以让代码复用,减少代码冗余。
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
函数能提高应用的模块性,和代码的重复利用率。你已经知道Python提供了许多内建函数,比如print()。但你也可以自己创建函数,这被叫做用户自定义函数。
假设我有这样的需求:
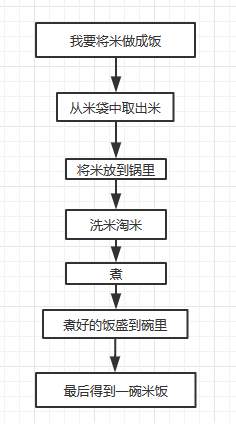
但是我还是觉得太麻烦了,每次想吃饭的时候都要重复这样的步骤。此时,我希望有这样的机器:
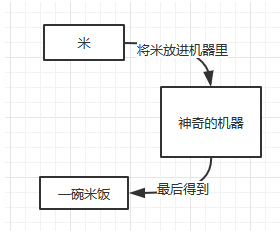
将重复的工作封装到一起,我们只要向机器里放入东西,就能得到我们想要的。
这也就是所谓的代码重用。
例子
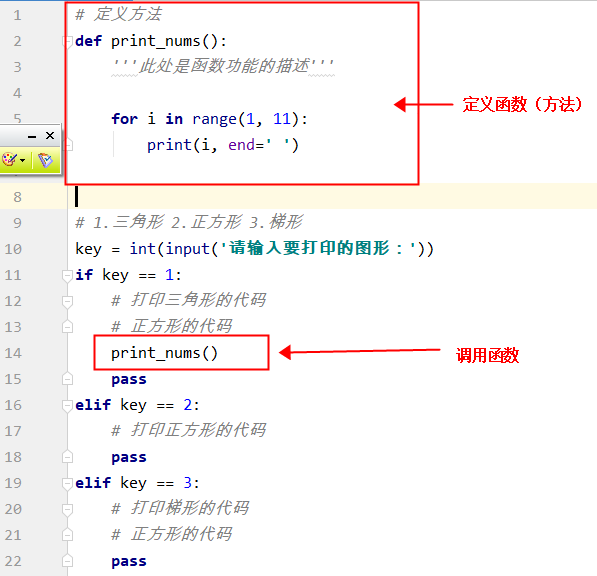
# 定义方法
def print_nums():
"""此处是函数功能的描述"""
for i in range(1,11):
print(i,end=" ")
# 1.三角形 2.正方形 3.梯形
key = int(input('请输入要打印的图形:'))
if key == 1:
# 打印三角形的代码
print_nums()
pass
elif key == 2:
# 打印梯形的代码
pass
elif key == 3:
# 正方形的代码
pass输出结果如下:
请输入要打印的图形:1 1 2 3 4 5 6 7 8 9 10 进程已结束,退出代码 0
分析一下

2、定义函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
关键字: def
函数代码块以 def 关键词开头,后接函数标识符名称和圆括号(),结尾处有冒号。
函数内第一行通常书写注释,表名该函数的意义
注释后空一行,开始写代码块,代码库要缩进
任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
函数内容以冒号起始,并且缩进。
return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
函数结束后,空2行
函数调用后空1行,再执行别的代码
语法
#代码如下
def functionname( parameters ):
"函数_文档字符串"
function_suite
return [expression]默认情况下,参数值和参数名称是按函数声明中定义的的顺序匹配起来的。
三、函数类型
Python函数可以使用的参数类型:
必备参数
命名参数
缺省参数
不定长参数
-
参数类型:
- 1、位置参数:参数的位置(顺序)很重要,形参和实参个数要匹配
- 2、关键字参数:对参数的位置要求不是很严格
- 3、默认值参数:
- (1)如果形参中指定了默认值,在实参中可以不传递该形参对应的实参
- (2)如果形参中指定了默认值,在实参汇总传递该参数后,最终参数以传递的实参为准
- 4、不定长参数:
- (1)*a:接收传递单个值,保存为元组
- (2)**b:接收键值对形式的参数,保存为字典格式
1、无参函数
无参函数实现和调用:
# 定义无参函数
def say_hi():
"""介绍自己的函数"""
print('我是xgp,今年18岁,年收入xxxx元')
# 调用无参函数
say_hi()输出结果如下:
我是xgp,今年18岁,年收入xxxx元 进程已结束,退出代码 0
2、带参函数
下面说说带参数的函数:
- 形参:指的是形式参数,是虚拟的,不占用内存空间,形参单元只有被调用的时才分配内存单元
- 实参:指的是实际参数,是一个变量,占用内存空间,数据传递单向,实参传给形参,形参不能传给实参
例子
# 定义带参函数:形参(形式参数,模板)
def say_hi(name,age,money):
"""介绍自己的函数"""
print('我是'+name+',今年'+str(age)+'岁,年收入'+str(money)+'元。')
# 调用带参函数:实参(实际传递的参数)
say_hi('xgp',20,20000)输出结果如下:
我是xgp,今年20岁,年收入20000元。 进程已结束,退出代码 0注意事项:调用函数时,实参传递的个数
要与形参保持一致|
(1)位置参数
从上面的例子可以看出,实际参数和形式参数是一一对应的,如果调换位置,x和y被调用的时,位置也会互换,代码如下:
def test(x,y):
print(x)
print(y)
print("--------互换前-----")
test(1,2)
print("--------互换后-----")
test(2,1)
#输出
--------互换前-----
1
2
--------互换后-----
2
1因为定义x,y两个形参,所以传递实参的时候,也只能传递两个实参,多一个或少一个都是有问题的:
a:多传递一个参数
def test(x,y):
print(x)
print(y)
print("--------多一个参数----")
test(1,2,3)
#输出
--------多一个参数----
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8, in <module>
test(1,2,3)
TypeError: test() takes 2 positional arguments but 3 were given #test()函数需要传两个实参,你传了三个实参b:少传递一个实参
def test(x,y):
print(x)
print(y)
print("--------少一个参数----")
test(1)
#输出
--------少一个参数----
Traceback (most recent call last):
File "D:/PycharmProjects/pyhomework/day3/函数_带参数.py", line 8, in <module>
test(1)
TypeError: test() missing 1 required positional argument: 'y'
#没有给y参数传实参(2)关键字参数
上面的位置参数,看起来有点死,必须形参和实参的位置一一对应,不然就会传错参数,为了避免这种问题,就有了关键字参数的玩法:关键字传参不需要一一对应,只需要你指定你的哪个形参调用哪一个实参即可;
def test(x,y):
print(x)
print(y)
print("--------互换前------")
test(x=1,y=2)
print("--------互换后------")
test(y=2,x=1)
#输出
--------互换前------
1
2
--------互换后------
1
23、默认参数
调用函数时,默认参数的值如果没有传入,则被认为是默认值。下例会打印默认的age,如果age没有被传入:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print "Name: ", name
print "Age ", age
return
#调用printinfo函数
printinfo( age=50, name="miki" )
printinfo( name="miki" )输出结果如下:
Name: miki Age 50 Name: miki Age 35
4、不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]*加了星号()的变量名会存放所有未命名的变量参数。不定长参数实例如下:**
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )输出结果如下:
输出: 10 输出: 70 60 50
(1)例子
# 不定长参数的类型
def no_test(*args,**b):
print((args))
print(b)
no_test(1,2,3)
no_test(name='test',ages=18)输出结果如下:
(1, 2, 3) {} () {'name': 'test', 'ages': 18}
5、匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
语法
lambda函数的语法只包含一个语句,如下:
lambda [arg1 [,arg2,.....argn]]:expression如下实例:
相加后的值为 : 30
相加后的值为 : 40四、rerun传递列表类型数据
return语句[表达式]退出函数,选择性地向调用方返回一个表达式。不带参数值的return语句返回None。之前的例子都没有示范如何返回数值,下例便告诉你怎么做:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 可写函数说明
def sum( arg1, arg2 ):
# 返回2个参数的和."
total = arg1 + arg2
print "函数内 : ", total
return total
# 调用sum函数
total = sum( 10, 20 )输出结果如下:
函数内 : 30注意:在函数内没有写return语句的时候,默认return的是一个空对象。也就是就算没写,python内部也做了处理。
此时,有部分人分不清函数的输出和返回值的区别。
这样说吧,在函数里print之类的操作能够输出内容,是因为虽然函数的执行环境是独立的,但代码还是有效的。外部能进行的操作,函数内部也可以。但是并不是所有的函数在执行完毕后都有如此明显的输出效果,此时我们需要查看函数是否成功,或者说我放了米进去,你操作一番之后总要把饭给我拿出来吧。
这就是函数中return的意义。返回一个对象。这个对象可以是对执行状态的说明,也可以是处理后的结果等等。
1、return语句返回简单类型
def test():
return 'hello'
print(test())
# return 语句返回字典
def show_info(name,age):
person = {'name':name,'age':age}
return person
print(show_info('test',18))输出结果如下:
{'name': 'test', 'age': 18} 进程已结束,退出代码 0
2、用户问候
def say_hi(first_name,last_name):
"""返回完整名字"""
full_name = first_name + ' ' + last_name
return full_name
while True:
print('请输入您的姓名:')
f_name = input('姓:')
if f_name =='q':
break
l_name = input('名:')
if l_name == 'q':
break
# 调用函数
format_name = say_hi(f_name,l_name)
print('hello'+format_name+'!')输出结果如下:
请输入您的姓名: 姓:x 名:gp hellox gp!
3、传递列表类型数据
def test(names):
for name in names:
print(name)
user_name = ['sdf','fsd','fewfwef','fwefe']
test(user_name)输出结果如下:
sdf fsd fewfwef fwefe 进程已结束,退出代码 0
5、range函数的练习
- 当只用一个变量调用这个函数时,这个变量指的是输出的等差数列的终点,如
range(5) - 当给定两个变量时,分别指输出的起始值和终点,,如
range(2, 5) - 当给定三个变量时,在上一条的基础上第三个变量指输出时的步长,如
range(2, 5, -1)
(假定我们调用这个函数时总是用整数或浮点数)
分析一下如何实现这个函数,下面给出我的思路作为参考
- 一共需要三个参数是显而易见的;
- 最直观的感受是起始值是要有默认值的,如果不规定从哪里开始,那就从0开始;
- 步长也是要有默认值的,如果不规定,那么步长是1;
- 根据有默认值的参数要放在后面的原则,那么最理所当然的参数设计是
range_custom(stop, start=0, step=1) - 这个方案看上去可行,但是不满足刚才的后面两个要求,如果我们这样用两个变量调用,起始值和终点是反的;
- 我们加个判断就可以了,如果start用了初始值,那么说明我们调用的时候只给了一个参数,这个时候stop就是终点,如果start被重新赋值了说明给了至少两个参数,那么这时候把stop和start的值调换一下就可以了;
- 现在这个函数似乎可以满足大多数情况了,但是有一个bug,如果给定参数的时候给的start值就是0怎么办呢?如
range_custom(-5, 0)按目前的规则会被翻译成range(0, -5),但是我们的目的却是range(-5, 0); - 所以start的初始值不应该是数字而是别的数据类型,为了方便起见,我们把它的初始值赋为
None,我们的程序雏形就出来了。
def range_custom(stop, start=None, step=1):
if start is None:
return range(stop)
return range(stop, start, step)现在这个程序已经满足我们的要求了,但是看上去不太舒服,可以改成
def range_custom(start, stop=None, step=1):
if stop is None:
return range(start)
return range(start, stop, step)现在这个函数的参数顺序在逻辑上更好理解一些,可以说基本上满足我们的要求了。当然,本例只是为了说明参数的顺序问题,并不是为了实现range函数。事实上Python的range函数还包括参数实例化,生成器等知识,在后面我们应该还有机会再接触它。
可选参数
说到可选参数,可能有的人见过,却也不明白到底是什么意思,它一般是这样出现的
def func_option(*args):
return args*注意到我们声明函数的时候在参数名前加了个``星号,这是声明可选参数的方法。那么可选参数到底有什么用呢?**
可选参数的作用是用元组把所有多余的变量收集起来,这个元组的名字就是这个可选参数名。在上例func_option中我们可以用任意多个变量调用它,比如a = func_option(1, 2, 3)那么a就会是元组(1, 2, 3)。关于为什么是元组而不是列表,我们在上一篇Python进阶-简单数据结构中说过,元组在Python中往往是比列表更优先考虑使用的数据结构,具体原因在本文靠后深入自定义函数参数部分会讨论。
我们刚才说可选参数会收集多余的变量。我这么说是有原因的。
>>> def func_option(a, *args, c=2):
... return args
...
>>> func_option2(1)
()
>>> func_option2(1, 2)
(2,)
>>> func_option2(1, 2, 3)
(2, 3)*注意到我们的`args`把除了给普通参数的第一个变量以外的值都放进了元组中。这样做导致了一个,问题在于我们的有默认值的参数如果不给定参数名地调用的话,就永远只能用默认值了。而且如果我们在调用函数时不把有默认值的参数放在最后面程序还会报错。**
>>> func_option2(c=1, 2, 3)
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument那么有没有好的办法能规避这个问题呢?我们可以试试把可选参数放在有默认值的参数后面。
>>> def func_option3(a, c=2, *args):
... return args
...
>>> func_option3(1)
()
>>> func_option3(1, 2)
()
>>> func_option3(1, 2, 3)
(3,)
>>> func_option2(c=1, 2, 3)
File "<stdin>", line 1
SyntaxError: positional argument follows keyword argument那么这种形式的函数能不能解决之前的问题呢。看上去不行,不过我们知道了,调用函数的时候,要尽量把有默认值的参数放在靠后的位置赋予变量。那么这两种我们到底该用哪个方法呢?在实际操作中,我们倾向于将可选参数放在有默认值的参数之后,而且如果参数较多,我们倾向于调用函数时都会所有变量都加上参数名。而且实际操作中,其实可选参数用得不那么多,相对来说,另一种可选参数其实用得更多。这种可选参数的形式一般是这样
def func_optionkw(**kwargs):
return args在这种情况下,关键字可选参数都是作为键值对保存在参数名的的字典中。也就是说,在调用函数时,在满足一般参数以后,变量都应该以赋值语句的形式给出,等号左边作为键右边作为值。如果不这样做,就会报错了。
>>> func_optionkw(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: t2() takes 0 positional arguments but 1 was given需要说明的是,一个自定义函数只能有一个可选参数,同时也可以有至多一个关键字参数。其中关键字参数应该放在普通可选参数之后。
现在我们来总结一下函数参数顺序一般规律:
- 一般参数放在最前面
- 可选参数放在最后面
- 关键字可选参数放在一般可选参数后面
- 函数调用时尽量把有默认值的参数对应的变量放在靠后的位置
- 如果参数比较多,调用函数时,最好所有变量都指明参数名
以上这些,有的是为了防止函数定义时出错,有的是为了防止函数调用时出错,总之,应该养成良好的编程习惯。
五、变量作用域
一个程序的所有的变量并不是在哪个位置都可以访问的。访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序你可以访问哪个特定的变量名称。两种最基本的变量作用域如下:
- 全局变量
- 局部变量
六、全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
实例(Python 2.0+)
#!/usr/bin/python
# -*- coding: UTF-8 -*-
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print "函数内是局部变量 : ", total
return total
#调用sum函数
sum( 10, 20 )
print "函数外是全局变量 : ", total输出结果如下:
函数内是局部变量 : 30
函数外是全局变量 : 0