




在 Java 中,我們經常會使用到一些處理緩存數據的集合類,這些集合類都有自己的特點,今天主要分享下 Java 集合中幾種經常用的 Map、List、Set。
1、Map
一、背景
二、Map家族
三、HashMap、Hashtable等
四、HashMap 底層數據結構
2、List
一、List 包括的子類
二、ArrayList
三、ArrayList 源碼分析
四、LinkedList
五、LinkedList 源碼分析
3、Set
一、Set的實質
二、HashSet
三、TreeSet
01
集合 1:Map
背景
如果一個海量的數據中,需要查詢某個指定的信息,這時候,可能會猶如大海撈針,這時候,可以使用 Map 來進行一個獲取。因爲 Map 是鍵值對集合。Map這種鍵值(key-value)映射表的數據結構,作用就是通過key能夠高效、快速查找value。
舉一個例子:
import java.util.HashMap;
import java.util.Map;
import java.lang.Object;
public class Test {
public static void main(String[] args) {
Object o = new Object();
Map<String, Object> map = new HashMap<>();
map.put("aaa", o); //將"aaa"和 Object實例映射並關聯
Student target = map.get("aaa"); //通過key查找並返回映射的Obj實例
System.out.println(target == o); //true,同一個實例
Student another = map.get("bbb"); //通過另一個key查找
System.out.println(another); //未找到則返回null
}}
Map<K, V>是一種鍵-值映射表,當我們調用put(K key, V value)方法時,就把key和value做了映射並放入Map。當我們調用V get(K key)時,就可以通過key獲取到對應的value。如果key不存在,則返回null。和List類似,Map也是一個接口,最常用的實現類是HashMap。
在 Map<K, V> 中,如果遍歷的時候,其 key 是無序的,如何理解:
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("dog", "a");
map.put("pig", "b");
map.put("cat", "c");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " = " + value);
}
}}
cat = c
dog = a
pig = b
從上面的打印結果來看,其是無序的,有序的答案可以在下面找到。
接下來我們分析下 Map ,首先我們先看看 Map 家族:
它的子孫下面有我們常用的 HashMap、LinkedHashMap,也有 TreeMap,另外還有繼承 Dictionary、實現 Map 接口的 Hashtable。
下面針對各個實現類的特點來說明:
(1)HashMap:它根據鍵的 hashCode 值存儲數據,大多數情況下可以直接定位到它的值,因而具有高效的訪問速度,但遍歷順序卻是不確定的。HashMap最多隻允許一條記錄的鍵爲null,允許多條記錄的值爲null。HashMap 非線程安全,即任一時刻可以有多個線程同時寫HashMap,可能會導致數據的不一致。如果需要滿足線程安全,可以用 Collections 的靜態方法 synchronizedMap 方法使 HashMap 具有線程安全的能力,或者使用 ConcurrentHashMap(分段加鎖)。
(2)LinkedHashMap:LinkedHashMap 是 HashMap 的一個子類,替 HashMap 完成了輸入順序的記錄功能,所以要想實現像輸出同輸入順序一致,應該使用 LinkedHashMap。
(3)TreeMap:TreeMap 實現 SortedMap 接口,能夠把它保存的記錄根據鍵排序,默認是按鍵值的升序排序,也可以指定排序的比較器,當用 Iterator 遍歷 TreeMap 時,得到的記錄是排過序的。如果使用排序的映射,建議使用TreeMap。在使用 TreeMap 時,key 必須實現Comparable 接口或者在構造 TreeMap 傳入自定義的 Comparator,否則會在運行時拋出 ClassCastException 類型的異常。
(4)Hashtable:Hashtable繼承 Dictionary 類,實現 Map 接口,很多映射的常用功能與 HashMap 類似, Hashtable 採用"拉鍊法"實現哈希表 ,不同的是它來自 Dictionary 類,並且是線程安全的,任一時間只有一個線程能寫 Hashtable,但併發性不如 ConcurrentHashMap,因爲ConcurrentHashMap 引入了分段鎖。Hashtable 使用 synchronized 來保證線程安全,在線程競爭激烈的情況下 HashTable 的效率非常低下。不建議在新代碼中使用,不需要線程安全的場合可以用 HashMap 替換,需要線程安全的場合可以用 ConcurrentHashMap 替換。Hashtable 並不是像 ConcurrentHashMap 對數組的每個位置加鎖,而是對操作加鎖,性能較差。
上面講到了 HashMap、Hashtable、 ConcurrentHashMap ,接下來先看看 HashMap 的源碼實現:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
/**
* 默認大小 16
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
/**
* 最大容量是必須是2的冪30
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 負載因子默認爲0.75,hashmap每次擴容爲原hashmap的2倍
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 鏈表的最大長度爲8,當超過8時會將鏈表裝換爲紅黑樹進行存儲
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}從上面看到,HashMap 主要是數組 + 鏈表結構組成。HashMap 擴容是成倍的擴容。爲什麼是成倍,而不是1.5或其他的倍數呢?既然 HashMap 在進行 put 的時候針對 key 做了一些列的 hash 以及與運算就是爲了減少碰撞的一個概率,如果擴容後的大小不是2的n次冪的話,之前做的不是白費了嗎?
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;擴容後會重新把原來的所有的數據 key 的 hash 重新計算放入擴容後的數組裏面去。爲什麼要這樣做?因爲不同的數組大小通過 key 的 hash 出來的下標是不一樣的。 還有,數組 長度保持2的次冪,length-1的低位都爲1,會使得獲得的數組索引 in de x 更加均勻。
爲何說 Hashmap 是非線程安全的呢?原因:當多線程併發時,檢測到總數量超過門限值的時候就會同時調用 resize 操作,各自生成新的數組並rehash 後賦給底層數組,結果最終只有最後一個線程生成的新數組被賦給table 變量,其他線程均會丟失。而且當某些線程已經完成賦值而其他線程剛開始的時候,就會用已經被賦值的 table 作爲原始數組,這樣也是有問題滴。
疑問:
HashMap 中某個 entry 鏈過長,查詢時間達到最大限度,如何處理呢?這個在 Jdk1.8,當鏈表過長,把鏈表轉成紅黑樹(TreeNode)實現了更高的時間複雜度的查找。
HashMap中哈希算法實現?我們使用put(key,value)方法往HashMap中添加元素時,先計算得到key的 Hash 值,然後通過Key高16位與低16位相異或(高16位不變),然後與數組大小-1相與,得到了該元素在數組中的位置, 流程:
延伸:如果一個對象中,重寫了equals()而不重寫hashcode()會發生什麼樣的問題?儘管我們在進行 get 和 put 操作的時候,使用的key從邏輯上講是等值的(通過equals比較是相等的),但由於沒有重寫hashCode(),所以put操作時,key(hashcode1)-->hash-->indexFor-->index,而通過key取出value的時候 key(hashcode2)-->hash-->indexFor-->index,由於hashcode1不等於hashcode2,導致沒有定位到一個數組位置而返回邏輯上錯誤的值null。所以,在重寫equals()的時候,必須注意重寫hashCode(),同時還要保證通過equals()判斷相等的兩個對象,調用hashCode方法要返回同樣的整數值。而如果equals判斷不相等的兩個對象,其hashCode也可以相同的(只不過會發生哈希衝突,應儘量避免)。( 1. hash相同,但key不一定相同:key1、key2產生的hash很有可能是相同的,如果key真的相同,就不會存在散列鏈表了,散列鏈表是很多不同的鍵算出的hash值和index相同的 2. key相同,經過兩次hash,其hash值一定相同 )
ConcurrentHashMap 採用了分段鎖技術來將數據分成一段段的存儲,然後給每一段數據配一把鎖,當一個線程佔用鎖訪問其中一個段數據的時候,其他段的數據也能被其他線程訪問。
02
集合 2:List
集合 List 是接口 Collection 的子接口,也是大家經常用到的數據緩存。 List 進 行了元素 排序,且允許存放相同的元素,即有序,可重複 。我們先看看有哪些子類:
可以看到,其中包括比較多的子類,我們常用的是 ArrayList、LinkedList: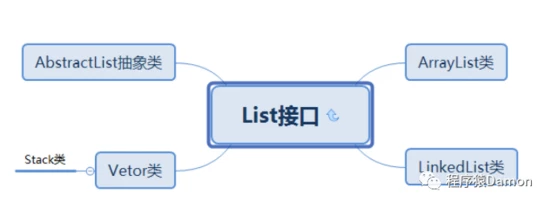
ArrayList:
優點:操作讀取操作效率高,基於數組實現的,可以爲null值,可以允許重複元素,有序,異步。
缺點:由於它是由動態數組實現的,不適合頻繁的對元素的插入和刪除操作,因爲每次插入和刪除都需要移動數組中的元素。
LinkedList:
優點:LinkedList由雙鏈表實現,增刪由於不需要移動底層數組數據,其底層是鏈表實現的,只需要修改鏈表節點指針,對元素的插入和刪除效率較高。
缺點:遍歷效率較低。HashMap和雙鏈表也有關係。
ArrayList 底層是一個變長的數組,基本上等同於Vector,但是ArrayList對writeObjec() 和 readObject()方法實現了同步。
transient Object[] elementData;
/**
-
Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;}
If multiple threads access an <tt>ArrayList</tt> instance
concurrently, and at least one of the threads modifies
the list structurally, it <i>must</i> be synchronized externally.
(A structural modification is any operation that adds or deletes one or more elements, or explicitly resizes the backing array; merely setting the value of an element is not a structural modification.)
This is typically accomplished by synchronizing
on some object that naturally encapsulates the list.
從註釋,我們知道 ArrayList 是線程不安全的,多線程環境下要通過外部的同步策略後使用,比如List list = Collections.synchronizedList(new ArrayList(…))。
源碼實現:
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();}
}
/**
-
Reconstitute the <tt>ArrayList</tt> instance from a stream (that is,
-
deserialize it).
*/
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}}
}
當調用add函數時,會調用ensureCapacityInternal函數進行擴容,每次擴容爲原來大小的1.5倍,但是當第一次添加元素或者列表中元素個數小於10的話,列表容量默認爲10。
/**
-
Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
-
Shared empty array instance used for empty instances.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
-
Shared empty array instance used for default sized empty instances.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
-
The array buffer into which the elements of the ArrayList are stored.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
-
The size of the ArrayList (the number of elements it contains).
*/
private int size;
擴容原理:根據當前數組的大小,判斷是否小於默認值10,如果大於,則需要擴容至當前數組大小的1.5倍,重新將新擴容的數組數據copy只當前elementData,最後將傳入的元素賦值給size++位置。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);}
/**
-
The maximum size of array to allocate.
-
Some VMs reserve some header words in an array.
-
Attempts to allocate larger arrays may result in
-
OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
-
Increases the capacity to ensure that it can hold at least the
-
number of elements specified by the minimum capacity argument.
-
@param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;}
接下來我們分析爲什麼 ArrayList 增刪很慢,查詢很快呢?
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
根據源碼可知,當調用add函數時,首先要調用ensureCapacityInternal(size + 1),該函數是進行自動擴容的,效率低的原因也就是在這個擴容上了,每次新增都要對現有的數組進行一次1.5倍的擴大,數組間值的copy等,最後等擴容完畢,有空間位置了,將數組size+1的位置放入元素e,實現新增。
刪除時源碼:
/**
-
Removes the element at the specified position in this list.
-
Shifts any subsequent elements to the left (subtracts one from their
-
indices).
-
@param index the index of the element to be removed
-
@return the element that was removed from the list
-
@throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);elementData[--size] = null;
return oldValue;
}
在刪除index位置的元素時,要先調用 rangeCheck(index) 進行 index 的check,index 要超過當前個數,則判定越界,拋出異常,throw new IndexOutOfBoundsException(outOfBoundsMsg(index)),其他函數也有用到如:get(int index),set(int index, E element) 等後面刪除重點在於計算刪除的index是末尾還是中間位置,末尾直接--,然後置空完事,如果是中間位置,那就要進行一個數組間的copy,重新組合數組數據了,這一就比較耗性能了。
而查詢:
/**
-
Returns the element at the specified position in this list.
-
@param index index of the element to return
-
@return the element at the specified position in this list
-
@throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
獲取指定index的元素,首先調用rangeCheck(index)進行index的check,通過後直接獲取數組的下標index獲取數據,沒有任何多餘操作,高效。
LinkedList 繼承AbstractSequentialList和實現List接口,新增接口如下:
addFirst(E e):將指定元素添加到劉表開頭
addLast(E e):將指定元素添加到列表末尾
descendingIterator():以逆向順序返回列表的迭代器
element():獲取但不移除列表的第一個元素
getFirst():返回列表的第一個元素
getLast():返回列表的最後一個元素
offerFirst(E e):在列表開頭插入指定元素
offerLast(E e):在列表尾部插入指定元素
peekFirst():獲取但不移除列表的第一個元素
peekLast():獲取但不移除列表的最後一個元素
pollFirst():獲取並移除列表的最後一個元素
pollLast():獲取並移除列表的最後一個元素
pop():從列表所表示的堆棧彈出一個元素
push(E e);將元素推入列表表示的堆棧
removeFirst():移除並返回列表的第一個元素
removeLast():移除並返回列表的最後一個元素
removeFirstOccurrence(E e):從列表中移除第一次出現的指定元素
removeLastOccurrence(E e):從列表中移除最後一次出現的指定元素
LinkedList 的實現原理:LinkedList 的實現是一個雙向鏈表。在 Jdk 1.6中是一個帶空頭的循環雙向鏈表,而在 Jdk1.7+ 中則變爲不帶空頭的雙向鏈表,這從源碼中可以看出:
//jdk 1.6
private transient Entry<E> header = new Entry<E>(null, null, null);
private transient int size = 0;
//jdk 1.7
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
從源碼註釋看,LinkedList不是線程安全的,多線程環境下要通過外部的同步策略後使用,比如List list = Collections.synchronizedList(new LinkedList(…)):
If multiple threads access a linked list concurrently,
and at least one of the threads modifies the list structurally,
it <i>must</i> be synchronized externally.
(A structural modification is any operation that adds or
deletes one or more elements; merely setting the value of
an element is not a structural modification.)
This is typically accomplished by synchronizing on some object
that naturally encapsulates the list.
爲什麼說 LinkedList 增刪很快呢?
/**
-
Appends the specified element to the end of this list.
-
<p>This method is equivalent to {@link #addLast}.
-
@param e element to be appended to this list
-
@return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
linkLast(e);
return true;
}
/**
-
Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;else
l.next = newNode;size++;
modCount++;
}
從註釋看,add函數實則是將元素append至list的末尾,具體過程是:新建一個Node節點,其中將後面的那個節點last作爲新節點的前置節點,後節點爲null;將這個新Node節點作爲整個list的後節點,如果之前的後節點l爲null,將新建的Node作爲list的前節點,否則,list的後節點指針指向新建Node,最後size+1,當前llist操作數modCount+1。
在add一個新元素時,LinkedList 所關心的重要數據,一共兩個變量,一個first,一個last,這大大提升了插入時的效率,且默認是追加至末尾,保證了順序。
再看刪除一個元素:
/**
-
Removes the element at the specified position in this list. Shifts any
-
subsequent elements to the left (subtracts one from their indices).
-
Returns the element that was removed from the list.
-
@param index the index of the element to be removed
-
@return the element previously at the specified position
-
@throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
/**
-
Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;} else {
prev.next = next;
x.prev = null;}
if (next == null) {
last = prev;} else {
next.prev = prev;
x.next = null;}
x.item = null;
size--;
modCount++;
return element;
}
刪除指定index的元素,刪除之前要調用checkElementIndex(index)去check一下index是否存在元素,如果不存在拋出throw new IndexOutOfBoundsException(outOfBoundsMsg(index));越界錯誤,同樣這個check方法也是很多方法用到的,如:get(int index),set(int index, E element)等。
註釋講,刪除的是非空的節點,這裏的node節點也是通過node(index)獲取的,分別根據當前Node得到鏈表上的關節要素:element、next、prev,分別對 prev 和 next 進行判斷,以便對當前 list 的前後節點進行重新賦值,frist和last,最後將節點的element置爲null,個數-1,操作數+1。根據以上分析,remove節點關鍵的變量,是Node實例本身的局部變量 next、prev、item 重新構建內部變量指針指向,以及list的局部變量first和last保證節點相連。這些變量的操作使得其刪除動作也很高效。
而對於查詢:
/**
-
Returns the element at the specified position in this list.
-
@param index index of the element to return
-
@return the element at the specified position in this list
-
@throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
獲取指定index位置的node,獲取之前還是調用checkElementIndex(index)進行檢查元素,之後通過node(index)獲取元素,上文有提到,node的獲取是遍歷得到的元素,所以相對性能效率會低一些。
03
集合 3:Set
Set 集合在我們日常中,用到的也比較多。用於存儲不重複的元素集合,它主要提供下面幾種方法:
將元素添加進 Set<E> : add(E e)
將元素從 Set<E> 刪除: remove(Object e)
判斷是否包含元素: contains(Object e)
這幾種方法返回結果都是 boolean值,即返回是否正確或成功。Set 相當於只存儲key、不存儲value的Map。我們經常用 Set 用於去除重複元素,因爲 重複add同一個 key 時,會返回 false。
public HashSet() {
map = new HashMap<>();}
public TreeSet() {
this(new TreeMap<E,Object>());}
Set 子孫中主要有:HashSet、 SortedSet 。HashSet是無序的,因爲它實現了Set接口,並沒有實現SortedSet接口,而 TreeSet 實現了 SortedSet接口,從而保證元素是有序的 。
HashSet 添加後輸出也是無序的:
public class Test {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("2");
set.add("6");
set.add("44");
set.add("5");
for (String s : set) {
System.out.println(s);
}
}}
44
2
5
6
看到輸出的順序既不是添加的順序,也不是String排序的順序,在不同版本的JDK中,這個順序也可能是不同的。
換成TreeSet:
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("2");
set.add("6");
set.add("44");
set.add("5");
for (String s : set) {
System.out.println(s);
}}
2
44
5
6
在遍歷TreeSet時,輸出就是有序的,不是添加時的順序,而是 元素的排序順序。
注意:添加的元素必須實現Comparable接口,如果沒有實現Comparable接口,那麼創建TreeSet時必須傳入一個Comparator對象。