




MaxCompute基本概念
MaxCompute的核心概念主要包括:項目、表、分區、生命週期、資源、函數、任務、任務實例(實例)、ACID語義等。MaxComopute常用術語表參見:MaxCompute術語表。
項目(Project)
項目(Project)是MaxCompute的基本組織單元,它類似於傳統數據庫的Database或Schema的概念,是進行多用戶隔離和訪問控制的主要邊界。項目中包含多個對象,例如表(Table)、資源(Resource)、函數(Function)和實例(Instance)等。
一個用戶可以同時擁有多個項目的權限。通過安全授權,可以在一個項目中訪問另一個項目中的對象,詳情請參見基於Package的跨項目空間資源訪問。
可以通過use project命令進入一個項目,例如使用如下命令進入一個名爲my_project的項目,可以直接操作該項目下的對象,例如表、資源、函數和實例等。
--進入一個名爲my_project的項目空間。
use my_project;
表(Table)
表是MaxCompute的數據存儲單元。它在邏輯上是由行和列組成的二維結構,每行代表一條記錄,每列表示相同數據類型的一個字段,一條記錄可以包含一個或多個列,表的結構由各個列的名稱和類型構成。MaxCompute中不同類型計算任務的操作對象(輸入、輸出)都是表。可以創建表、刪除表以及導入數據到表或從表中導出數據。
MaxCompute的表格有兩種類型:內部表和外部表(MaxCompute2.0版本開始支持外部表)。
- 對於內部表,所有的數據都被存儲在MaxCompute中,表中列的數據類型可以是MaxCompute支持的任意一種數據類型。
- 對於外部表,MaxCompute並不真正持有數據,表格的數據可以存放在OSS或OTS中 。MaxCompute僅會記錄表格的Meta信息,您可以通過MaxCompute的外部表機制處理OSS或OTS上的非結構化數據,例如視頻、音頻、基因、氣象、地理信息等。
分區(Partitions)
分區表是指擁有分區空間的表,即在創建表時指定表內的一個或者某幾個字段作爲分區列。分區表實際就是對應分佈式文件系統上的獨立的文件夾,一個分區對應一個文件夾,文件夾下是對應分區所有的數據文件。
分區可以理解爲分類,通過分類把不同類型的數據放到不同的目錄下。分類的標準就是分區字段,可以是一個,也可以是多個。MaxCompute將分區列的每個值作爲一個分區(目錄),可以指定多級分區,即將表的多個字段作爲表的分區,分區之間類似多級目錄的關係。
分區表的意義在於優化查詢。查詢表時通過WHERE子句查詢指定所需查詢的分區,避免全表掃描,提高處理效率,降低計算費用。使用數據時,如果指定需要訪問的分區名稱,則只會讀取相應的分區。
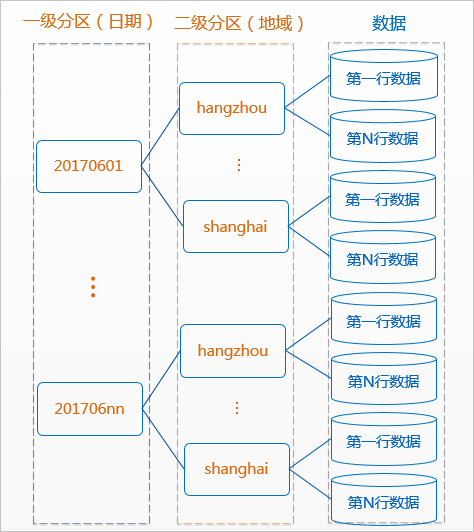
分區使用示例:
--創建一個二級分區表,以日期爲一級分區,地域爲二級分區
CREATE TABLE src (
key string,
value bigint
)
PARTITIONED BY (pt string, region string);
--正確使用方式。MaxCompute在生成查詢計劃時只會將'20170601'分區下region爲'hangzhou'二級分區的數據納入輸入中。
select * from src where pt='20170601'and region='hangzhou';
MaxCompute2.0數據類型版本支持的分區字段爲TINYINT、SMALLINT、INT、BIGINT、VARCHAR、STRING。
生命週期(Lifecycle)
MaxCompute表的生命週期(Lifecycle),指表(分區)數據從最後一次更新的時間算起,在經過指定的時間後沒有變動,則此表(分區)將被MaxCompute自動回收。這個指定的時間就是生命週期。
- 生命週期單位爲天,取值爲正整數。
- 對於非分區表,如果表數據在生命週期內沒有被修改,經過指定天數後此表將會被MaxCompute自動回收(類似DROP TABLE操作)。生命週期從最後一次表數據被修改的時間(LastDataModifiedTime)起開始計算。
- 對於分區表,每個分區可以分別被回收。在生命週期內未被修改數據的分區,經過指定的天數後此分區將會被回收,否則會被保留。每個分區的生命週期是從最後一次分區數據被修改的時間(LastDataModifiedTime)起開始計算。不同於非分區表,分區表的最後一個分區被回收後,該表不會被刪除。
- 生命週期主要提供定期回收表或分區的功能,每天根據服務的繁忙程度,不定時回收。不能確保表或分區的生命週期到期後,立刻被回收。
- 只能在表級別設置生命週期,不能在分區級設置生命週期。爲分區表指定的生命週期,適用於該表所有的分區。創建表時即可指定生命週期。
- 如果沒有爲表指定生命週期,則表(分區)不會根據生命週期規則被MaxCompute自動回收。
資源(Resource)
資源(Resource)是MaxCompute的特有概念,MaxCompute的UDF和MapReduce功能需要依賴資源來完成,如下所示:
- SQL UDF:編寫UDF後,需要將編譯好的Jar包以資源的形式上傳到MaxCompute。運行此UDF時,MaxCompute會自動下載這個Jar包,獲取代碼來運行UDF。上傳Jar包的過程就是在MaxCompute上創建資源的過程,這個Jar包是MaxCompute資源的一種。
- MapReduce:編寫MapReduce程序後,將編譯好的Jar包作爲一種資源上傳到MaxCompute。運行MapReduce作業時,MapReduce框架會自動下載這個Jar資源獲取代碼。同樣可以將文本文件以及MaxCompute中的表作爲不同類型的資源上傳到MaxCompute,在UDF及MapReduce的運行過程中讀取、使用這些資源。
MaxCompute支持上傳的單個資源大小上限爲500MB,資源包括以下幾種類型:
- File類型。
- Table類型:MaxCompute中的表。MapReduce引用的table類型資源中,table字段類型目前只支持BIGINT、DOUBLE、STRING、DATETIME、BOOLEAN,其他類型暫未支持。
- Jar類型:編譯好的Java Jar包。
- Archive類型:通過資源名稱中的後綴識別壓縮類型,支持的壓縮文件類型包括.zip/.tgz/.tar.gz/.tar/jar。
函數(Function)
MaxCompute您提供了SQL計算功能,可以在MaxCompute SQL中使用系統的內建函數完成一定的計算和計數功能。但當內建函數無法滿足要求時,可以使用MaxCompute提供的Java編程接口開發自定義函數(User Defined Function,以下簡稱UDF)。
自定義函數(UDF)可以進一步分爲標量值函數(UDF),自定義聚合函數(UDAF)和自定義表值函數(UDTF)三種類型。
使用步驟:在開發完成UDF代碼後,需要將代碼編譯成Jar包,並將此Jar包以Jar資源的形式上傳到MaxCompute,最後在MaxCompute中註冊此UDF。具體可見:MaxCompute數據開發快速入門。
任務(Task)
任務(Task)是MaxCompute的基本計算單元,SQL及MapReduce功能都是通過任務完成的。
對於提交的大多數任務,特別是計算型任務,例如SQL DML語句,MapReduce,MaxCompute會對其進行解析,得到任務的執行計劃。執行計劃由具有依賴關係的多個執行階段(Stage)構成。
目前,執行計劃邏輯上可以被看做一個有向圖,圖中的點是執行階段,各個執行階段的依賴關係是圖的邊。MaxCompute會依照圖(執行計劃)中的依賴關係執行各個階段。在同一個執行階段內,會有多個進程,也稱之爲Worker,共同完成該執行階段的計算工作。同一個執行階段的不同Worker只是處理的數據不同,執行邏輯完全相同。計算型任務在執行時,會被實例化,您可以對這個實例(Instance)進行操作,例如獲取實例狀態(Status Instance)、終止實例運行(Kill Instance)等。
部分MaxCompute任務並不是計算型的任務,例如SQL中的DDL語句,這些任務本質上僅需要讀取、修改MaxCompute中的元數據信息。因此,這些任務無法被解析出執行計劃。
任務實例
在MaxCompute中,部分Task在執行時會被實例化,以MaxCompute實例(下文簡稱爲實例或Instance)的形式存在。實例會經歷運行(Running)和結束(Terminated)兩個階段。
運行階段的實例狀態爲Running(運行中),而結束階段則會有Success(成功)、Failed(失敗)和Canceled(被取消)三種狀態。可以根據運行任務時MaxCompute給出的實例ID進行查詢、改變任務的狀態等操作,示例如下。
--查看某實例的狀態。
status instance_id;
--停止某實例,將其狀態設置爲Canceled。
kill instance_id;
--查看某實例的運行日誌。
wait instance_id;
MaxCompute數據類型
數據類型版本
MaxCompute 2.0推出之後,MaxCompute中包含的數據類型版本存在三個:
- MaxCompute 1.0數據類型
- MaxCompute 2.0數據類型
- MaxCompute兼容Hive數據類型
MaxCompute設置數據類型版本屬性的參數共有3個:
- odps.sql.type.system.odps2:MaxCompute 2.0數據類型版本的開關,屬性值爲True和False。
- odps.sql.decimal.odps2:MaxCompute 2.0的Decimal數據類型的開關,屬性值爲True和False。
- odps.sql.hive.compatible:MaxCompute Hive兼容模式(即部分數據類型和SQL行爲兼容Hive)數據類型版本的開關,屬性值爲True和False。
在新增項目時MaxCompute可以對3個版本的數據類型進行選擇,各個版本默認設置如下:
1. MaxCompute 1.0數據類型版本
setproject odps.sql.type.system.odps2=false;--關閉MaxCompute 2.0數據類型。
setproject odps.sql.decimal.odps2=false;--關閉Decimal 2.0數據類型。
setproject odps.sql.hive.compatible=false;--關閉Hive兼容模式。
適用於早期使用的MaxCompute項目,且該項目依賴的產品組件不支持2.0數據類型版本。
2. MaxCompute 2.0數據類型版本
setproject odps.sql.type.system.odps2=true;--打開MaxCompute 2.0數據類型。
setproject odps.sql.decimal.odps2=true;--打開Decimal 2.0數據類型。
setproject odps.sql.hive.compatible=false;--關閉Hive兼容模式。
適用於在2020年04月之前無存量數據的MaxCompute項目,且該項目依賴的產品組件支持2.0數據類型版本。
查看和修改數據類型
--查看項目數據類型版本。
setproject;
--開啓/關閉MaxCompute2.0數據類型版本。
setproject odps.sql.type.system.odps2=true/false;
--開啓/關閉decimal2.0數據類型。
setproject odps.sql.decimal.odps2=true/false;
--開啓/關閉hive兼容模式數據類型版本。
setproject odps.sql.hive.compatible=true/false;
MaxCompute 1.0數據類型
| 類型 | 常量示例 | 描述 |
|---|---|---|
| BIGINT | 100000000000L、-1L | 64位有符號整型。
取值範圍:-2 63 +1~2 63 -1。 |
| DOUBLE | 3.1415926 1E+7 | 64位二進制浮點型。 |
| DECIMAL | 3.5BD、99999999999.9999999BD | 10進制精確數字類型。
整型部分取值範圍:-10 36 +1~10 36 -1, 小數部分精確到10 -18 。固定54位數字,其中整數部分36位,小數位爲18位。 |
| STRING | “abc”、’bcd’、”alibaba”、‘inc’ | 字符串類型,目前長度限制爲8MB。 |
| DATETIME | DATETIME ‘2017-11-11 00:00:00’ | 日期時間類型。
取值範圍:0000年1月1日~9999年12月31日,精確到毫秒。 |
| BOOLEAN | True、False | BOOLEAN類型。
取值範圍:True、False。 |
對於上述數據類型說明如下:
- 上述的各種數據類型均可爲NULL。
- 整型常量的語義默認爲BIGINT類型。如果常量過長,超過了BIGINT的值域(例如1,000,000,000,000,000,000,000,000)則會被作爲DOUBLE類型處理。例如
SELECT 1 + a;中的整型常量1會被作爲BIGINT類型處理。 - 參數涉及2.0數據類型的內置函數,在1.0數據類型版本下無法正常使用。
- 分區表的分區列的數據類型只支持STRING類型。
MaxCompute 2.0數據類型
| 類型 | 常量示例 | 描述 |
|---|---|---|
| TINYINT | 1Y、-127Y | 8位有符號整型。
取值範圍:-128~127。 |
| SMALLINT | 32767S、-100S | 16位有符號整型。
取值範圍:-32768~32767。 |
| INT | 1000、-15645787 | 32位有符號整型。
取值範圍:-2 31 ~2 31 -1。 |
| BIGINT | 100000000000L、-1L | 64位有符號整型。
取值範圍:-2 63 +1~2 63 -1。 |
| BINARY | 無 | 二進制數據類型,目前長度限制爲8MB。 |
| FLOAT | 無 | 32位二進制浮點型。 |
| DOUBLE | 3.1415926 1E+7 | 64位二進制浮點型。 |
| DECIMAL(precision, scale) | 3.5BD、99999999999.9999999BD | 10進制精確數字類型。
如果不指定以上兩個參數,則默認爲 |
| VARCHAR(n) | 無 | 變長字符類型,n爲長度。
取值範圍:1~65535。 |
| CHAR(n) | 無 | 固定長度字符類型,n爲長度。最大取值255。長度不足則會填充空格,但空格不參與比較。 |
| STRING | “abc”、’bcd’、”alibaba”、‘inc’ | 字符串類型,目前長度限制爲8MB。 |
| DATE | DATE'2017-11-11' | 日期類型,格式爲yyyy-mm-dd。
取值範圍:0000-01-01~9999-12-31。 |
| DATETIME | DATETIME ‘2017-11-11 00:00:00’ | 日期時間類型。
取值範圍:0000-01-01 00:00:00.000~9999-12-31 23.59:59.999,精確到毫秒。 |
| TIMESTAMP | TIMESTAMP ‘2017-11-11 00:00:00.123456789’ | 與時區無關的時間戳類型。
取值範圍:0000-01-01 00:00:00.000000000~9999-12-3123.59:59.999999999,精確到納秒。 說明 對於部分時區相關的函數,例如 |
| BOOLEAN | True、False | BOOLEAN類型。
取值範圍:True、False。 |
支持的複雜數據類型:
| 類型 | 定義方法 | 構造方法 |
|---|---|---|
| ARRAY |
|
|
| MAP |
|
|
| STRUCT |
|
|
以上數據類型的具體說明,以及MaxCompute各類數據類型的區別,詳見:MaxCompute 2.0數據類型。
Hive兼容數據類型
Hive兼容數據類型版本支持的基礎數據類型與2.0數據類型定義基本一致,只有Decimal數據類型在兩個版本下有些差異。具體見:Hive兼容數據類型版本。