




上一節,我們介紹了Spring Boot在JDBC模塊中自動化配置使用的默認數據源HikariCP。接下來這一節,我們將介紹另外一個被廣泛應用的開源數據源:Druid。
Druid是由阿里巴巴數據庫事業部出品的開源項目。它除了是一個高性能數據庫連接池之外,更是一個自帶監控的數據庫連接池。雖然HikariCP已經很優秀,但是對於國內用戶來說,可能對於Druid更爲熟悉。所以,對於如何在Spring Boot中使用Druid是後端開發人員必須要掌握的基本技能。
配置Druid數據源
這一節的實踐我們將基於《Spring Boot 2.x基礎教程:使用JdbcTemplate訪問MySQL數據庫》一文的代碼基礎上進行。所以,讀者可以從文末的代碼倉庫中,檢出chapter3-1目錄來進行下面的實踐學習。
下面我們就來開始對Spring Boot項目配置Druid數據源:
第一步:在pom.xml中引入druid官方提供的Spring Boot Starter封裝。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
|
第二步:在application.properties中配置數據庫連接信息。
Druid的配置都以spring.datasource.druid作爲前綴,所以根據之前的配置,稍作修改即可:
spring.datasource.druid.url=jdbc:mysql://localhost:3306/test spring.datasource.druid.username=root spring.datasource.druid.password= spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver |
第三步:配置Druid的連接池。
與Hikari一樣,要用好一個數據源,就要對其連接池做好相應的配置,比如下面這樣:
spring.datasource.druid.initialSize=10 spring.datasource.druid.maxActive=20 spring.datasource.druid.maxWait=60000 spring.datasource.druid.minIdle=1 spring.datasource.druid.timeBetweenEvictionRunsMillis=60000 spring.datasource.druid.minEvictableIdleTimeMillis=300000 spring.datasource.druid.testWhileIdle=true spring.datasource.druid.testOnBorrow=true spring.datasource.druid.testOnReturn=false spring.datasource.druid.poolPreparedStatements=true spring.datasource.druid.maxOpenPreparedStatements=20 spring.datasource.druid.validationQuery=SELECT 1 spring.datasource.druid.validation-query-timeout=500 spring.datasource.druid.filters=stat |
關於Druid中各連接池配置的說明可查閱下面的表格:
| 配置 | 缺省值 | 說明 |
|---|---|---|
| name | 配置這個屬性的意義在於,如果存在多個數據源,監控的時候可以通過名字來區分開來。如果沒有配置,將會生成一個名字,格式是:”DataSource-“ + System.identityHashCode(this). 另外配置此屬性至少在1.0.5版本中是不起作用的,強行設置name會出錯。詳情-點此處。 | |
| url | 連接數據庫的url,不同數據庫不一樣。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto | |
| username | 連接數據庫的用戶名 | |
| password | 連接數據庫的密碼。如果你不希望密碼直接寫在配置文件中,可以使用ConfigFilter。詳細看這裏 | |
| driverClassName | 根據url自動識別 | 這一項可配可不配,如果不配置druid會根據url自動識別dbType,然後選擇相應的driverClassName |
| initialSize | 0 | 初始化時建立物理連接的個數。初始化發生在顯示調用init方法,或者第一次getConnection時 |
| maxActive | 8 | 最大連接池數量 |
| maxIdle | 8 | 已經不再使用,配置了也沒效果 |
| minIdle | 最小連接池數量 | |
| maxWait | 獲取連接時最大等待時間,單位毫秒。配置了maxWait之後,缺省啓用公平鎖,併發效率會有所下降,如果需要可以通過配置useUnfairLock屬性爲true使用非公平鎖。 | |
| poolPreparedStatements | false | 是否緩存preparedStatement,也就是PSCache。PSCache對支持遊標的數據庫性能提升巨大,比如說oracle。在mysql下建議關閉。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要啓用PSCache,必須配置大於0,當大於0時,poolPreparedStatements自動觸發修改爲true。在Druid中,不會存在Oracle下PSCache佔用內存過多的問題,可以把這個數值配置大一些,比如說100 |
| validationQuery | 用來檢測連接是否有效的sql,要求是一個查詢語句,常用select ‘x’。如果validationQuery爲null,testOnBorrow、testOnReturn、testWhileIdle都不會起作用。 | |
| validationQueryTimeout | 單位:秒,檢測連接是否有效的超時時間。底層調用jdbc Statement對象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。 |
| testOnReturn | false | 歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。 |
| testWhileIdle | false | 建議配置爲true,不影響性能,並且保證安全性。申請連接的時候檢測,如果空閒時間大於timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效。 |
| keepAlive | false (1.0.28) | 連接池中的minIdle數量以內的連接,空閒時間超過minEvictableIdleTimeMillis,則會執行keepAlive操作。 |
| timeBetweenEvictionRunsMillis | 1分鐘(1.0.14) | 有兩個含義: 1) Destroy線程會檢測連接的間隔時間,如果連接空閒時間大於等於minEvictableIdleTimeMillis則關閉物理連接。 2) testWhileIdle的判斷依據,詳細看testWhileIdle屬性的說明 |
| numTestsPerEvictionRun | 30分鐘(1.0.14) | 不再使用,一個DruidDataSource只支持一個EvictionRun |
| minEvictableIdleTimeMillis | 連接保持空閒而不被驅逐的最小時間 | |
| connectionInitSqls | 物理連接初始化的時候執行的sql | |
| exceptionSorter | 根據dbType自動識別 | 當數據庫拋出一些不可恢復的異常時,拋棄連接 |
| filters | 屬性類型是字符串,通過別名的方式配置擴展插件,常用的插件有: 監控統計用的filter:stat 日誌用的filter:log4j 防禦sql注入的filter:wall | |
| proxyFilters | 類型是List<com.alibaba.druid.filter.Filter>,如果同時配置了filters和proxyFilters,是組合關係,並非替換關係 |
到這一步,就已經完成了將Spring Boot的默認數據源HikariCP切換到Druid的所有操作。
配置Druid監控
既然用了Druid,那麼對於Druid的監控功能怎麼能不用一下呢?下面就來再進一步做一些配置,來啓用Druid的監控。
第一步:在pom.xml中引入spring-boot-starter-actuator模塊
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
|
第二步:在application.properties中添加Druid的監控配置。
spring.datasource.druid.stat-view-servlet.enabled=true spring.datasource.druid.stat-view-servlet.url-pattern=/druid/* spring.datasource.druid.stat-view-servlet.reset-enable=true spring.datasource.druid.stat-view-servlet.login-username=admin spring.datasource.druid.stat-view-servlet.login-password=admin |
上面的配置主要用於開啓stat監控統計的界面以及監控內容的相關配置,具體釋意如下:
spring.datasource.druid.stat-view-servlet.url-pattern:訪問地址規則spring.datasource.druid.stat-view-servlet.reset-enable:是否允許清空統計數據spring.datasource.druid.stat-view-servlet.login-username:監控頁面的登錄賬戶spring.datasource.druid.stat-view-servlet.login-password:監控頁面的登錄密碼
第三步:針對之前實現的UserService內容,我們創建一個Controller來通過接口去調用數據訪問操作:
@Data
@AllArgsConstructor
@RestController
public class UserController {
private UserService userService;
@PostMapping("/user")
public int create(@RequestBody User user) {
return userService.create(user.getName(), user.getAge());
}
@GetMapping("/user/{name}")
public List<User> getByName(@PathVariable String name) {
return userService.getByName(name);
}
@DeleteMapping("/user/{name}")
public int deleteByName(@PathVariable String name) {
return userService.deleteByName(name);
}
@GetMapping("/user/count")
public int getAllUsers() {
return userService.getAllUsers();
}
@DeleteMapping("/user/all")
public int deleteAllUsers() {
return userService.deleteAllUsers();
}
}
|
第四步:完成上面所有配置之後,啓動應用,訪問Druid的監控頁面http://localhost:8080/druid/,可以看到如下登錄頁面:
輸入上面spring.datasource.druid.stat-view-servlet.login-username和spring.datasource.druid.stat-view-servlet.login-password配置的登錄賬戶與密碼,就能看到如下監控頁面:
進入到這邊時候,就可以看到對於應用端而言的各種監控數據了。這裏講解幾個最爲常用的監控頁面:
數據源:這裏可以看到之前我們配置的數據庫連接池信息以及當前使用情況的各種指標。
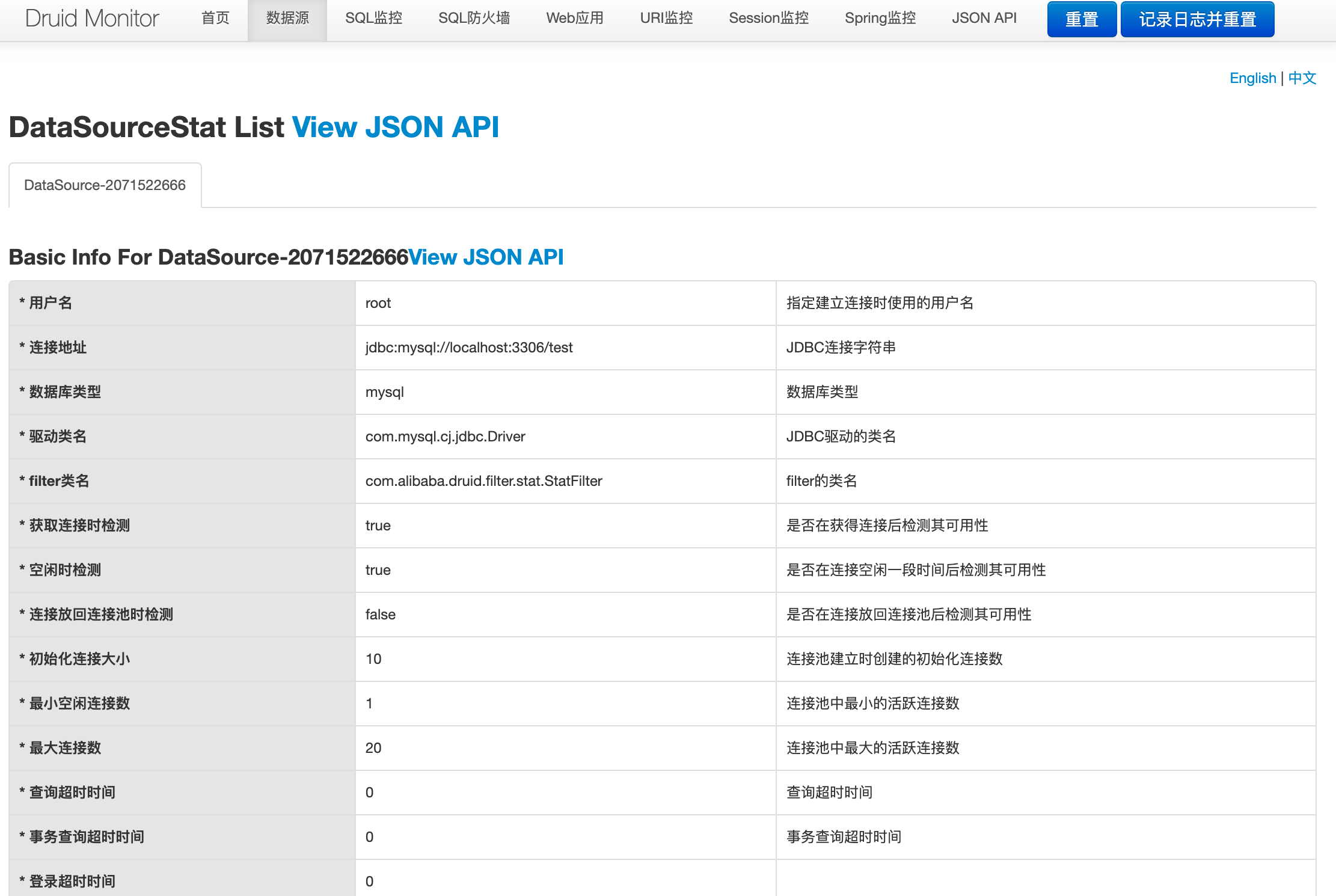
SQL監控:該數據源中執行的SQL語句極其統計數據。在這個頁面上,我們可以很方便的看到當前這個Spring Boot都執行過哪些SQL,這些SQL的執行頻率和執行效率也都可以清晰的看到。如果你這裏沒看到什麼數據?別忘了我們之前創建了一個Controller,用這些接口可以觸發UserService對數據庫的操作。所以,這裏我們可以通過調用接口的方式去觸發一些操作,這樣SQL監控頁面就會產生一些數據:
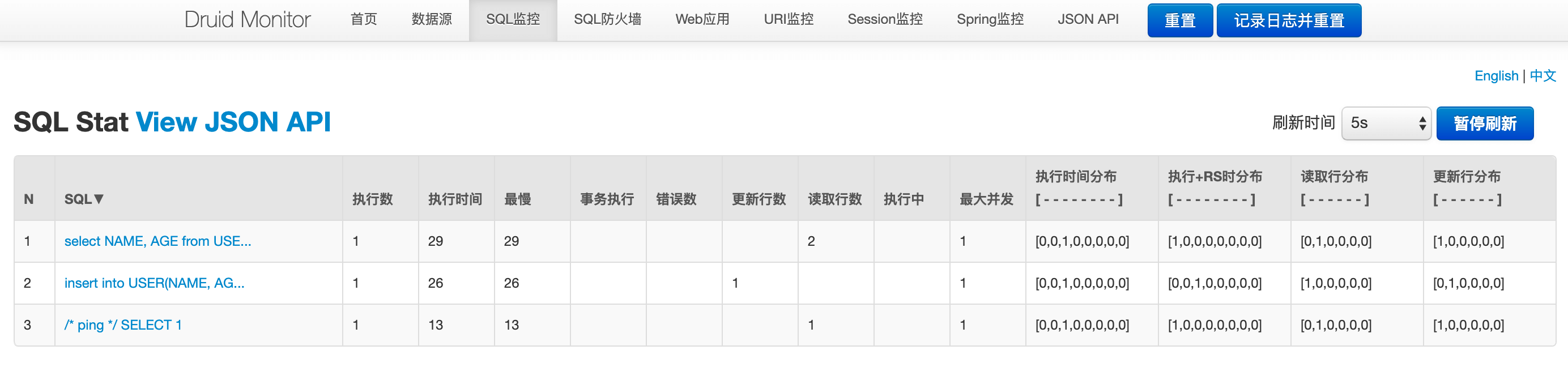
圖中監控項上,執行時間、讀取行數、更新行數都通過區間分佈的方式表示,將耗時分佈成8個區間:
- 0 - 1 耗時0到1毫秒的次數
- 1 - 10 耗時1到10毫秒的次數
- 10 - 100 耗時10到100毫秒的次數
- 100 - 1,000 耗時100到1000毫秒的次數
- 1,000 - 10,000 耗時1到10秒的次數
- 10,000 - 100,000 耗時10到100秒的次數
- 100,000 - 1,000,000 耗時100到1000秒的次數
- 1,000,000 - 耗時1000秒以上的次數
記錄耗時區間的發生次數,通過區分分佈,可以很方便看出SQL運行的極好、普通和極差的分佈。 耗時區分分佈提供了“執行+RS時分佈”,是將執行時間+ResultSet持有時間合併監控,這個能方便診斷返回行數過多的查詢。
SQL防火牆:該頁面記錄了與SQL監控不同維度的監控數據,更多用於對錶訪問維度、SQL防禦維度的統計。
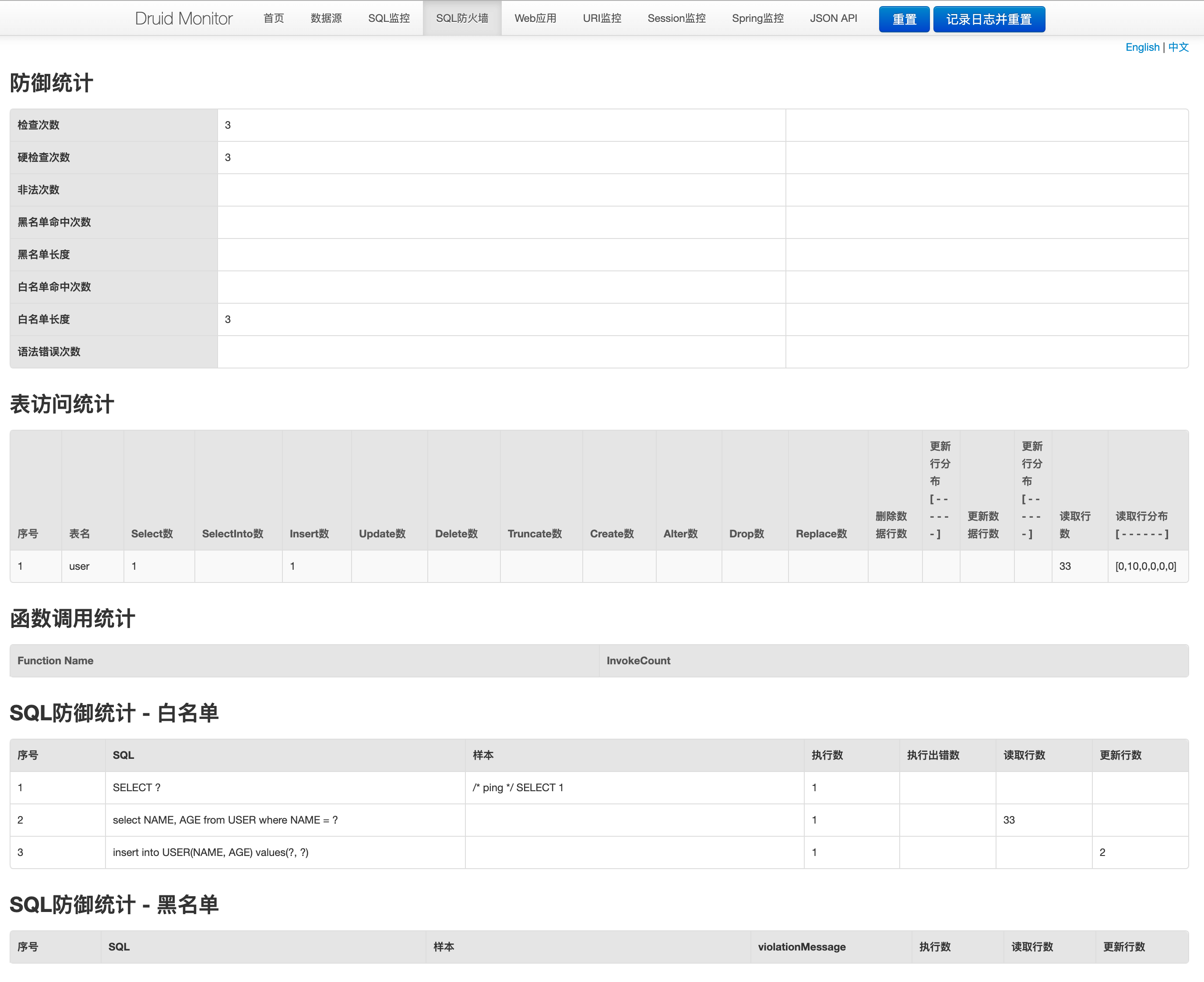
該功能數據記錄的統計需要在spring.datasource.druid.filters中增加wall屬性纔會進行記錄統計,比如這樣:
spring.datasource.druid.filters=stat,wall |
注意:這裏的所有監控信息是對這個應用實例的數據源而言的,而並不是數據庫全局層面的,可以視爲應用層的監控,不可能作爲中間件層的監控。
代碼示例
本文的相關例子可以查看下面倉庫中的chapter3-3目錄: