




原文 : DotNetAnywhere: An Alternative .NET Runtime
作者 : Matt Warren
譯者 : 張很水
我最近在收聽一個名爲 DotNetRock 的優質播客,其中有以 Knockout.js 而聞名的 Steven Sanderson 正在討論 " WebAssembly And Blazor "。
也許你還沒聽過, Blazor 正試圖憑藉 WebAssembly 的魔力將 .NET 帶入到瀏覽器中。如果您想了解更多信息,Scott Hanselmen 已經在 " .NET和WebAssembly——這會是前端的未來嗎? "一文中做了一番介紹。( 點擊查看該文的 翻譯 )。
儘管 WebAssembly 非常酷炫,然而更讓我感興趣的是 Blazor 如何使用 DotNetAnywhere 作爲底層的 .NET 運行時。本文將討論DotNetAnywhere 是什麼,能做什麼,以及同完整的 .NET Framework 做比較。
DotNetAnywhere
首先值得指出的是,DotNetAnywhere (DNA) 被設計爲一個完全兼容的 .NET 運行時,可以運行被完整的.NET 框架編譯的 dll 和 exe 。除此之外 (至少在理論上) 支持 以下的 .NET 運行時的功能,真是令人激動!
- 泛型
- 垃圾收集和析構
- 弱引用
- 完整的異常處理 - try/catch/finally
- PInvoke
- 接口
- 委託
- 事件
- 可空類型
- 一維數組
- 多線程
另外對於 反射 提供部分支持
- 非常有限的只讀方法
typeof(), GetType(), Type.Name, Type.Namespace, Type.IsEnum(),
最後,還有一些目前不支持的功能:
- 屬性
- 大部分的反射方法
- 多維數組
- Unsafe 代碼
各種各樣的錯誤或缺少的功能 可能會讓代碼無法在 DotNetAnywhere下運行,但其中一些已經被 Blazor 修復 ,所以值得時不時檢查 Blazor 的發佈版本。
如今,DotNetAnywhere 的原始倉庫 不再活躍 (最後一個持續的活動是在2012年1月),所以未來任何的開發或錯誤修復都可能在 Blazor 的倉庫中執行。如果你曾經在 DotNetAnywhere 中修復過某些東西,可以考慮在那裏發一個PR。
更新:還有其他版本的各種錯誤修復和增強:
源代碼概覽
我覺得 DotNetAnywhere 運行時最令人印象深刻的一點是 只由一個人開發,並且 只用了 40,000 行代碼!反觀,完整的 .NET 框架僅是垃圾收集器就 有將近37000 行代碼 ( 更多信息請我之前發佈的 CoreCLR 源代碼漫遊指南 )。
機器碼 - 共 17,710 行
| LOC | File |
|---|---|
| 3,164 | JIT_Execute.c |
| 1,778 | JIT.c |
| 1,109 | PInvoke_CaseCode.h |
| 630 | Heap.c |
| 618 | MetaData.c |
| 563 | MetaDataTables.h |
| 517 | Type.c |
| 491 | MetaData_Fill.c |
| 467 | MetaData_Search.c |
| 452 | JIT_OpCodes.h |
託管代碼 - 共 28,783 行
關鍵組件
接下來,讓我們看一下 DotNetAnywhere 中的關鍵組件,正是我們瞭解怎麼兼容 .NET 運行時的好辦法。同樣我們也能看到它與微軟 .NET Framework 的差異。
加載 .NET dll
DotNetAnywhere 所要做的第一件事就是加載、解析包含在 .dll 或者.exe 中的 元數據和代碼。這一切都存放在 MetaData.c 中,主要是在 LoadSingleTable(..) 函數中。通過添加一些調試代碼,我能夠從一般的 .NET dll 中獲取所有類型的 元數據 摘要,這是一個非常有趣的列表:
MetaData contains 1 Assemblies (MD_TABLE_ASSEMBLY)
MetaData contains 1 Assembly References (MD_TABLE_ASSEMBLYREF)
MetaData contains 0 Module References (MD_TABLE_MODULEREF)
MetaData contains 40 Type References (MD_TABLE_TYPEREF)
MetaData contains 13 Type Definitions (MD_TABLE_TYPEDEF)
MetaData contains 14 Type Specifications (MD_TABLE_TYPESPEC)
MetaData contains 5 Nested Classes (MD_TABLE_NESTEDCLASS)
MetaData contains 11 Field Definitions (MD_TABLE_FIELDDEF)
MetaData contains 0 Field RVA's (MD_TABLE_FIELDRVA)
MetaData contains 2 Propeties (MD_TABLE_PROPERTY)
MetaData contains 59 Member References (MD_TABLE_MEMBERREF)
MetaData contains 2 Constants (MD_TABLE_CONSTANT)
MetaData contains 35 Method Definitions (MD_TABLE_METHODDEF)
MetaData contains 5 Method Specifications (MD_TABLE_METHODSPEC)
MetaData contains 4 Method Semantics (MD_TABLE_PROPERTY)
MetaData contains 0 Method Implementations (MD_TABLE_METHODIMPL)
MetaData contains 22 Parameters (MD_TABLE_PARAM)
MetaData contains 2 Interface Implementations (MD_TABLE_INTERFACEIMPL)
MetaData contains 0 Implementation Maps? (MD_TABLE_IMPLMAP)
MetaData contains 2 Generic Parameters (MD_TABLE_GENERICPARAM)
MetaData contains 1 Generic Parameter Constraints (MD_TABLE_GENERICPARAMCONSTRAINT)
MetaData contains 22 Custom Attributes (MD_TABLE_CUSTOMATTRIBUTE)
MetaData contains 0 Security Info Items? (MD_TABLE_DECLSECURITY)
更多關於 元數據 的資料請參閱 介紹 CLR 元數據,解析.NET 程序集—–關於 PE 頭文件 和 ECMA 標準 等文章。
執行 .NET IL
DotNetAnywhere 的另一大功能是 "即時編譯器" (JIT),即執行 IL 的代碼,從 JIT_Execute.c 和 JIT.c 中開始執行。在 JITit(..) 函數 的主入口中 "執行循環",其中最令人印象深刻的是在一個 1,374 行代碼的 switch 中就有 200 多個 case !!
從更高的層面看,它所經歷的整個過程如下所示:
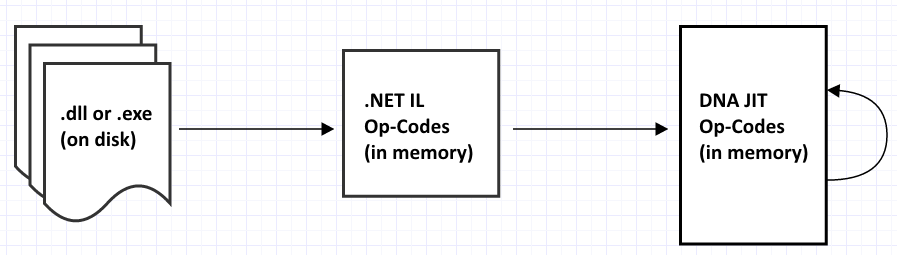{kind=link}

與定義在 CIL_OpCodes.h (CIL_XXX) .NET IL 操作碼 ( Op-Codes) 不同,DotNetAnywhere JIT 操作碼 (Op-Codes) 是定義在 JIT_OpCodes.h (JIT_XXX)中。
有趣的是這部分 JIT 代碼是 DotNetAnywhere 中唯一一處 使用匯編編寫 ,並且只是 win32 。 它允許使用 jump 或者 goto 在 C 源碼中跳轉標籤,所以當 IL 指令被執行時,實際上並不會離開 JITit(..) 函數,控制(流程)只是從一處移動到別處,不必進行完整的方法調用。
#ifdef __GNUC__
#define GET_LABEL(var, label) var = &&label
#define GO_NEXT() goto **(void**)(pCurOp++)
#else
#ifdef WIN32
#define GET_LABEL(var, label) \
{ __asm mov edi, label \
__asm mov var, edi }
#define GO_NEXT() \
{ __asm mov edi, pCurOp \
__asm add edi, 4 \
__asm mov pCurOp, edi \
__asm jmp DWORD PTR [edi - 4] }
#endif
IL 差異
在完整的 .NET framework 中,所有的 IL 代碼在被 CPU 執行之前都是由 Just-in-Time Compiler (JIT) 轉換爲機器碼。
如你所見, DotNetAnywhere "解釋" (interprets) IL時是逐條執行指令,甚至會調用 JIT.c 文件來完成。 沒有機器碼 被反射發出 (emitted) ,所以這個命名還是有點奇怪!?
或許這只是一個差異,但實在是無法讓我搞清楚它是如何進行 "解釋" (interpreting) 代碼和 "即時編譯" (JITting),即使我再閱讀完下面的文章還是不得其解!! (有人能指教一下嗎?)
- 即時編譯器和解釋器有什麼區別?
- 瞭解傳統的解釋器、JIT 編譯器、JIT 解釋器 和 AOT 編譯器 的不同之處
- JIT vs Interpreters
- 爲什麼我們將 Java 字節碼轉換爲機器碼的東西稱爲 “JIT編譯器” 而不是 “JIT解釋器” ?
- 瞭解 JIT 編譯和優化
垃圾回收
所有關於 DotNetAnywhere 的垃圾回收(GC) 代碼都在 Heap.c 中,而且還是 600 行易於閱讀的代碼。給你一個概覽吧,下面是它暴露的函數列表:
void Heap_Init();
void Heap_SetRoots(tHeapRoots *pHeapRoots, void *pRoots, U32 sizeInBytes);
void Heap_UnmarkFinalizer(HEAP_PTR heapPtr);
void Heap_GarbageCollect();
U32 Heap_NumCollections();
U32 Heap_GetTotalMemory();
HEAP_PTR Heap_Alloc(tMD_TypeDef *pTypeDef, U32 size);
HEAP_PTR Heap_AllocType(tMD_TypeDef *pTypeDef);
void Heap_MakeUndeletable(HEAP_PTR heapEntry);
void Heap_MakeDeletable(HEAP_PTR heapEntry);
tMD_TypeDef* Heap_GetType(HEAP_PTR heapEntry);
HEAP_PTR Heap_Box(tMD_TypeDef *pType, PTR pMem);
HEAP_PTR Heap_Clone(HEAP_PTR obj);
U32 Heap_SyncTryEnter(HEAP_PTR obj);
U32 Heap_SyncExit(HEAP_PTR obj);
HEAP_PTR Heap_SetWeakRefTarget(HEAP_PTR target, HEAP_PTR weakRef);
HEAP_PTR* Heap_GetWeakRefAddress(HEAP_PTR target);
void Heap_RemovedWeakRefTarget(HEAP_PTR target);
GC 差異
就像我們對比 JIT/Interpreter 一樣, 在 GC 上的差異同樣可見。
Conservative GC
首先,DotNetAnywhere 的 GC 是 Conservative GC 。簡單地說,這意味着它不知道 (或者說肯定) 內存的哪些區域是對象的引用/指針,還是一個隨機數 (看起來像內存地址)。而在.NET Framework 中 JIT 收集這些信息並存在 GCInfo structure 中,所以它的 GC 可以有效利用,而 DotNetAnywhere 是做不到。
相反, 在 標記(Mark) 的階段,GC 獲取所有可用的 " 根 (roots) ", 將一個對象中的所有內存地址視爲 "潛在的" 引用(因此說它是 "conservative")。然後它必須查找每個可能的引用,看看它是否真的指向 "對象的引用"。通過跟蹤 平衡二叉搜索樹 (按內存地址排序) 來執行操作, 流程如下所示:

但是,這意味着所有的對象引用在分配時都必須存儲在二叉樹中,這會增加分配的開銷。另外還需要額外的內存,每個堆多佔用 20 個字節。我們看看 tHeapEntry 的數據結構 (所有的指針佔用 4 字節, U8 等於 1 字節,而 padding 可忽略不計), tHeapEntry *pLink[2] 是啓用二叉樹查找所需的額外數據。
struct tHeapEntry_ {
// Left/right links in the heap binary tree
tHeapEntry *pLink[2];
// The 'level' of this node. Leaf nodes have lowest level
U8 level;
// Used to mark that this node is still in use.
// If this is set to 0xff, then this heap entry is undeletable.
U8 marked;
// Set to 1 if the Finalizer needs to be run.
// Set to 2 if this has been added to the Finalizer queue
// Set to 0 when the Finalizer has been run (or there is no Finalizer in the first place)
// Only set on types that have a Finalizer
U8 needToFinalize;
// unused
U8 padding;
// The type in this heap entry
tMD_TypeDef *pTypeDef;
// Used for locking sync, and tracking WeakReference that point to this object
tSync *pSync;
// The user memory
U8 memory[0];
};
爲什麼 DotNetAnywhere 這樣做呢? DotNetAnywhere的作者 Chris Bacon 是這樣 解釋:
告訴你吧,整個堆代碼確實需要重寫,減少每個對象的內存開銷,並且不需要分配二叉樹。一開始設計 GC 時沒有考慮那麼多,(現在做的話)會增加很多代碼。這是我一直想做的事情,但從來沒有動手。爲了儘快使用 GC 而只好如此。 在最初的設計中完全沒有 GC。它的速度非常快,以至於內存也會很快用完。
更多 "Conservative" 機制和 "Precise" GC機制的細節請看:
GC 只做了 "標記-掃描", 不會做壓縮
在 GC 方面另一個不同的行爲是它不會在回收後做任何內存 壓縮 ,正如 Steve Sanderson 在 working on Blazor 中所說:
- 在服務器端執行期間,我們實際上並不需要任何內存固定 (pin),在客戶端執行過程中並沒有任何互操作,所有的東西(實際上)都是固定的。因爲 DotNetAnywhere 的 GC只做標記掃描,沒有任何壓縮階段。
此外,當一個對象被分配給 DotNetAnywhere 時,只是調用了 malloc(), 它的代碼細節在 Heap_Alloc(..) 函數 中。所以它也沒有 "Generations" 或者 "Segments" 的概念,你在 .NET Framework GC 中見到的如 "Gen 0"、"Gen 1" 或者 "大對象堆" 等都不會出現。
線程模型
最後,我們來看看線程模型,它與 .NET Framework 中的線程模型截然不同。
線程差異
DotNetAnywhere (表面上)樂於爲你創建線程並執行代碼, 然而這只是一種幻覺. 事實上它只會跑在 一個線程 中, 不同的線程之間 切換上下文:

你可以通過下面的代碼瞭解, ( 引用自 Thread_Execute() 函數 )將 numInst 設置爲 100 並傳入 JIT_Execute(..) 中:
for (;;) {
U32 minSleepTime = 0xffffffff;
I32 threadExitValue;
status = JIT_Execute(pThread, 100);
switch (status) {
....
}
}
一個有趣的副作用是 DotNetAnywhere 中corlib 的實現代碼將變得非常簡單。如Interlocked.CompareExchange() 函數 的 內部實現 所示, 你所期待的同步就缺失了:
tAsyncCall* System_Threading_Interlocked_CompareExchange_Int32(
PTR pThis_, PTR pParams, PTR pReturnValue) {
U32 *pLoc = INTERNALCALL_PARAM(0, U32*);
U32 value = INTERNALCALL_PARAM(4, U32);
U32 comparand = INTERNALCALL_PARAM(8, U32);
*(U32*)pReturnValue = *pLoc;
if (*pLoc == comparand) {
*pLoc = value;
}
return NULL;
}
基準對比
作爲性能測試, 我將使用 C# 最簡版本 實現的 基於二叉樹的計算機語言基準測試 做對比。
注意:DotNetAnywhere 旨在運行於低內存設備,所以不意味着能與完整的 .NET Framework具有相同的性能。對比結果時切記!!
.NET Framework, 4.6.1 - 0.36 seconds
Invoked=TestApp.exe 15
stretch tree of depth 16 check: 131071
32768 trees of depth 4 check: 1015808
8192 trees of depth 6 check: 1040384
2048 trees of depth 8 check: 1046528
512 trees of depth 10 check: 1048064
128 trees of depth 12 check: 1048448
32 trees of depth 14 check: 1048544
long lived tree of depth 15 check: 65535
Exit code : 0
Elapsed time : 0.36
Kernel time : 0.06 (17.2%)
User time : 0.16 (43.1%)
page fault # : 6604
Working set : 25720 KB
Paged pool : 187 KB
Non-paged pool : 24 KB
Page file size : 31160 KB
DotNetAnywhere - 54.39 seconds
Invoked=dna TestApp.exe 15
stretch tree of depth 16 check: 131071
32768 trees of depth 4 check: 1015808
8192 trees of depth 6 check: 1040384
2048 trees of depth 8 check: 1046528
512 trees of depth 10 check: 1048064
128 trees of depth 12 check: 1048448
32 trees of depth 14 check: 1048544
long lived tree of depth 15 check: 65535
Total execution time = 54288.33 ms
Total GC time = 36857.03 ms
Exit code : 0
Elapsed time : 54.39
Kernel time : 0.02 (0.0%)
User time : 54.15 (99.6%)
page fault # : 5699
Working set : 15548 KB
Paged pool : 105 KB
Non-paged pool : 8 KB
Page file size : 13144 KB
顯然,DotNetAnywhere 在這個基準測試中運行速度並不快(0.36秒/ 54秒)。然而,如果我們對比另一個基準測試,它的表現就好很多。DotNetAnywhere 在分配對象(類)時有很大的開銷,而在使用結構時就不那麼明顯了。
Benchmark 1 (using classes) |
Benchmark 2 (using structs) |
|
|---|---|---|
| Elapsed Time (secs) | 3.1 | 2.0 |
| GC Collections | 96 | 67 |
| Total GC time (msecs) | 983.59 | 439.73 |
最後,我要感謝 Chris Bacon。DotNetAnywhere 真是一個偉大的代碼庫,對於我們實現 .NET 運行時很有幫助。
請在 Hacker News的 /r/programming 中討論本文。