




iostat 是用來分析 cpu 負載和磁盤 I/O 情況的工具。系統不自帶, 安裝sysstat 即可。
iostat的數據來源於/proc/diskstats

常用參數
iostat [參數] [時間] [次數]
- x:詳細
- m: MB顯示
- k: KB顯示
- p:顯示磁盤和分區的情況
- d:只顯示磁盤情況
常用操作:iostat -x -d -k 10 5: 每隔10s輸出一次,一共輸出5次
iostat含義

上面這些百分比是怎麼算出來的?
比如一秒內有100個cpu時間片,這個cpu時間片就是cpu工作的最小單位。那麼這100個cpu時間片在不同的區域和目的進行操作使用,就代表這個區域所佔用的cpu時間比。也就是這裏得出的cpu時間百分比。
比如下面一個程序:

將文件從磁盤的src位置拷貝到磁盤的dst位置。文件會從src先讀取進入到內核空間,然後再讀取到用戶空間,然後拷貝數據到用戶空間的buf上,再通過用戶空間,內核空間,數據纔到磁盤的dst上。
所以從上面這個程序來看,cpu消耗在kernel space的時候就是sy(系統態使用的cpu百分比),cpu消耗在user space的時候就是us(用戶態使用的cpu百分比)。
cpu屬性
- %user: 在用戶態(用戶空間)運行所使用的CPU的百分比.
- %nice:nice操作所使用的CPU的百分比.
- %system:在系統態(內核空間)運行所使用CPU的百分比.
簡單說,Kernel space 是 Linux 內核的運行空間,User space 是用戶程序的運行空間。爲了安全,它們是隔離的,即使用戶的程序崩潰了,內核也不受影響。
Kernel space 可以執行任意命令,調用系統的一切資源;User space 只能執行簡單的運算,不能直接調用系統資源,必須通過系統接口(又稱 system call),才能向內核發出指令。
str = "my string" // 用戶空間
x = x + 2
file.write(str) // 切換到內核空間
y = x + 4 // 切換回用戶空間
上面代碼中,第一行和第二行都是簡單的賦值運算,在 User space 執行。第三行需要寫入文件,就要切換到 Kernel space,因爲用戶不能直接寫文件,必須通過內核安排。第四行又是賦值運算,就切換回 User space。
- %iowait:等待輸入輸出 所使用cpu的百分比。
- %steal: 只對虛擬機有效,表示分配給當前虛擬機的 CPU 時間之中,被同一臺物理機上的其他虛擬機偷走的時間百分比。
- %idle:CPU空閒時間百分比。
如果%iowait的值過高,表示硬盤存在I/O瓶頸,%idle值高,表示CPU較空閒,如果%idle值高但系統響應慢時,有可能是CPU等待分配內存,此時應加大內存容量。%idle值如果持續低於10,那麼系統的CPU處理能力相對較低,表明系統中最需要解決的資源是CPU。
disk屬性
- rrqm/s: 每秒進行 merge(合併) 的讀操作數目。即 rmerge/s
- wrqm/s: 每秒進行 merge 的寫操作數目。即 wmerge/s
塊設備有相應的調度算法。如果兩個IO發生在相鄰的數據塊時,他們可以合併成1個IO。
這個簡單的可以理解爲快遞員要給一個18層的公司所有員工送快遞,每一層都有一些包裹,
對於快遞員來說,最好的辦法是同一樓層相近的位置的包裹一起投遞,否則如果不採用這種算法,
採用最原始的來一個送一個(即noop算法),那麼這個快遞員,可能先送了一個包括到18層,
又不得不跑到2層送另一個包裹,然後有不得不跑到16層送第三個包裹,然後包到1層送第三個包裹,
那麼快遞員的軌跡是雜亂無章的,也是非常低效的。Linux常見的調度算法有: noop deadline和cfq。此處不展開了。
root@node-186:~# cat /sys/block/sdc/queue/scheduler
[noop] deadline cfq
- r/s: 每秒完成的讀 I/O 次數。
- w/s: 每秒完成的寫 I/O 次數。
- rsec/s: 每秒讀扇區數。read sector
- wsec/s: 每秒寫扇區數。
- rkB/s: 每秒讀的K字節數。是 rsect/s 的一半,因爲每扇區大小爲512字節。
- wkB/s: 每秒寫K字節數。是 wsect/s 的一半。
- avgqu-sz: average queue,平均請求隊列的長度。毫無疑問,隊列長度越短越好。
首先我們用超市購物來比對iostat的輸出。我們在超市結賬的時候,一般會有很多隊可以排,
隊列的長度,在一定程度上反應了該收銀櫃臺的繁忙程度。那麼這個變量是avgqu-sz這個輸出反應的,
該值越大,表示排隊等待處理的io越多。
- avgrq-sz: 每個IO的平均扇區數,即所有請求的平均大小,以扇區(512字節)爲單位,我們經常關心,用戶過來的IO是大IO還是小IO,那麼avgrq-sz反應了這個要素
對比生活中的例子,超時排隊的時候,你會首先查看隊列的長度來評估下時間,如果隊列都差不多長的情況下,
你就要關心前面顧客籃子裏東西的多少了。
如果前面顧客每人手裏拿着一兩件商品,另一隊幾乎每一個人都推這滿滿一車子的商品,你可能知道要排那一隊。
因爲商品越多,處理單個顧客的時間就會越久。IO也是如此。
- await: 每個IO的平均處理時間(單位是微秒毫秒)。這裏可以理解爲IO的響應時間,一般地系統IO響應時間應該低於5ms,如果大於10ms就比較大了。這個時間包括了隊列時間和服務時間,也就是說,一般情況下,await大於svctm,它們的差值越小,則說明隊列時間越短,反之差值越大,隊列時間越長,說明系統出了問題。
await = ((所有讀IO的時間)+(所有寫IO的時間))/((讀請求的個數) + (寫請求的個數))
注意一點就行了,這個所有讀IO的時間和所有寫IO的時間,都是包括IO在隊列的時間在內的。不能一廂情願地認爲,
是磁盤控制器處理該IO的時間。注意,能不能說,await比較高,所以武斷地判定這塊盤的能力很菜?
答案是不能。await這個值不能反映硬盤設備的性能。await的這個值不能反映硬盤設備的性能,
await這個值不能反映硬盤設備的性能,重要的話講三遍。我們考慮兩種IO的模型:
250個IO請求同時進入等待隊列
250個IO請求依次發起,待上一個IO完成後,發起下一個IO
第一種情況await高達500ms,第二個情況await只有4ms,但是都是同一塊盤。但是注意await是相當重要的一個參數,它表明了用戶發起的IO請求的平均延遲:
await = IO 平均處理時間 + IO在隊列的平均等待時間
因此,這個指標是比較重要的一個指標。
- svctm: 表示平均每次設備I/O操作的服務時間(以毫秒爲單位,不包括等待時間。請注意這是一個推斷數據,不保證完全準確)。如果svctm的值與await很接近,表示幾乎沒有I/O等待,磁盤性能很好,如果await的值遠高於svctm的值,則表示I/O隊列等待太長, 系統上運行的應用程序將變慢。
對於iostat這個功能而言,%util固然會給人帶來一定的誤解和苦擾,但是svctm給人帶來的誤解更多。
一直以來,人們希望瞭解塊設備處理單個IO的service time,這個指標直接地反應了硬盤的能力。回到超市收銀這個類比中,如果收銀員是個老手,操作流,效率很高,那麼大家肯定更願意排這一隊。
但是如果收銀員是個新手,各種操作不熟悉,動作慢,效率很低,那麼同樣多的任務,就會花費更長的時間。
因此IO的平均service time(不包括排隊時間)是非常有意義的。但是service time和iostat無關,iostat沒有任何一個參數能夠提供這方面的信息。
而svctm這個輸出給了人們這種美好的期待,卻只能讓人空歡喜。從現在起,我們記住,我們不能從svctm中得到自己期待的service time這個值,這個值其實並沒有什麼意義,
事實上,這個值不是獨立的,它是根據其他值計算出來的。既然svctm不能反映IO處理時間,那麼有沒有一個參數可以測量塊設備的IO平均處理時間呢?
很遺憾iostat是做不到的。但是隻要思想不滑坡,辦法總比困難多,
blktrace這個神器可能得到這個設備的IO平均處理時間。
blktrace可以講IO路徑分段,分別統計各段的消耗的時間。
- %util: 在統計時間內所有處理IO時間,除以總共統計時間。例如,如果統計間隔1秒,該設備有0.8秒在處理IO,而0.2秒閒置,那麼該設備的%util = 0.8/1 = 80%,所以該參數暗示了設備的繁忙程度。一般地,如果該參數是100%表示設備已經接近滿負荷運行了(當然如果是多磁盤,即使%util是100%,因爲磁盤的併發能力,所以磁盤使用未必就到了瓶頸)。
%util 和磁盤設備飽和度
注意,%util是最容易讓人產生誤解的一個參數。
很多初學者看到%util 等於100%就說硬盤能力到頂了,這種說法是錯誤的。%util數據源自diskstats中的io_ticks,這個值並不關心等待在隊裏裏面IO的個數,它只關心隊列中有沒有IO。
和超時排隊結賬這個類比最本質的區別在於,現代硬盤都有並行處理多個IO的能力,但是收銀員沒有。
收銀員無法做到同時處理10個顧客的結賬任務而消耗的總時間與處理一個顧客結賬任務相差無幾。
但是磁盤可以。所以,即使%util到了100%,也並不意味着設備飽和了。最簡單的例子是,某硬盤處理單個IO請求需要0.1秒,有能力同時處理10個。
但是當10個請求依次提交的時候,需要1秒鐘才能完成這10%的請求,,在1秒的採樣週期裏,%util達到了100%。
但是如果10個請一次性提交的話, 硬盤可以在0.1秒內全部完成,這時候,%util只有10%。因此,在上面的例子中,一秒中10個IO,即IOPS=10的時候,%util就達到了100%,
這並不能表明,該盤的IOPS就只能到10,事實上,縱使%util到了100%,
硬盤可能仍然有很大的餘力處理更多的請求,即並未達到飽和的狀態。下一小節有4張圖,可以看到當IOPS爲1000的時候%util爲100%,
但是並不意味着該盤的IOPS就在1000,實際上2000,3000,5000的IOPS都可以達到。
根據%util 100%時的 r/s 或w/s 來推算磁盤的IOPS是不對的。那麼有沒有一個指標用來衡量硬盤設備的飽和程度呢。很遺憾,iostat沒有一個指標可以衡量磁盤設備的飽和度。
io分類
Linux有兩種IO:
- Direct IO:直接寫磁盤
- Buffered IO: 先寫到緩存再寫磁盤,大部分場景下都是Buffered IO。
其他常見io指標
計算方法:每秒採集一次/proc/diskstats
disk.io.ios_in_progress:當前正在運行的實際I / O請求數
disk.io.msec_read:所有讀取花費的時間,ms
disk.io.msec_write:所有寫入花費的時間 ms
disk.io.msec_total:ios_in_progress> = 1的時間量
disk.io.msec_weighted_total:磁盤花在處理請求上的總加權時間
注意:這個值的意義是『所有請求的總等待時間』
每一次請求結束後,這個值會增加這個請求的處理時間乘以當前的隊列長度
如何提高機器的磁盤性能?
1) 首先想到的就是換性能好的磁盤。這個好像是最高效的方式,SSD具有更好的性能,訪問數據都是隨機的。更小的功耗。LVM(邏輯卷)的擴容。
2) 然後就是Raid (RAID0, RAID1, RAID5, RAID0+1)。通過raid實際數據在多塊磁盤的併發讀寫和數據備份。增強磁盤的可用性和容錯能力
3) 確定機器的上線的需求。運維人員一定要知道,機器的使用場景。小文件(佔用Inode例如圖片)讀寫瓶頸是磁盤的尋址(tps),大文件(佔用磁盤容量)讀寫的性能瓶頸是帶寬
4) Linux有一句話(一切皆文件)。空閒內存作文件系統訪問的cache,因此係統內存越大存儲系統的性能也越好
5) 最後就是架構層面的優化,CDN(nginx、squid..),機房內部反向代理(squid),memcached,消息隊列,緩存機制。總之就是靜態的採用緩存機制。非靜態的優化性能,減小調用磁盤
哪些問題會導致磁盤緩慢?
1)應用程序設計的缺陷和數據庫查詢的濫用、操作人員的失誤、都有可能導致性能問題
2)性能瓶頸可能是因爲程序設計缺陷/內存太小/磁盤有損壞、性能差,但是最終都是CPU耗盡的結果(這就話很實用),系統負載極高,響應遲緩,甚至暫時失去響應。登陸不上機器。
3)由於linux的swap機制。物理內存不夠時會使用交換內存(可以調優參數),大量使用swap會帶來磁盤I0進而導致CPU消耗
4)可能造成cpu瓶頸的問題:頻繁執Perl,php,java程序生成動態web;數據庫查詢大量的where子句、order by/group by排序……
5)可能造成內存瓶頸問題:高併發用戶訪問、系統進程多(每個進程都會消耗內存,駐留內存),java內存泄露……
6)可能造成磁盤IO瓶頸問題:生成cache文件,數據庫頻繁更新,或者查詢大表……
如何查看磁盤緩慢?
1)swap(當內存不足時會調用SWAP)
a.si列表示由磁盤調入內存,也就是內存進入內存交換區的數量;
b.so列表示由內存調入磁盤,也就是內存交換區進入內存的數量
c.一般情況下,si、so的值都爲0,如果si、so的值長期不爲0,則表示系統內存不足,需要考慮是否增加系統內存。或者擴展機器提高可用性
2)IO
a.bi列表示從塊設備讀入的數據總量(即讀磁盤,單位KB/秒)
b.bo列表示寫入到塊設備的數據總量(即寫磁盤,單位KB/秒)
這裏設置的bi+bo參考值爲1000,如果超過1000,而且wa值比較大,則表示系統磁盤IO性能瓶頸。

一個IO高的分析案例
1.首先,執行 top 發現負載很高,其次,發送CPU 利用率比較低,但是iowait 很高,高達63.4,再次發現進程中佔CPU和內存最高的是一個python 應用。進程ID 5593
top - 15:21:09 up 22:38, 2 users, load average: 2.54, 2.27, 1.35
Tasks: 86 total, 3 running, 50 sleeping, 0 stopped, 0 zombie
%Cpu(s): 3.2 us, 16.4 sy, 0.0 ni, 16.9 id, 63.4 wa, 0.0 hi, 0.0 si, 0.2 st
KiB Mem : 8156288 total, 5366112 free, 1109200 used, 1680976 buff/cache
KiB Swap: 8388604 total, 8388080 free, 524 used. 6763836 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5593 root 20 0 963312 934276 5320 R 37.5 11.5 4:49.05 python
5648 root 20 0 0 0 0 D 1.3 0.0 0:03.47 kworker/u128:2
1043 root 20 0 1044268 64328 27400 S 0.7 0.8 2:02.97 dockerd
8 root 20 0 0 0 0 R 0.3 0.0 0:00.96 rcu_sched
3937 root 20 0 103864 7148 6148 S 0.3 0.1 0:00.60 sshd
1 root 20 0 225036 8624 6508 S 0.0 0.1 0:02.31 systemd
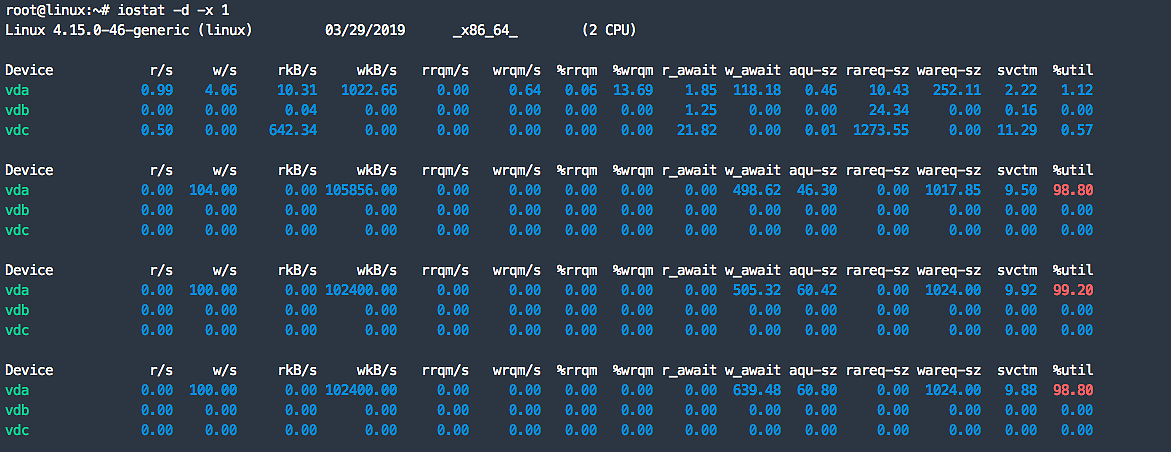
2.使用 iostat -d -x 1 查看所有磁盤的io情況,發現 vda 的util 高達98% 接近飽和,其次發現IO高的原因是因爲往磁盤不停的寫數據,平均每秒寫入數據 105856KB
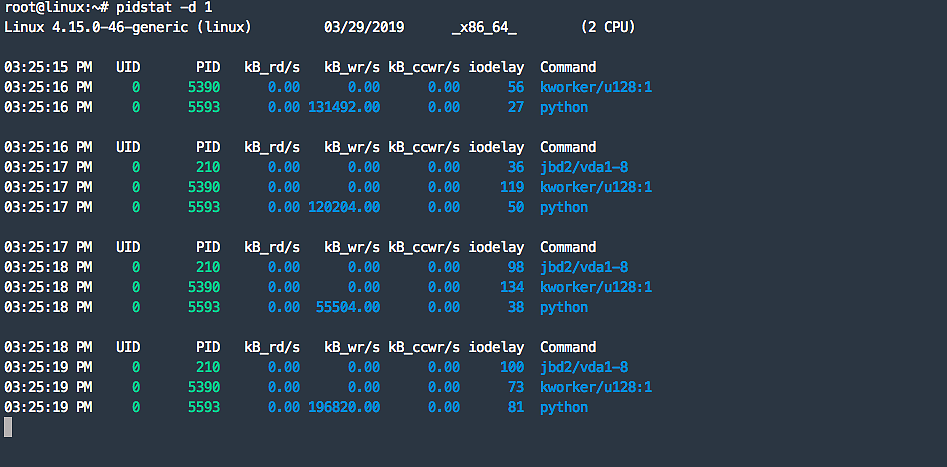
3.我們通過pidstat -d 1 查看是哪個進程佔用IO高,發現果然是這個python 進程。
4.然後通過 strace 追蹤Python 進程 5593 發現其一直在調用write函數向文件描述符爲 3的文件寫入文件,平均每秒寫入數據 300 MB(314572844/1024/1024) 觀察stat,他打開的是/tmp/logtest.txt 文件
root@linux:~# strace -p 5593
strace: Process 5593 attached
stat("/tmp/logtest.txt", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0
rename("/tmp/logtest.txt", "/tmp/logtest.txt.1") = 0
open("/tmp/logtest.txt", O_WRONLY|O_CREAT|O_APPEND|O_CLOEXEC, 0666) = 3
fcntl(3, F_SETFD, FD_CLOEXEC) = 0
fstat(3, {st_mode=S_IFREG|0644, st_size=0, ...}) = 0
lseek(3, 0, SEEK_END) = 0
ioctl(3, TIOCGWINSZ, 0x7ffcc341db60) = -1 ENOTTY (Inappropriate ioctl for device)
lseek(3, 0, SEEK_CUR) = 0
ioctl(3, TIOCGWINSZ, 0x7ffcc341da80) = -1 ENOTTY (Inappropriate ioctl for device)
lseek(3, 0, SEEK_CUR) = 0
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f016accf000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f01580ce000
write(3, "2019-03-29 07:26:28,703 - __main"..., 314572844) = 314572844
munmap(0x7f01580ce000, 314576896) = 0
write(3, "\n", 1) = 1
munmap(0x7f016accf000, 314576896) = 0
select(0, NULL, NULL, NULL, {tv_sec=0, tv_usec=100000}) = 0 (Timeout)
getpid() = 1
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f016accf000
mmap(NULL, 393220096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f01535ce000
mremap(0x7f01535ce000, 393220096, 314576896, MREMAP_MAYMOVE) = 0x7f01535ce000
munmap(0x7f016accf000, 314576896) = 0
lseek(3, 0, SEEK_END) = 314572845
lseek(3, 0, SEEK_CUR) = 314572845
munmap(0x7f01535ce000, 314576896) = 0
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f016accf000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f01580ce000
write(3, "2019-03-29 07:26:37,480 - __main"..., 314572844) = 314572844
munmap(0x7f01580ce000, 314576896) = 0
5.我們進一步確認,使用lsof 查看該進程調用情況,發現其確實打開了文件/tmp/logtest.txt,這個輸出界面 3w 表示3號文件描述符的權限爲寫(w)
root@linux:~# lsof -p 5593
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 5593 root cwd DIR 0,51 4096 131090 /
python 5593 root rtd DIR 0,51 4096 131090 /
python 5593 root txt REG 0,51 28016 266366 /usr/local/bin/python3.7
python 5593 root mem REG 252,1 266366 /usr/local/bin/python3.7 (stat: No such file or directory)
*****
python 5593 root 1u CHR 136,0 0t0 3 /dev/pts/0
python 5593 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 5593 root 3w REG 252,1 916045824 2914 /tmp/logtest.txt
磁盤性能壓測二三事之——性能參數和指標
近日工作中遇到了一個磁盤壓測時性能上不去的問題,經排查,發現原因有以下幾個方面:
- 測試參數的選擇
- 業務邏輯未關閉
本文就將通過對磁盤性能測試指標及參數的介紹,來理解以上兩個原因爲什麼會對測試結果有影響。
首先來介紹一下磁盤性能的測試指標。
最常用的磁盤性能評價指標有兩個:IOPS和吞吐量(throughput)。
IOPS是Input/Output Per Second的縮寫,它表示單位時間內系統能處理的I/O請求數量,即每秒鐘系統能處理的讀寫次數。
吞吐量衡量單位時間內系統能處理的數據的體量,即每秒鐘磁盤上能讀寫出的數據量的大小,通常以kB/s或MB/s爲單位。
兩個指標相互獨立,又相互關聯,在不同業務場景下,側重關注的指標也有所不同。
對於文件尺寸小,隨機讀寫比較多的場合,比如在線交易處理系統,我們傾向於更關注IOPS,因爲我們更在乎的是每秒鐘能處理多少條交易。
而對於文件尺寸較大,順序讀寫比較多的場合,比如視頻播放服務,數據吞吐量將會成爲我們主要的考量指標。
舉個例子來幫助我們更好的理解這兩個指標。磁盤IO就相當於我們有貨物(數據)需要從A處(系統)與B處(磁盤)之間往返。貨物(數據量)有多有少,因此運貨車也有大有小。B處有裝卸工人負責將貨物卸載到倉庫的指定位置,或者從倉庫指定位置提取貨物裝載到貨車上。
每次貨車運輸一趟貨物就相當於處理一個IO請求,工人裝卸貨物就相當於磁盤對IO的讀寫處理。在工人數量和工人裝卸貨物速度(磁盤數據處理速度)保持一定的情況下,裝卸大車上貨物的時間一定會比小車上的時間長,裝卸一大車貨物的時間,可能已經夠小車運輸若干趟貨物(IOPS高)。但是小車由於多次往返,其花在路上的時間要比大車多,同時每次裝卸貨物工人需要尋找正確的位置存取貨物(磁盤尋址時間),比起大車的一次尋址,小車運貨就也浪費了更多時間。因此在相同時間內,採用大車運輸的貨物總量是比小車要多的(吞吐量高)。
這也是爲什麼我們在做磁盤性能測試的時候,通常一次只關注一個指標,追求IOPS,就用小車運輸少量貨物,多次往返。追求吞吐量,就用大車運送大量貨物,節省路上及尋址所花費的時間。

下面再說一下磁盤測試的影響因素。
實際測量中,IOPS會受到很多因素的影響,比如:
1) 數據塊大小:
相當於我們前面說的大車和小車運貨的情況
2) 順序和隨機:
順序就是我們的貨物都按順序安排在倉庫的一處,隨機則意味着貨物隨機的分配在倉庫的不同地點,可以想見,貨物地點存放比較隨機的情況下,存取貨物一定是更費時間的。
3 ) 隊列深度:
如果我們每次只發一輛貨車在AB之間往返,那麼當貨車在A處處理貨物或者在AB之間的路上跑的時候,B處的工人就處於閒置的狀態,壓力測試時,我們絕對不希望這種情況發生,我們需要工人(磁盤)一直工作,從而得出磁盤的最高性能。想實現這一點,我們可以通過一次發多輛車來解決,保持始終有車輛在等待處理的隊伍裏,這樣裝卸工人就一直有工作可做了。
隊列深度就是等待處理的隊伍裏的貨車以及正在被裝卸的貨車的總數量。

4 ) 線程數
測試時,增加線程數也可以增加併發度,從而使裝卸工人一直處於有工作可做的狀態。
5) 讀寫比例
讀操作相當於我們將貨從B中的倉庫取出來,運到A處就結束了。而寫操作意味着貨物在A處經過一番處理之後還要再運回B處並存儲在倉庫中。因此不同的讀寫比例也會造成測試結果的不同。
正是由於這些不同影響因素的存在,我們在對磁盤進行性能測試時,需要仔細選擇測試參數,否則將無法測出磁盤的最優性能。同時應將測試參數和方法定性定量,否則測試結果將失去比較的價值。
以 雲盤參數和性能測試方法:
https://help.aliyun.com/document_detail/25382.html
一文中介紹的測試IOPS的方法爲例,我們來看一下linux常用測試工具fio的參數如何體現以上影響因素。
測試隨機寫IOPS:
fio -direct=1 -iodepth=128 -rw=randwrite -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/[device] -name=Rand_Write_Testing
測試隨機讀IOPS:
fio -direct=1 -iodepth=128 -rw=randread -ioengine=libaio -bs=4k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/[device] -name=Rand_Read_Testing
測試寫吞吐量:
fio -direct=1 -iodepth=64 -rw=write -ioengine=libaio -bs=1024k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/[device] -name=Write_PPS_Testing
測試讀吞吐量:
fio -direct=1 -iodepth=64 -rw=read -ioengine=libaio -bs=1024k -size=1G -numjobs=1 -runtime=1000 -group_reporting -filename=/dev/[device] -name=Read_PPS_Testing
其中:
- iodepth:隊列深度。異步引擎下起作用。
- rw: 讀寫模式,可選模式有順序寫write、順序讀read、隨機寫randwrite、隨機讀randread、混合隨機讀寫randrw。
- ioengine: 負載引擎。libaio引擎用於發起異步IO請求。
- bs: IO塊大小。
- numjobs 測試線程數。
對比四個測試方法的參數我們可以看到,測試IOPS時我們採用小數據塊(bs=4k),測試吞吐量時則用大數據塊(bs=1024k)。這和我們前面說到的大貨車小貨車的選擇原理是一致的。
隊列深度對IOPS的影響要大於對吞吐量的影響,因爲我們測試IOPS時選擇的iodepth更大。但iodepth也不是越大越好,因爲當裝卸工人數量、裝卸貨物速度、倉庫尋址時間一定之後,單位時間內所能處理的最大貨物量也就確定了,即磁盤的能力確定了。一味增加隊列深度,增加的只能是貨物在隊列裏的等待時間,即平均IO響應時間。
我們可以通過查看裝卸工人的忙碌程度來決定是否要增加隊列深度。如果磁盤的busy%爲100%,那就表示所有工人都在一刻不停歇的裝卸貨物了,已經不再有提升的空間,此時再增加隊列深度或是數據量大小對測試結果都將是徒勞。反之,則表示磁盤壓力尚未到極限,得出的數據不能代表磁盤性能最高水平。
磁盤壓測時如果有其他業務邏輯在運行會怎樣呢?這種情況就相當於有一部分貨車裝運的是業務邏輯的數據,而這些貨車也會佔用我們的隊列和裝卸工人,測試引擎將無法百分之百的使用全部隊列和裝卸工人,那麼我們的測試結果將不能體現整個磁盤的能力。尤其是當業務邏輯所涉及的IO是同步(synchronous)請求的時候,對測試結果的影響將更大,因爲同步IO就相當於前面說到的一次只讓一輛車在路上跑,只有等它跑完纔會發下一輛車。因此在壓力測試的時候,我們需要將業務邏輯關閉的。
參考:
http://bean-li.github.io/dive-into-iostat/
http://linuxperf.com/?p=156
https://yq.aliyun.com/articles/218517?spm=a2c4e.11153959.0.0.184127eeuKmmwp