




Oracle使用正則表達式離不開這4個函數:
1。regexp_like
2。regexp_substr
3。regexp_instr
4。regexp_replace
看函數名稱大概就能猜到有什麼用了。
regexp_like 只能用於條件表達式,和 like 類似,但是使用的正則表達式進行匹配,語法很簡單:
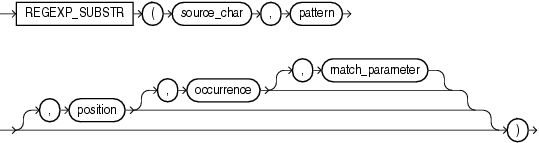
regexp_substr 函數,和 substr 類似,用於拾取合符正則表達式描述的字符子串,語法如下:

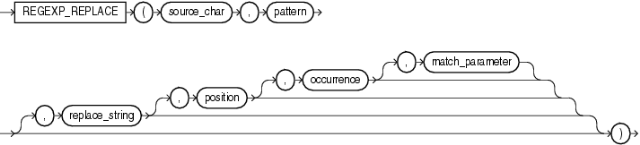
regexp_replace 函數,和 replace 類似,用於替換符合正則表達式的字符串,語法如下:
這裏解析一下幾個參數的含義:
1。source_char,輸入的字符串,可以是列名或者字符串常量、變量。搜索字符串。可以是任意的數據類型char,VARCHAR2,nchar,CLOB,NCLOB類型
2。pattern,正則表達式。
3。match_parameter,匹配選項。
取值範圍: i:大小寫不敏感; c:大小寫敏感;n:點號 . 不匹配換行符號;m:多行模式;x:擴展模式,忽略正則表達式中的空白字符。
4。position,標識從第幾個字符開始正則表達式匹配。可選。搜索在字符串中的開始位置。如果省略,默認爲1,這是第一個位置的字符串。
5。occurrence,標識第幾個匹配組。可選。它是模式字符串中的第n個匹配位置。如果省略,默認爲1。
6。replace_string,替換的字符串。
| 值 | 描述 |
| ^ | 匹配一個字符串的開始。如果與“m” 的match_parameter一起使用,則匹配表達式中任何位置的行的開頭。 |
| $ | 匹配字符串的結尾。如果與“m” 的match_parameter一起使用,則匹配表達式中任何位置的行的末尾。 |
| * | 匹配零個或多個。 |
| + | 匹配一個或多個出現。 |
| ? | 匹配零次或一次出現。 |
| 。 | 匹配任何字符,除了空。 |
| | | 用“OR”來指定多個選項。 |
| [] | 用於指定一個匹配列表,您嘗試匹配列表中的任何一個字符。 |
| [^] | 用於指定一個不匹配的列表,您嘗試匹配除列表中的字符以外的任何字符。 |
| () | 用於將表達式分組爲一個子表達式。 |
| {M} | 匹配m次。 |
| {M,} | 至少匹配m次。 |
| {M,N} | 至少匹配m次,但不多於n次。 |
| \ n | n是1到9之間的數字。在遇到\ n之前匹配在()內找到的第n個子表達式。 |
| [..] | 匹配一個可以多於一個字符的整理元素。 |
| [:] | 匹配字符類。 |
| [==] | 匹配等價類。 |
| \ d | 匹配一個數字字符。 |
| \ D | 匹配一個非數字字符。 |
| \ w | 匹配包括下劃線的任何單詞字符。 |
| \ W | 匹配任何非單詞字符。 |
| \ s | 匹配任何空白字符,包括空格,製表符,換頁符等等。 |
| \ S | 匹配任何非空白字符。 |
| \A | 在換行符之前匹配字符串的開頭或匹配字符串的末尾。 |
| \Z | 匹配字符串的末尾。 |
| *? | 匹配前面的模式零次或多次發生。 |
| +? | 匹配前面的模式一個或多個事件。 |
| ?? | 匹配前面的模式零次或一次出現。 |
| {N}? | 匹配前面的模式n次。 |
| {N,}? | 匹配前面的模式至少n次。 |
| {N,M}? | 匹配前面的模式至少n次,但不超過m次。 |