




1.简单介绍Transformer
Transformer是一种使用Attention机制类提升模型训练的速度的模型,该模型的最大优势在于其并行性良好,是一个非时序深度的encoder block加decoder block模型,可以用来代替seq2seq进行长距离的依赖建模。
Transformer详解推荐这篇文章:https://jalammar.github.io/illustrated-transformer/
2.Encoder-Decoder框架
我们先来看看Encoder-Decoder框架。现阶段的深度学习模型,我们通常都将其看作黑箱,而Encoder-Decoder框架则是将这个黑箱分为两个部分,一部分做编码,另一部分做解码。

在不同的NLP任务中,Encoder框架及Decoder框架均是由多个单独的特征提取器堆叠而成,比如说我们之前提到的LSTM结构或CNN结构。由最初的one-hot向量通过Encoder框架,我们将得到一个矩阵(或是一个向量),这就可以看作其对输入序列的一个编码。而对于Decoder结构就比较灵活饿了,我们可以根据任务的不同,对我们得到的“特征”矩阵或“特征”向量进行解码,输出为我们任务需要的输出结果。因此,对于不同的任务,如果我们堆叠的特征抽取器能够提取到更好的特征,那么理论上来说,在所有的NLP任务中我们都能够得到更好的表现。
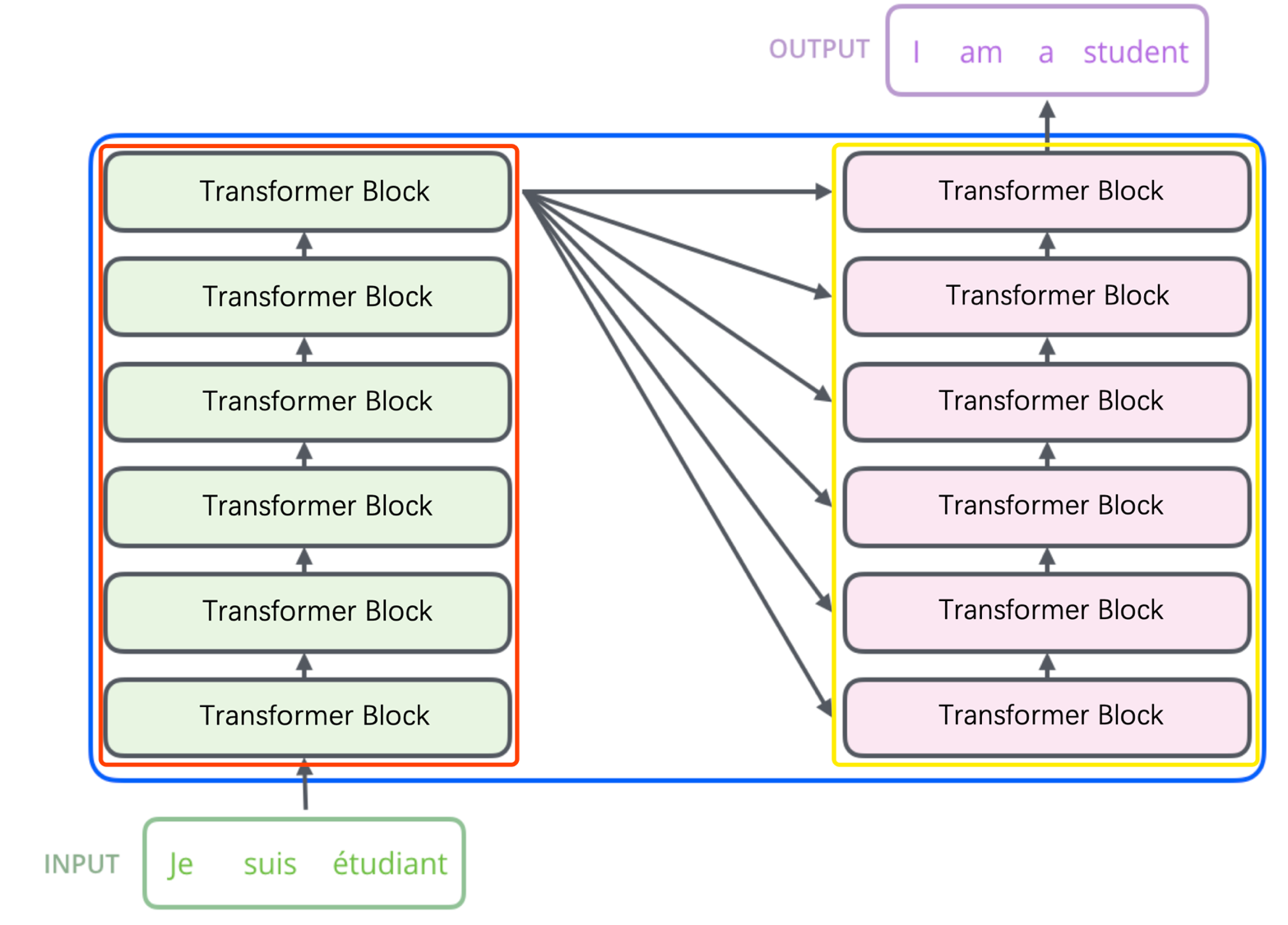
Transformer结构是在论文《Attention is All You Need》中提出的的模型,如上图所示。图中红框内为Encoder框架,黄框内为Decoder框架,其均是由多个Transformer Block堆叠而成的。这里的Transformer Block就代替了我们之前提到的LSTM和CNN结构作为了我们的特征提取器,也是其最关键的部分。更详细的示意图如下图所示。我们可以发现,编码器中的Transformer与解码器中的Transformer是有略微区别的,但我们通常使用的特征提取结构(包括Bert)主要是Encoder中的Transformer,那么我们这里主要理解一下Transformer在Encoder中是怎么工作的。
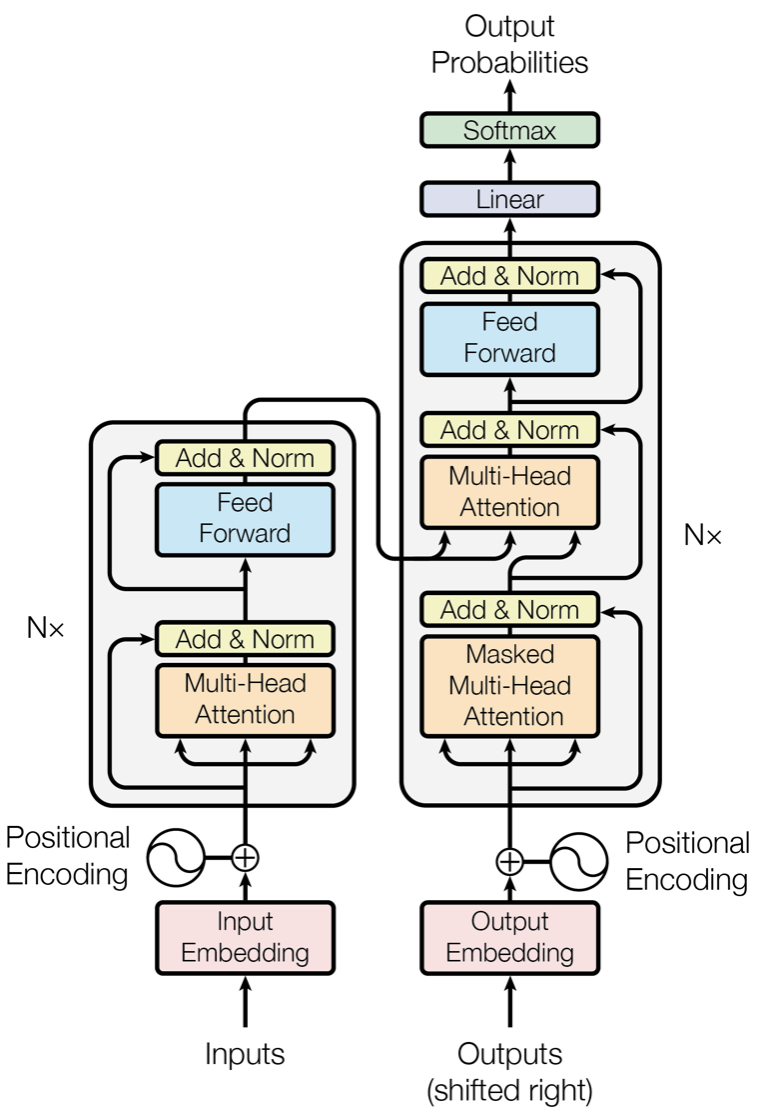
由上图可知,单个的Transformer Block主要由两部分组成:多头注意力机制(Multi-Head Attention)和前馈神经网络(Feed Forward)。
3.多头注意力机制(Multi-Head Attention)
Multi-Head Attention模块结构如下图所示:
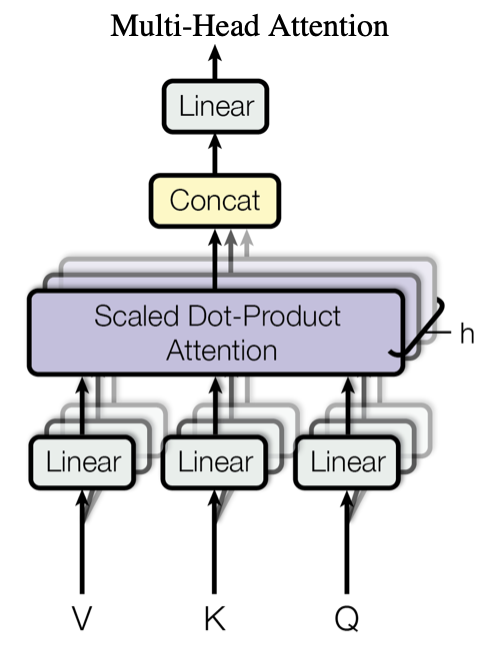
这里,我们就可以明白为什么这一部分被称为Multi-Head了,因为其本身就是由hh个子模块Scaled Dot-Product Attention堆叠而成的,该模块也被称为Self-Attention模块。
在Multi-Head Attention中,最关键的部分就是Self-Attention部分了,这也是整个模型的核心配方,我们将其展开,如下图所示。
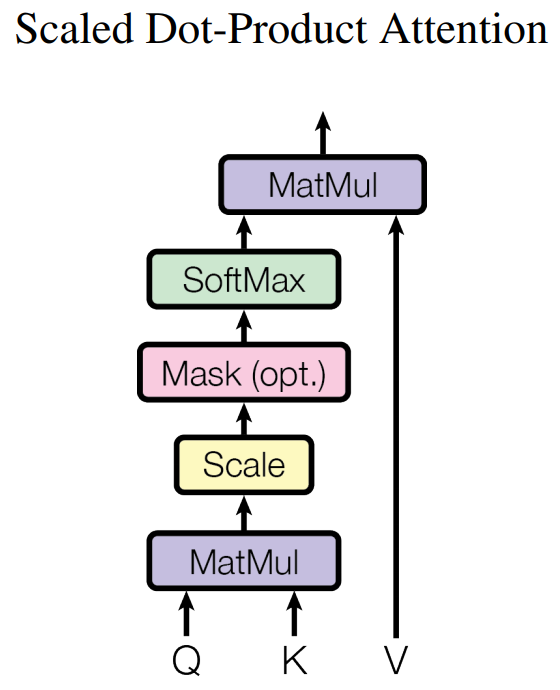
我们之前已经提到过,Self-Attention的输入仅仅是矩阵X的三个线性映射。那么Self-Attention内部的运算具有什么样的含义呢?我们从单个词编码的过程慢慢理解:
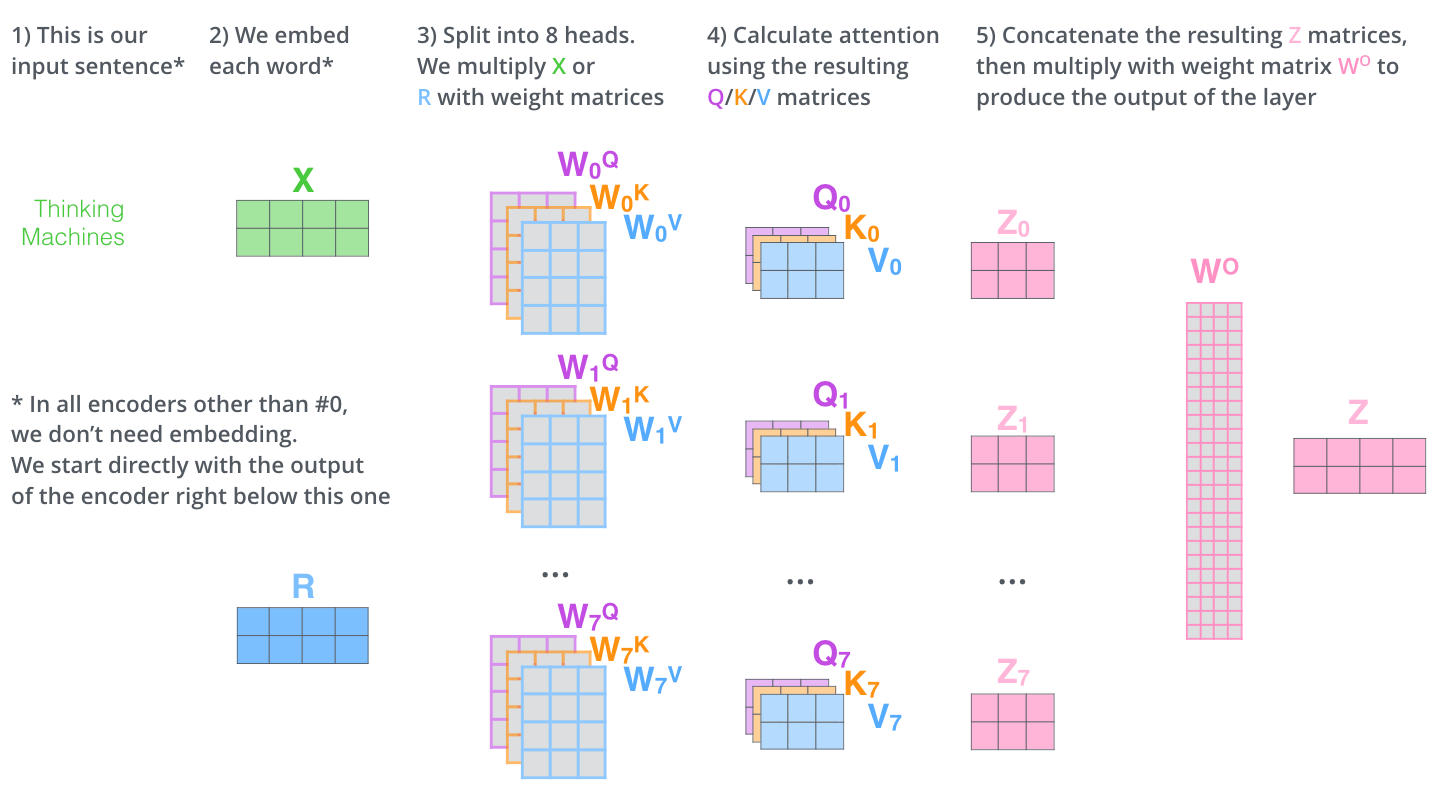
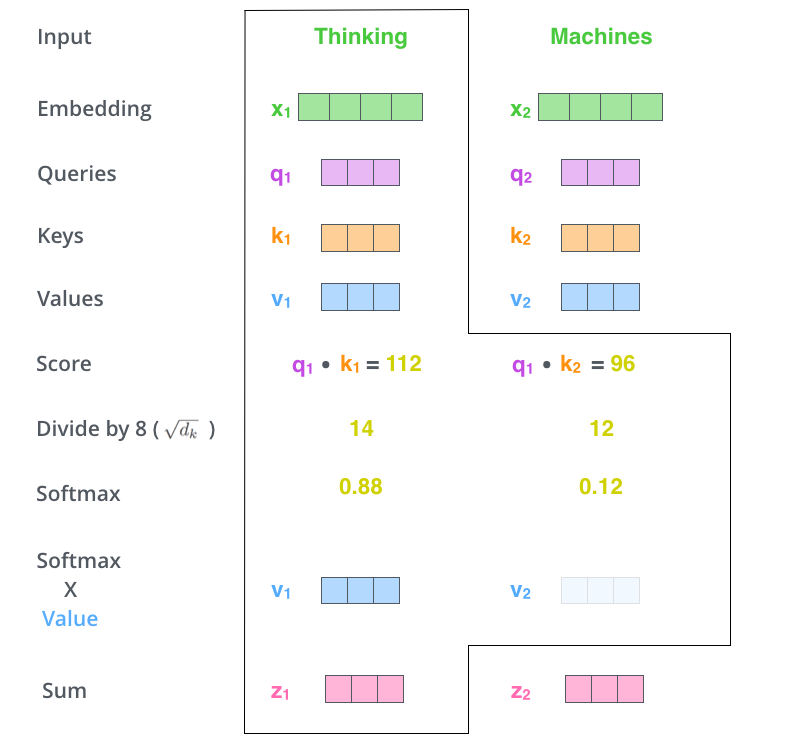
- 首先,我们对于输入单词向量X生成三个对应的向量: Query, Key 和 Value。注意这三个向量相比于向量X要小的多(论文中X的长度是512,三个向量的长度为64,这只是一种基于架构上的选择,因为论文中的Multi-Head Attention有8个Self-Attention模块,8个Self-Attention的输出要拼接,将其恢复成长度为512的向量),这一个部分是对每个单词独立操作的
- 用Queries和Keys的点积计算所有单词相对于当前词(图中为Thinking)的得分Score,该分数决定在编码单词“Thinking”时其他单词给予了多少贡献
- 将Score除以向量维度(64)的平方根(保证Score在一个较小的范围,否则softmax的结果非零即1了),再对其进行Softmax(将所有单词的分数进行归一化,使得所有单词为正值且和为1)。这样对于每个单词都会获得所有单词对该单词编码的贡献分数,当然当前单词将获得最大分数,但也将会关注其他单词的贡献大小
- 对于得到的Softmax分数,我们将其乘以每一个对应的Value向量
- 对所得的所有加权向量求和,即得到Self-Attention对于当前词”Thinking“的输出
显然,上述过程可以用以下的矩阵形式进行并行计算:

其中,Q, V, K分别表示输入句子的Queries, Keys, Values矩阵,矩阵的每一行为每一个词对应的向量Query, Key, Value向量,dkdk表示向量长度。因此,Transformer同样也具有十分高效的并行计算能力。
我们再回到Multi-Head Attention,我们将独立维护的8个Self-Attention的输出进行简单的拼接,通过一个线性映射层,就得到了单个多头注意力的输出。其整个过程可以总结为下面这个示意图:
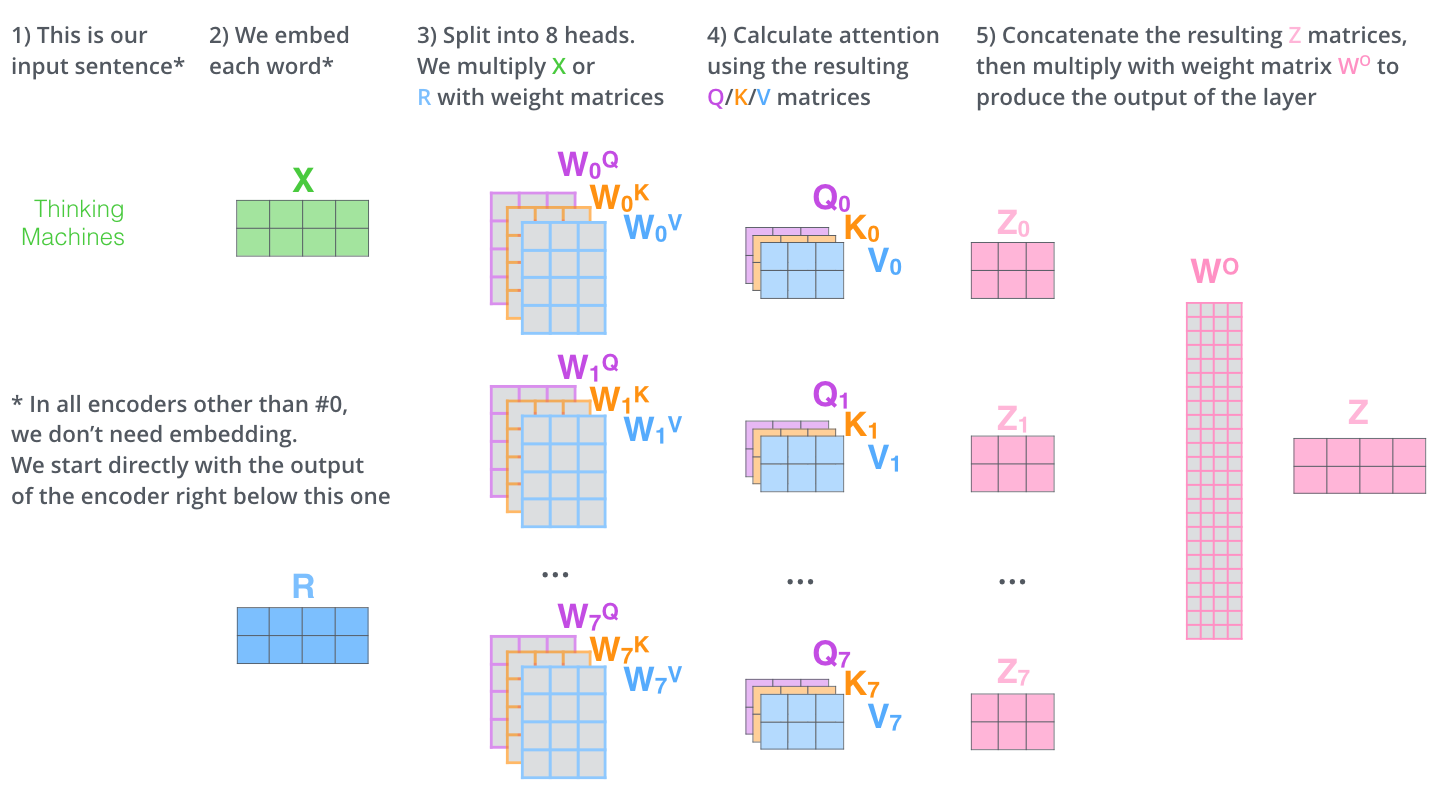
4.位置编码(Positional Encoding)
我们之前提到过,由于RNN的时序性结构,所以天然就具备位置编码信息。CNN本身其实也能提取一定位置信息,但多层叠加之后,位置信息将减弱,位置编码可以看作是一种辅助手段。Transformer的每一个词的编码过程使得其基本不具备任何的位置信息(将词序打乱之后并不会改变Self-Attention的计算结果),因此位置向量在这里是必须的,使其能够更好的表达词与词之间的距离。构造位置编码的公式如下所示:

5.Transformer小结
- 从语义特征提取能力:Transformer显著超过RNN和CNN,RNN和CNN两者能力差不太多。
- 长距离特征捕获能力:CNN极为显著地弱于RNN和Transformer,Transformer微弱优于RNN模型,但在比较远的距离上(主语谓语距离大于13),RNN微弱优于Transformer,所以综合看,可以认为Transformer和RNN在这方面能力差不太多,而CNN则显著弱于前两者。这部分我们之前也提到过,CNN提取长距离特征的能力收到其卷积核感受野的限制,实验证明,增大卷积核的尺寸,增加网络深度,可以增加CNN的长距离特征捕获能力。而对于Transformer来说,其长距离特征捕获能力主要受到Multi-Head数量的影响,Multi-Head的数量越多,Transformer的长距离特征捕获能力越强
- 任务综合特征抽取能力:通常,机器翻译任务是对NLP各项处理能力综合要求最高的任务之一,要想获得高质量的翻译结果,对于两种语言的词法,句法,语义,上下文处理能力,长距离特征捕获等方面的性能要求都是很高的。从综合特征抽取能力角度衡量,Transformer显著强于RNN和CNN,而RNN和CNN的表现差不太多。
- 并行计算能力:对于并行计算能力,上文很多地方都提到过,并行计算是RNN的严重缺陷,而Transformer和CNN差不多。