




壓縮好了,就知道文件怎麼存了
解壓縮就超級簡單了。
獲取標記文件,判斷比特位0還是1
遇見0直接解壓縮
遇見0向前匹配DIST距離,找LEN長度。
解決 大於64K文件的壓縮
針對上一篇無法解決64K以上文件也很好解決。
在讀取文件後解決時,每次只需判斷一下緩衝區的剩餘數據夠不夠MIN_MATCH
不夠的話從文件中讀取WSIZE個,
那麼在讀取之前,先講先行緩衝區窗口內的數據搬移到查找緩衝區,
同時更新哈希表中的位置數據,和衝突數據
直到讀取到文件尾。
壓縮效率

遇到的問題
1 緩衝區錯用了char ,char不能會出現下標爲負數的情況,導致數組下標越界。
2 尋找最長匹配的時候錯用了UCH導致部分解碼失敗UCH接收256~258時發生錯誤,長度應該用USH接收,因爲我們匹配爲3~258
3 寫壓縮文件和解壓縮時文件指針類型剛開始寫的時普通類型,後期發現導致漢字出現亂碼,解決方式:讓文件指針以二進制方式
4 解壓縮時,未及時刷新緩衝區,錯將fflush(文件指針)寫成fflush(stdout)
PS 這個錯誤導致我找錯找了1天多。。哭死了~ 這下長記性了吧?
對LZ77 的壓縮結果再壓縮,效率就不怎麼好了。
能否採用Huff曼的方式直接對LZ77結果再壓縮?
**可以 ,但壓縮率可能不是很好;
1 Huffman缺陷 :需要創建哈夫曼樹,可能會很大
2 LZ77的標記信息也會參與Huffman壓縮,因此,影響壓縮率。
3 樹大的話,內存可能壓力比較大。
假設文件中含有200個不同種類的字節,
那麼 總節點將是葉子結點200 +臨時父親199個 = 399個節點。即2n -1。
那麼Huffman樹就很大了 ,獲取編碼的效率就比較低了。
獲取編碼的方式: 遞歸到葉子。
解決方案: 範式哈夫曼樹

範式哈夫曼樹: 在哈夫曼樹的基礎上,做了強制約定:
1 同一層節點中,所有的葉子節點都調整的左邊

2 同一層節點,按照符號從小到達調整

注意看字符順序:


下邊來看哈夫曼樹編碼和範式哈夫曼樹編碼:**

範式哈夫曼樹編碼特性:
1 同層編碼遞增ADG:00 01 10 (方式+1)
2 不同層編碼推導方式:
上一層最後一個編碼+1 ,再左移層數差 例如下圖的 G 和 H
G 10
H 10 +1 -->11 再左移一位110
計算每個節點編碼,得知道碼字長度(高度)

範式哈夫曼樹創建過程(編碼獲取過程)
其實沒必要構建,直接處理哈夫曼樹就行了
1 模擬哈夫曼樹的創建(用靜態數組就行)
a 遍歷文件,獲取每個字符的出現頻度
b 創建靜態數組,容量 葉子數*2 -1
即 2n -1;
c 前n 個位置保存葉子

即用數組下標代替指針的鏈接關係(雙親指針)
1 每次取一個節點,通過parent(下標)直到根節點就可以獲取編碼長度了
2 排序:
以碼長爲第一關鍵字,字符序號爲第二關鍵字排序,得到一個序列(編碼長度表)
3 根據編碼長度表,獲取每個符號的編碼(可見範式Huffman樹和哈夫曼樹的**編碼長度**一致)
4 根據編碼,重新改寫文件
**編碼長度表:**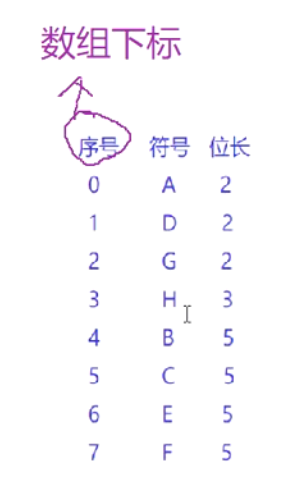
既然範式haffuman樹 和 哈夫曼樹的編碼長度一樣,那麼壓縮比率也將差不多,那麼GZIP採用範式哈夫曼樹?
1 範範式Huffman樹採用靜態數組,內部只保存雙親的下標,不用保存孩子下標節省空間。
2 範式哈夫曼樹 獲取編碼效率更快,不用多次遞歸獲取編碼
3 關於壓縮數據的保存更節省空間。
(只需要保存相應的碼字信息(長度))
看下圖

那麼每個字節的碼字長度(位長)怎麼保存?
方式一 :與Huffman 結合:

缺陷 ,字符種類多了,那麼需要的空間將很多
2n -1個空間
最壞 255 *2 -1 = 509 字節
方式二:
類似於哈希

沒出現的字符爲對應爲0,出現的字符對應爲出現次數,一個字節對應一個字符。
你可能也會想,這樣也未必節省空間了吧?弄不好也得255字節呢?
你想的對,真正的GZIP並不是完全的哈希方式保存碼字長度(位長)
採用一種遊程編碼的方式。
思想 ,沒出現的一大串0 ,想辦法壓縮短,就節省了空間。
什麼是遊程編碼?
對於一長串連續出現的數字,只寫個字符,緊接着記錄出現了多少次。
CL的遊程編碼 編碼的長度即CL也是一對數字,該部分信息理論也可以使用huffman樹再次壓縮,但是GZIP並沒有對其使用
huffman樹進行壓縮,而是使用了遊程編碼。 遊程,即一段完全相同的數的序列。
**遊程編碼,即對一段連續相同的數,記錄這個數一次,緊接着記錄出現
了多少個。**比如CL序列如下:
4, 4, 4, 4, 4, 3, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2 那麼,遊程編碼的結果爲:
4, 16, 01(二進制), 3, 3, 3, 6, 16, 11(二進制), 16, 00(二進制), 17,011(二進制), 2, 16, 00(二進 制)
這是什麼意思呢?
因爲CL的範圍是0-15,GZIP認爲重複出現2次太短就不用遊程編碼了,所以遊程長度從3開 始。
用16這個特殊的數表示重複出現3、4、5、6個這樣一個遊程,分別後面跟着00、01、10、11表示
(實 際存儲的時候需要低比特優先存儲,需要把比特倒序來存,博文的一些例子有時候會忽略這點,實際寫程序 的時候一定要注意,否則會得到錯誤結果)。
於是4,4,4,4,4,這段遊程記錄爲4,16,01,也就是說,4這個數, 後面還會連續出現了4次。6,16,11,16,00表示6後面還連續跟着6個6,再跟着3個6;
因爲連續的0出現的可能 很多,所以用17、18這兩個特殊的數專門表示0遊程,
17後面跟着3個比特分別記錄長度爲3-10(總共8種可 能)的遊程;
18後面跟着7個比特表示11-138(總共128種可能)的遊程。
17,011(二進制)表示連續出現6 個0;18,0111110(二進制)表示連續出現62個0。
總之記住
0-15是CL可能出現的值,16表示除了0以外的 其它遊程;17、18表示0遊程。
因爲二進制實際上也是個整數,所以的序列4, 4, 4, 4, 4, 3, 3, 3, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 0, 0, 0, 0, 0, 0, 2, 2, 2, 2 用整數表示爲:
4, 16, 1, 3, 3, 3, 6, 16, 3, 16, 0, 17, 3, 2, 16, 0
原字符和長度的編碼符號總共有286個(256個原字符+1個結束標記+29個長度區間),distance編碼區間總共 30個,因此這棵樹不會特別深,huffman編碼後的碼字長度不會特別長,不會超過15,即樹的深度不會超過 15,因此CL1和CL2這兩個序列的任意整數的值的範圍是0-15,0表示沒有出現,故GZIP對CL1和CL2使用了遊 程編碼。
因爲遊程編碼之後整數值的範圍是0-18,這個序列稱之爲SQ,因爲碼字長度有CL1、CL2,因此最後有SQ1 和SQ2兩組數據。GZIP採用第三個huffman樹對SQ1和SQ2再次進行huffman壓縮。通過統計各個整數(0- 18範圍內)的出現次數,按照相同的思路,對SQ1和SQ2進行了Huffman編碼,得到的碼流記爲SQ1 bits和 SQ2 bits。
同時,這裏又需要記錄第三個碼錶,稱爲Huffman碼錶3。同理,這個碼錶也用相同的方法記錄, 也等效爲一個碼長序列,稱爲CCL。到此GZIP壓縮纔算真正結束,這個算法命名爲Deflate算法:

Header:3個比特,第一個比特如果是1,表示此部分爲最後一個壓縮數據塊;否則表示這是.ZIP文件的某個 中間壓縮數據塊,但後面還有其他數據塊。這是ZIP中使用分塊壓縮的標誌之一;第2、3比特表示3個選擇: 壓縮數據中沒有使用Huffman、使用靜態Huffman、使用動態Huffman,這是對LZ77編碼後的 literal/length/distance進行進一步編碼的標誌。我們前面分析的都是動態Huffman,其實Deflate也支持靜 態Huffman編碼,靜態Huffman編碼原理更爲簡單,無需記錄碼錶(因爲PK自己定義了一個固定的碼錶), 但壓縮率不高,所以大多數情況下都是動態Huffman。
HLIT:5比特,記錄literal/length碼樹中碼長序列(CL1)個數的一個變量。後面CL1個數等於HLIT+257(因 爲至少有0-255總共256個literal,還有一個256表示解碼結束,但length的個數不定)。
HDIST:5比特,記錄distance碼樹中碼長序列(CL2)個數的一個變量。後面CL2個數等於HDIST+1。哪怕 沒有1個重複字符串,distance都爲0也是一個CL。
HCLEN:4比特,記錄Huffman碼錶3中碼長序列(CCL)個數的一個變量。後面CCL個數等於HCLEN+4。PK 認爲CCL個數不會低於4個,即使對於整個文件只有1個字符的情況。
接下來是3比特編碼的CCL,一共HCLEN+4個,用以構造Huffman碼錶3; 接下來是對CL1(碼長)序列經過遊程編碼(SQ1:縮短的整數序列)後,並對SQ1繼續用Huffman編碼後的
比特流。包含HLIT+257個CL1,其解碼碼錶爲Huffman碼錶3,用以構造Huffman碼錶1;
接下來是對CL2(碼長)序列經過遊程編碼(SQ2:縮短的整數序列)後,並對SQ2繼續用Huffman編碼後的 比特流。包含HDIST+1個CL2,其解碼碼錶爲Huffman碼錶3,用於構造Huffman碼錶2
6. 數據存儲格式
因爲被壓縮的文件可能非常大,會嚴重影響壓縮率,因此GZIP採用了分段壓縮處理,每段的壓縮結果表示如 下:


標記信息會影響壓縮效率, GZIP怎麼解決?

通過上述方式 ,
1 如果解壓出的是0~255 原字符
2 如果解壓縮期間,解除的是256, 代表解壓縮結束。
3 如果解壓縮的大於256,則表示解壓縮出的是長度,再根據Extra擴展,解壓出具體長度。
爲什麼設置爲256?
GZIP壓縮是分塊進行的
如果對整體進行統計時,統計出的字符次數理論上比較均勻,並且字符種類比較多,那麼構建的Huffman樹節點就比較多,高度也比較大,那麼到時候就不好存儲,對壓縮的比率有很大影響。
因此採用分塊壓縮
這個圖就是Huffman壓縮流程原理圖。