




從提交來一步一步分析,本文源碼基於Apache社區 1.8-release 版本
REST提交作業流程:
1.集羣啓動後 通過 /jars/upload 向集羣提交可執行jar文件
2.通過 /jars/:jarid/run 來啓動一個job
1.構建並提交JobGraph
我們直接找到WebSubmissionExtension這個類,在StandaloneSession 集羣模式下集羣初始化DispatcherRestEndpoint的時候會從WebSubmissionExtension里加載所有的Handlers(webSubmissionHandlers)
在WebSubmissionExtension中可以找到 /jars/:jarid/run 對應的Headers是JarRunHeaders,而接受http請求的是jarRunHandler。
Flink的rest服務是基於netty實現的,在jarRunHandler接受http請求後會調用handleRequest()方法來處理請求。
在handleRequest()方法的第一行如下,會從request中構造一個JarHandlerContext對象,而jobId就是JarHandlerContext對象的一個屬性。在之後的getJobGraphAsync()傳入的第一個參數就是context
在getJobGraphAsync()方法中調用context的toJobGraph()方法獲取jobGraph
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
內部版本當前判斷streamGraphPlan是否存在來執行不同的createJobGraph方法,區別在於是否傳入jobId。
社區版調用PackagedProgramUtils的createJobGraph()方法的時候會把JarHandlerContext的jobId屬性傳過去,隨後通過steamPlan(streamGraph)的getJobGraph()方法把jobId傳進去,之後調用StreamingJobGraphGenerator.createJobGraph()方法傳入this(streamGraph)和jobId,在new jobGraph時傳入jobId和jobName。
JobGraph的構造方法判斷jobId和jobName是否爲空,如果爲空新生成一個jobId實例,jobName則使用默認值"(unnamed job)"
JobGraph的構造方法:
|
1 2 3 4 5 6 7 8 9 10 11 |
|
在拿到jobGraph後進行一些後續處理然後向集羣提交job
|
1 2 3 4 5 |
|
集羣在接受jobGraph後,有如下的代碼:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
在internalSubmitJob()方法中調用waitForTerminatingJobManager()第一個參數就是jobId,隨後在異步執行完成後判斷時候有異常,在沒有異常即提交成功的情況下,調用cleanUpJobData()清理client在提交過程中的數據,清理的標識也是jobId
接着看waitForTerminatingJobManager()方法
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
其中getJobTerminationFuture()來判斷當前的jobId對應的job是否已在運行中,看方法名是在wait任務終止,實際在getJobTerminationFuture(),方法中並沒有終止任務的操作,只是判斷jobManagerRunnerFutures這個map中是否存在當前jobId。
|
1 |
|
jobManagerRunnerFutures看定義就可以瞭解,是持有運行中job的以jobId爲key,CompletableFuture<JobManagerRunner>爲value的映射關係。
繼續回到internalSubmitJob()方法,在waitForTerminatingJobManager()用::(jdk1.8特性)傳入了方法persistAndRunJob(),在該方法中先把jobGraph包裝成SubmittedJobGraph寫到zk中,然後調用runJob()方法,runJob()方法會先根據jobId判斷當前job是否已經提交,然後創建一個jobManagerRunner,接着把CompletableFuture<JobManagerRunner>放到名爲jobManagerRunnerFutures的Map裏,其中key就是jobId。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
繼續看createJobManagerRunner()方法,先異步的創建jobManagerRunner,然後執行startJobManagerRunner()方法,在確認jobManagerRunner後,執行start方法啓動jobManagerRunner。
在jobManagerRunner的start方法中,啓動zk選舉服務,讓自身(this)參與選舉獲得執行權,在zk確認後會回調grantLeadership()方法,jobManagerRunner實現了LeaderContender接口。
|
1 2 3 4 5 6 7 8 |
|
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
獲得執行權限後調用verifyJobSchedulingStatusAndStartJobManager()方法,先判斷job狀態,如果是DONE(finished),則已經finished,否則執行startJobMaster(),在startJobMaster()方法中先把job狀態設爲running,
把job和對應的狀態寫到zk。
如果需要實時的獲取job狀態可以用zk watch這個路徑
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
然後執行jobMasterService.start(),在jobMaster中 start()方法啓動RPC服務,然後startJobExecution來調度作業。
|
1 2 3 4 5 6 |
|
startJobExecution()方法如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
其中validateRunsInMainThread()使用斷言來確認調用是否發生在RPC endpoint 的主線程中,正常不會執行。然後判斷jobMasterId,並且確認當前jobMaster沒有調度過其他的job。接着到startJobMasterServices()方法,這個方法的主要作用是在調度作業之前啓動jobMaster相關的組件:
- 啓動心跳服務
- 啓動taskManager的slotPool RPC服務,確保接受當前jobMaster的調用和分配請求
- 啓動schedule
- 連接到resourceManager
在這些步驟執行完成之後,執行resetAndScheduleExecutionGraph()來開始調度executionGraph。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
|
首先判斷executionGraph的狀態是否爲create,如果不爲create會根據jobGraph創建新的executionGraph來代替當前的executionGraph,然後執行scheduleExecutionGraph(),
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
註冊想executionGraph作業狀態變更監聽器,執行executionGraph.scheduleForExecution(),先更新狀態從created到running,然後判斷調度模式,目前有兩種調度模式:
- LAZY_FROM_SOURCES
- EAGER
Eager 調度如其名子所示,它會在作業啓動時申請資源將所有的 Task 調度起來。這種調度算法主要用來調度可能沒有終止的流作業。與之對應,Lazy From Source 則是從 Source 開始,按拓撲順序來進行調度。簡單來說,Lazy From Source 會先調度沒有上游任務的 Source 任務,當這些任務執行完成時,它會將輸出數據緩存到內存或者寫入到磁盤中。然後,對於後續的任務,當它的前驅任務全部執行完成後,Flink 就會將這些任務調度起來。這些任務會從讀取上游緩存的輸出數據進行自己的計算。這一過程繼續進行直到所有的任務完成計算。

我們佔時可以先不考慮批程序,從流程序scheduleEager()繼續往下看,scheduleEager()方法有點長,我們先把這個方法貼出來一步一步來看。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 |
|
首先後驗證當前job的狀態,確認當前的job state確實爲running,否者拋出異常,job狀態先設置爲running然後纔開始調度的。接着從ExecutionJobVertex(以後簡稱ejv)開始遍歷分配slot,在ejv的allocateResourcesForAll()方法中其實又把ejv的ExecutionVertex(簡稱ev)遍歷一遍,然後取ev對應的Execution然後調用Execution的allocateAndAssignSlotForExecution()方法分配slot,具體分配算法之後單獨介紹。
在分配完slot之後,調用execution.deploy()方法來啓動部署。
streamGraph,jobGraph,executionGraph,ExecutionJobVertex,ExecutionVertex,Execution 的關係可以參考下圖:
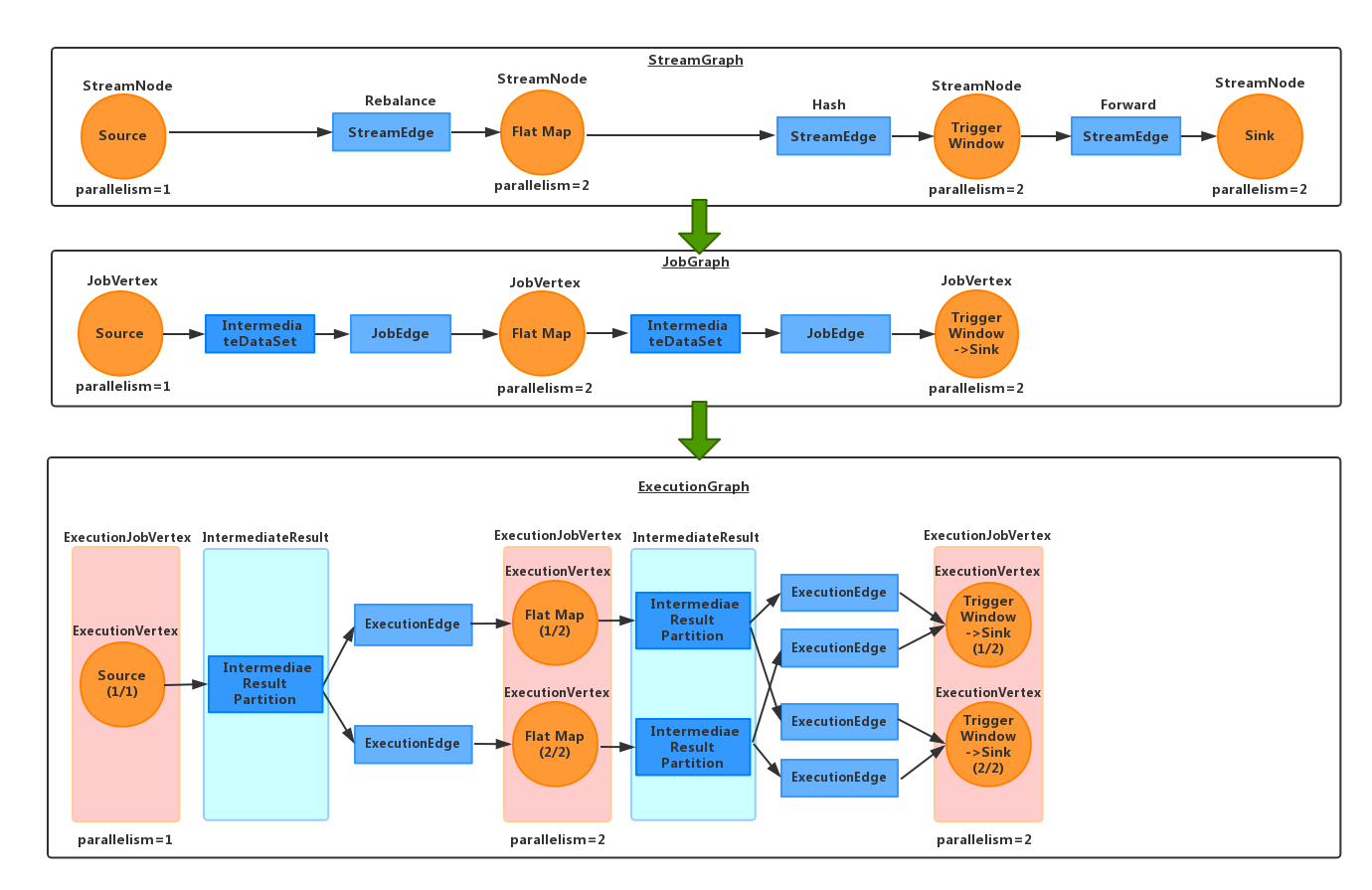
解析