




節點間的內部通信機制
基礎通信原理
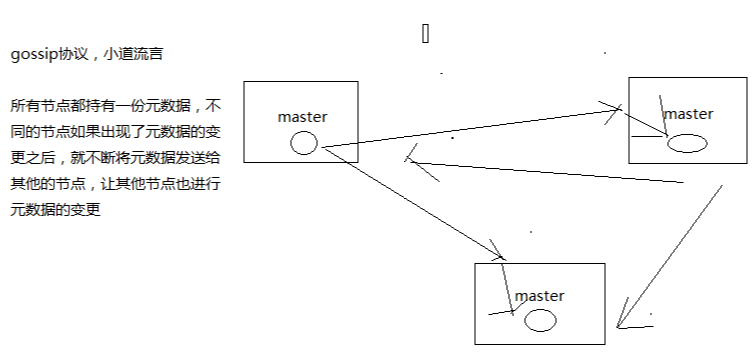
redis cluster 節點間採取 gossip 協議進行通信
gossip:互相之間不斷通信,保持整個集羣所有節點的數據是完整的
而集中式是將集羣元數據(節點信息,故障,等等)集中存儲在某個節點上;
經典的集中式中間件 zookeeper
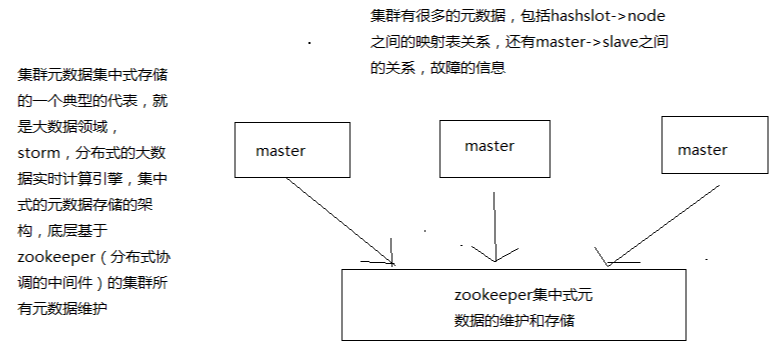
他們基本上都用於維護集羣的元數據
集中式:
-
優點:數據更新及時,時效好
元數據的更新和讀取,時效性非常好,一旦元數據出現了變更,立即就更新到集中式的存儲中,其他節點讀取的時候立即就可以感知到;
-
缺點:數據更新壓力集中
所有的元數據的跟新壓力全部集中在一個地方,可能會導致元數據的存儲有壓力
gossip:
-
優點:數據更新壓力分散
元數據的更新比較分散,不是集中在一個地方,更新請求會陸陸續續,打到所有節點上去更新,有一定的延時,降低了壓力;
-
缺點:數據更新延遲
元數據更新有延時,可能導致集羣的一些操作會有一些滯後
可見 集中式 與 gossip 的優缺點是相互的。
gossip 的延遲在我們上一章節中遷移 slots 時(reshard),去做另外一個操作,會發現 configuration error,需要等待一會才能達成一致,配置數據才能同步成功
10000 端口
每個節點都有一個專門用於節點間通信的端口,就是自己提供服務的端口號 + 10000,比如 7001,那麼用於節點間通信的就是 17001 端口
每個節點每隔一段時間都會往另外幾個節點發送 ping 消息,同時其他幾點接收到 ping 之後返回 pong
交換的信息
交換的信息有:故障信息、節點的增加和移除、hash slot 信息,等等
gossip 協議
gossip 協議包含多種消息,包括 ping、pong、meet、fail,等等
-
meet:
某個節點發送 meet 給新加入的節點,讓新節點加入集羣中,然後新節點就會開始與其他節點進行通信
redis-trib.rb add-node
其實內部就是發送了一個 gossip meet 消息,給新加入的節點,通知那個節點去加入我們的集羣
-
ping:
每個節點都會頻繁給其他節點發送 ping,其中包含自己的狀態還有自己維護的集羣元數據,互相通過 ping 交換元數據
每個節點每秒都會頻繁發送 ping 給其他的集羣,ping,頻繁的互相之間交換數據,互相進行元數據的更新
-
pong:
返回 ping 和 meet,包含自己的狀態和其他信息,也可以用於信息廣播和更新
-
fail:
某個節點判斷另一個節點 fail 之後,就發送 fail 給其他節點,通知其他節點,指定的節點宕機了
ping 消息深入
ping 很頻繁,而且要攜帶一些元數據,所以可能會加重網絡負擔
每個節點每秒會執行 10 次 ping,每次會選擇 5 個最久沒有通信的其他節點
當然如果發現某個節點通信延時達到了 cluster_node_timeout / 2,那麼立即發送 ping,避免數據交換延時過長,落後的時間太長了
比如說,兩個節點之間都 10 分鐘沒有交換數據了,那麼整個集羣處於嚴重的元數據不一致的情況,就會有問題
所以 cluster_node_timeout 可以調節,如果調節比較大,那麼會降低發送的頻率
每次 ping,一個是帶上自己節點的信息,還有就是帶上 1/10 其他節點的信息,發送出去,進行數據交換
至少包含 3 個其他節點的信息,最多包含總節點 -2 個其他節點的信息
面向集羣的 jedis 內部實現原理
後面會使用 jedis,它是 redis 的 java client 客戶端,支持 redis cluster
這裏會講解 jedis cluster api 與 redis cluster 集羣交互的一些基本原理
基於重定向的客戶端
redis-cli -c,可以提供自動重定的功能,那麼對於 jedis 來說,下面是他的實現原理
請求重定向
客戶端可能會挑選任意一個 redis 實例去發送命令,每個 redis 實例接收到命令,都會計算 key 對應的 hash slot
如果在本地就在本地處理,否則返回 moved 給客戶端,讓客戶端進行重定向
cluster keyslot mykey,可以查看一個 key 對應的 hash slot 是什麼
[root@eshop-cache01 ~]# redis-cli -h 192.168.99.170 -p 7001
192.168.99.170:7001> cluster keyslot myke1
(integer) 12435
192.168.99.170:7001> cluster keyslot myke2
(integer) 240
用 redis-cli 的時候,可以加入 -c 參數,支持自動的請求重定向,redis-cli 接收到 moved 之後,會自動重定向到對應的節點執行命令
但是這樣會有一個問題,可能會出現大部分命令都會接受到 moved 響應,也就是說可能一次寫入會有兩次請求,這個就很浪費性能
計算 hash slot
計算 hash slot 的算法,就是根據 key 計算 CRC16 值,然後對 16384 取模,拿到對應的 hash slot
用 hash tag 可以手動指定 key 對應的 slot,同一個 hash tag 下的 key,都會在一個 hash slot 中,比如 set mykey1:{100} 和 set mykey2:{100}
192.168.99.170:7001> set mykey1:{100} 1
OK
192.168.99.170:7001> set mykey2:{100} 2
OK
192.168.99.170:7001> set mykey1 1
OK
192.168.99.170:7001> set mykey2 2
(error) MOVED 14119 192.168.99.172:7005
192.168.99.170:7001> get mykey2
(error) MOVED 14119 192.168.99.172:7005
192.168.99.170:7001> get mykey2:{100}
"2"
可以看到,這個 tag 相當於你手動指定這個 key 路由到哪一個 solt 上去,那麼只要手動了,以後查詢也需要手動指定纔行,所以這裏需要先計算出 hash slot 的值,相當於在 redis 服務端的工作挪動到客戶端來做了,這樣減少了大量的 moved 請求
hash slot 查找
節點間通過 gossip 協議進行數據交換,就知道每個 hash slot 在哪個節點上
smart jedis
什麼是 smart jedis
基於重定向的客戶端,很消耗網絡 IO,因爲大部分情況下,可能都會出現一次請求重定向,才能找到正確的節點
所以大部分的客戶端,比如 java redis 客戶端(jedis),就是 smart 的
本地維護一份 hashslot -> node 的映射表,緩存起來,大部分情況下,直接走本地緩存就可以找到 hashslot -> node,不需要通過節點進行 moved 重定向
JedisCluster 的工作原理
-
在 JedisCluster 初始化的時候,就會隨機選擇一個 node,初始化 hashslot -> node 映射表,同時爲每個節點創建一個 JedisPool 連接池
-
每次基於 JedisCluster 執行操作,首先 JedisCluster 都會在本地計算 key的 hashslot,然後在本地映射表找到對應的節點
-
如果那個 node 正好還是持有那個 hashslot,那麼就 ok; 如果說進行了 reshard 這樣的操作,可能 hashslot 已經不在那個 node 上了,就會返回 moved
-
如果 JedisCluter API 發現對應的節點返回 moved,那麼利用該節點的元數據,更新本地的 hashslot -> node 映射表緩存
重複上面幾個步驟,直到找到對應的節點,如果重試超過 5 次,那麼就報錯 JedisClusterMaxRedirectionException
jedis 老版本,可能會出現在集羣某個節點故障還沒完成自動切換恢復時,頻繁更新 hash slot,頻繁 ping 節點檢查活躍,導致大量網絡 IO 開銷
jedis 最新版本,對於這些過度的 hash slot 更新和 ping,都進行了優化,避免了類似問題
hashslot 遷移和 ask 重定向
如果 hash slot 正在遷移,那麼會返回 ask 重定向給 jedis
jedis 接收到 ask 重定向之後,會重新定位到目標節點去執行,但是因爲 ask 發生在 hash slot 遷移過程中,所以 JedisCluster API 收到 ask 是不會更新 hashslot 本地緩存
已經可以確定 hashslot 已經遷移完了,訪問會返回 moved, 那麼是會更新本地 hashslot->node 映射表緩存的
高可用性與主備切換原理
redis cluster 的高可用的原理,幾乎跟哨兵是類似的
-
判斷節點宕機
如果一個節點認爲另外一個節點宕機,那麼就是 pfail,主觀宕機
如果多個節點都認爲另外一個節點宕機了,那麼就是 fail,客觀宕機,跟哨兵的原理幾乎一樣,sdown、odown
在 cluster-node-timeout 內,某個節點一直沒有返回 pong,那麼就被認爲 pfail
如果一個節點認爲某個節點 pfail 了,那麼會在 gossip ping 消息中,ping 給其他節點,如果超過半數的節點都認爲 pfail 了,那麼就會變成 fail
-
從節點過濾
對宕機的 master node,從其所有的 slave node 中,選擇一個切換成 master node
檢查每個 slave node 與 master node 斷開連接的時間,如果超過了 cluster-node-timeout * cluster-slave-validity-factor,那麼就沒有資格切換成 master
這個也是跟哨兵是一樣的,從節點超時過濾的步驟
-
從節點選舉
哨兵:對所有從節點進行排序,slave priority,offset,run id
每個從節點,都根據自己對 master 複製數據的 offset,來設置一個選舉時間,offset 越大(複製數據越多)的從節點,選舉時間越靠前,優先進行選舉
所有的 master node 開始 slave 選舉投票,給要進行選舉的 slave 進行投票,如果大部分 master node(N/2 + 1)都投票給了某個從節點,那麼選舉通過,那個從節點可以切換成 master
從節點執行主備切換,從節點切換爲主節點
與哨兵比較
整個流程跟哨兵相比,非常類似,所以說,redis cluster 功能強大,直接集成了 replication 和 sentinal 的功能
沒有辦法去給大家深入講解 redis 底層的設計的細節,核心原理和設計的細節,那個除非單獨開一門課,redis 底層原理深度剖析,redis 源碼
對於咱們這個架構課來說,主要關注的是架構,不是底層的細節,對於架構來說,核心的原理的基本思路,是要梳理清晰的