




IM需要在其中一个分区进行线上全链路压测,模拟100w终端用户连接,并根据线上各websocket和http请求按照比例qps x2并发请求。通宵达旦赶项目1周,但是很多问题仍未找到答案,不过先记录mark一下过程的问题
测试链路
jmeter - SLB(2) - nginx(4) - ingress(5) - pod - im服务
测试场景
- 模拟100w终端保持心跳并接收消息
- 模拟ws和http群聊(发送群聊,广播消息到该群组中所有用户)
- 模拟其他非广播ws和http请求
单肉鸡模拟终端连接数
在一台8核 16g的肉鸡中,可以模拟多大的终端数?
-
模拟2w连接时,连接数无法上升到2w,仅能连接成功6k左右,jmeter返回大量的
end of stream
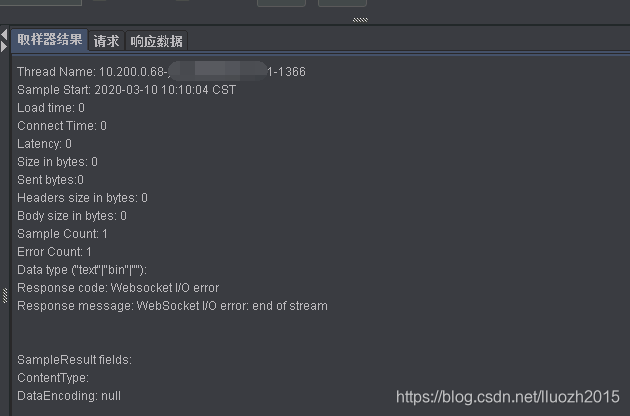 -
调整肉鸡的配置信息
net.ipv4.tcp_max_tw_buckets = 200000
net.ipv4.tcp_max_syn_backlog = 65535
net.ipv4.ip_local_port_range = 11000 61000
fs.file-max = 1000000
net.ipv4.ip_conntrack_max = 2000000
net.ipv4.netfilter.ip_conntrack_max = 2000000
net.nf_conntrack_max = 2000000
net.netfilter.nf_conntrack_max = 2000000
net.ipv4.tcp_max_orphans = 500000
net.ipv4.tcp_mem = 786432 2097152 3145728
net.ipv4.tcp_rmem = 4096 4096 16777216
net.ipv4.tcp_wmem = 4096 4096 16777216
此时连接数可以上到1w
-
保持1w的终端连接,可以长时间的正常连接并保持心跳,但在接收群聊广播的消息时,仍出现
end of stream和16g内存跑满等问题 -
同时在模拟发送请求时,出现jmeter 出现
WebSocket I/O error: Read timed out的报错信息,将源码打印日志并build打包时,又出现了另外一个local class incompatible的错误
![在这里插入图片描述]()
增加serialVersionUID的强制定义private static final long serialVersionUID = -4014547742856395088L;,发现仍然报此错误,后面发现是因为控制端和肉鸡的ws jar包版本不一致导致此问题的出现 -
在JMeter WebSocket Samplers源码issue中作者也提及这些问题在1.2.26版本github issue中已解决
![在这里插入图片描述]()
确实有一定的改善,但是模拟1.5w终端时仍有少量的错误 -
此时连接数仍不能达到1.5w,从链路中排查问题,发现单SLB个连接数能达到1w,使用2个SLB连接数仍然为1w,定位是此时连接的是阿里外网的SLB导致
-
模拟1.5w终端连接后,模拟ws发送群聊消息,各个终端接收广播的消息,jmeter又出现
end of stream和read timeout的问题,定位问题可能是因为读帧的问题
![在这里插入图片描述]()
在jmeter脚本中增加WebSocket Single Read Sampler接收数据包,上面问题得到一定的缓解,但仍会出现 -
单个肉鸡模拟1w终端连接,试验后并没有问题,可正常保持心跳并接收广播信息,稳妥起见,最终决定单个肉鸡模拟1w连接



100w终端连接
- 模拟50w终端连接(50台肉鸡,每台模拟1w终端),使用的是GUI模式,此时控制端卡死,只能在各个肉鸡非GUI模式全部运行
JVM_ARGS="-Xms6g -Xmx6g" /root/apache-jmeter-5.1.1/bin/jmeter -n -t /root/apache-jmeter-5.1.1/bin/im_enter_room.jmx &
-
模拟50w终端连接,模拟ws群聊(tps2200,广播下行包数量3000w/min),长时间运行(>1h)并没有任何问题(此时jmeter、nginx、服务均正常)
-
在步骤1的基础上,增加连接50w用户,此时新增的50w用户仅连接成功25w左右,多次试验均为此数值,排查发现一个终端nginx需要保持2个连接,每个连接需要4个worker_connections,现在有8个8核的nginx(每个SLB4个),nginx中worker_connections的值为10w,那么能够支持的连接数刚好是80w,将worker_connections的值修改为100w,连接数可正常达到100w
如果nginx 中worker_connections 值设置是1024,worker_processes 值设置是4,按反向代理模式下最大连接数的理论计算公式:
最大连接数 = worker_processes * worker_connections/4
-
正常连接100w终端后,进行模拟ws群聊时,出现大批量的掉线,nginx在短时间内OOM
![在这里插入图片描述]()
且jmeter端报错为
there is no connection to re-use 2020-03-12 00:02:09,587 ERROR e.l.j.w.SingleReadWebSocketSampler: Sampler 'WebSocket Single Read Sampler': there is no connection to re-use -
经过理论和实践,对配置信息进行调整如下
proxy_buffer
针对单个连接的资源配额需要管控,一个最快改动方式是把 proxy_buffering 设置为 off。在压测环境修改了这个值以后,以及调小了 proxy_buffer_size的值以后,内存稳定在了 20G 左右,没有再飙升过。后续可以开启 proxy_buffering,调整proxy_buffers 的大小可以在内存消耗和性能方面取得更好的平衡
worker_connections
前面也提到将worker_connections的值设置为100w,但是100w需要预先分配大量的内存,将nginx升级配置16核,并将worker_connections的值设置为10w,按照计算可以支撑160w连接
配置为1个SLB(支持100w并发连接)-> 4个nginx(32C 64G) ->5个ingress(32C 64G)
nginx的net.ipv4.ip_local_port_range
服务器某个端口可以连接的最大tcp数量是由四元组成:src_ip(本地ip),src_port(本地端口),dst_ip(客户端ip),dst_port(客户端端口)
理论上在src_ip,src_port固定的情况下,一个客户端Ip理论上最多有65535个连接数。ip_local_port_range这个参数控制的就是dst_port的范围
4个nginx和5个ingress,那么将dst_port的值设置为1024-65536,理论上可以支撑的连接数(65535-1024)* 5 *4 = 120w
worker_rlimit_nofile
进程的最大打开文件数限制,这样nginx就不会有“too many open files”问题了。不能超过最大文件打开数在linux终端中输入ulimit -a进行查看
![在这里插入图片描述]()


业务请求
可进行ws群聊(tps2200)和http群聊(wps1000)测试,但增加ws获取房间历史消息和获取成员列表的接口请求时,,nginx内存飙升,短时间内OOM
抓包发现jmeter肉鸡出现大量零窗口,同时使用命令 ss -nt 发现每个端口缓存在持续飙升,这两个接口返回的数据量太大导致jmeter发送请求端肉鸡端口缓存飙升,同时拖垮nginx,降低请求tps已经增加等待时间等操作后,可正常请求,并达到预期的效果

