




1. B+樹
爲了加速數據庫中數據的查找速度,常用的處理思路是,對錶中數據創建索引。數據庫索引是如何實現的呢?底層使用的是什麼數據結構和算法呢?
數據庫查詢需求:
- 根據某個值查找數據,比如 select * from user where id=1234;
- 根據區間值來查找某些數據,比如 select * from user where id > 1234 and id < 2345。
即單值查找和區間查找。
除了這些功能性需求之外,這種問題往往還會涉及一些非功能性需求,比如安全、性能、用戶體驗等。對於非功能性需求,我們着重考慮性能方面的需求。性能方面的需求,我們主要考察時間和空間兩方面,也就是執行效率和存儲空間。
在執行效率方面,我們希望通過索引,查詢數據的效率儘可能的高;在存儲空間方面,我們希望索引不要消耗太多的內存空間。
支持快速查詢、插入等操作的動態數據結構
有散列表、平衡二叉查找樹、跳錶。
散列表。散列表的查詢性能很好,時間複雜度是 O(1)。但是,散列表不能支持按照區間快速查找數據。所以,散列表不能滿足我們的需求。
平衡二叉查找樹。儘管平衡二叉查找樹查詢的性能也很高,時間複雜度是 O(logn)。而且,對樹進行中序遍歷,我們還可以得到一個從小到大有序的數據序列,但這仍然不足以支持按照區間快速查找數據。
跳錶。跳錶是在鏈表之上加上多層索引構成的。它支持快速地插入、查找、刪除數據,對應的時間複雜度是 O(logn)。並且,跳錶也支持按照區間快速地查找數據。我們只需要定位到區間起點值對應在鏈表中的
結點,然後從這個結點開始,順序遍歷鏈表,直到區間終點對應的結點爲止,這期間遍歷得到的數據就是滿足區間值的數據。

這樣看來,跳錶是可以解決這個問題。實際上,數據庫索引所用到的數據結構跟跳錶非常相似,叫作 B+ 樹。不過,它是通過二叉查找樹演化過來的,而非跳錶。
二叉查找樹改造成 B+ 樹
改造二叉查找樹爲B+樹
爲了讓二叉查找樹支持按照區間來查找數據,我們可以對它進行這樣的改造:
樹中的節點並不存儲數據本身,而只是作爲索引。除此之外,我們把每個葉子節點串在一條鏈表上,鏈表中的數據是從小到大有序的。經過改造之後的二叉樹,就像圖中這樣,看起來是不是很像跳錶呢?

B+ 樹中,將葉子節點串起來的鏈表,是單鏈表還是雙向鏈表?爲什麼?
對於B+tree葉子節點,是用雙向鏈表還是用單鏈表,得從具體的場景思考。
數據庫查詢,都遇到過升序或降序問題,即類似這樣的sql: select name,age, ... from user where uid > 10 and uid < 100 order by uid asc(或者desc),此時,數據底層實現有兩種做法:
- 1)保證查出來的數據就是用戶想要的順序
- 2)不保證查出來的數據的有序性,查出來之後再排序
以上兩種肯定選第一種,因爲第二種做法浪費了時間(如果選用內存排序,還是考慮數據的量級)。那如何能保證查詢出來的數據就是有序的呢?單鏈表肯定做不到,只能從頭往後遍歷,只能選擇雙向鏈表了。
雙向鏈表,多出來了一倍的指針,會多佔用空間。可是,數據庫索引本身都已經在磁盤中了,對於磁盤來說,這點空間已經微不足道了,用空間換來時間。
在實際工程應用中,雙向鏈表應用的場景非常廣泛,畢竟能大量減少鏈表的遍歷時間。
改造之後,如果我們要求某個區間的數據。只需要拿區間的起始值,在樹中進行查找,當查找到某個葉子節點之後,再順着鏈表往後遍歷,直到鏈表中的結點數據值大於區間的終止值爲止。所有遍歷到的
數據,就是符合區間值的所有數據。

索引的存儲問題
但是,要爲幾千萬、上億的數據構建索引,如果將索引存儲在內存中,儘管內存訪問的速度非常快,查詢的效率非常高,但是,佔用的內存會非常多。
比如,給一億個數據構建二叉查找樹索引,那索引中會包含大約 1 億個節點,每個節點假設佔用 16 個字節,那就需要大約 1GB 的內存空間。給一張表建立索引,我們需要 1GB 的內存空間。如果我們要給 10
張表建立索引,那對內存的需求是無法滿足的。如何解決這個索引佔用太多內存的問題?
藉助時間換空間的思路,把索引存儲在硬盤中,而非內存中。硬盤是一個非常慢速的存儲設備。通常內存的訪問速度是納秒級別的,而磁盤訪問的速度是毫秒級別的。讀取同樣大小的數據,從磁盤中讀
取花費的時間,是從內存中讀取所花費時間的上萬倍,甚至幾十萬倍。這種將索引存儲在硬盤中的方案,減少了內存消耗,但在數據查找過程中,需要讀取磁盤中的索引,因此數據查詢效率就相應降低很多。
二叉查找樹,改造後,支持區間查找的功能就實現了。爲節省內存,如果把樹存儲在硬盤中,那麼每個節點的讀取(或者訪問),都對應一次磁盤 IO 操作。樹的高度就等於每次查詢數據時磁盤 IO 操作的次數。
磁盤IO的優化
比起內存讀寫操作,磁盤 IO 操作非常耗時,所以我們優化的重點就是儘量減少磁盤 IO 操作,也就是,儘量降低樹的高度。那如何降低樹的高度呢?
如果我們把索引構建成 m 叉樹,高度是不是比二叉樹要小呢?如圖所示,給 16 個數據構建二叉樹索引,樹的高度是 4,查找一個數據,就需要 4 個磁盤 IO 操作(如果根節點存儲在內存中,其他結點存儲在磁
盤中),如果對 16 個數據構建五叉樹索引,那高度只有 2,查找一個數據,對應只需要 2 次磁盤操作。如果 m 叉樹中的 m 是 100,那對一億個數據構建索引,樹的高度也只是 3,最多隻要 3 次磁盤 IO 就能獲
取到數據(100的4次方是1億,第一層的索引節點可以放到內存中,就是3次IO操作 )。磁盤 IO 變少了,查找數據的效率也就提高了。


將 m 叉樹實現 B+ 樹索引,用代碼實現出來,(假設我們給 int 類型的數據庫字段添加索引,所以代碼中的 keywords 是 int 類型的):
/**
* 這是 B+ 樹非葉子節點的定義。
*
* 假設 keywords=[3, 5, 8, 10] keywords字段爲int類型,給它添加索引;
* 4 個鍵值將數據分爲 5 個區間:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5 個區間分別對應:children[0]...children[4]
*
* m 值(m叉樹)是事先計算得到的,計算的依據是讓所有信息的大小正好等於頁的大小:
* PAGE_SIZE = ( m - 1 ) * 4 [keywordss 大小] + m * 8 [children 大小]
*/
public class BPlusTreeNode {
public static int m = 5; // 5 叉樹
public int[] keywords = new int[m-1]; // 鍵值,用來劃分數據區間
public BPlusTreeNode[] children = new BPlusTreeNode[m];// 保存子節點指針
}
/**
* 這是 B+ 樹中葉子節點的定義。
*
* B+ 樹中的葉子節點跟內部結點是不一樣的,
* 葉子節點存儲的是值,而非區間。
* 這個定義裏,每個葉子節點存儲 3 個數據行的鍵值及地址信息。
*
* k 值是事先計算得到的,計算的依據是讓所有信息的大小正好等於頁的大小:
* PAGE_SIZE = k * 4 [keyw.. 大小] + k*8 [dataAd.. 大小] + 8[prev 大小] + 8[next 大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 數據的鍵值
public long[] dataAddress = new long[k]; // 數據地址
public BPlusTreeLeafNode prev; // 這個結點在鏈表中的前驅結點
public BPlusTreeLeafNode next; // 這個結點在鏈表中的後繼結點
}
對於相同個數的數據構建 m 叉樹索引,m 叉樹中的 m 越大,那樹的高度就越小,那 m 叉樹中的 m 是不是越大越好呢?到底多大才最合適呢 ?
不管是內存中的數據,還是磁盤中的數據,操作系統都是按頁(一頁大小通常是 4KB,這個值可以通過 getconfig PAGE_SIZE 命令查看)來讀取的,一次會讀一頁的數據。如果要讀取的數據量超過一頁的大
小,就會觸發多次 IO 操作。所以,我們在選擇 m 大小的時候,要儘量讓每個節點的大小等於一個頁的大小。讀取一個節點,只需要一次磁盤 IO 操作。
葉子節點存對象,對象包含key和data。 數據是存儲在葉子節點指向的磁盤地址

插入操作
儘管索引可以提高數據庫的查詢效率,索引有利也有弊,它也會讓寫入數據的效率下降。
數據的寫入過程,會涉及索引的更新,這是索引導致寫入變慢的主要原因。
對於一個 B+ 樹來說,m 值是根據頁的大小事先計算好的,也就是說,每個節點最多隻能有 m 個子節點。在往數據庫中寫入數據的過程中,這樣就有可能使索引中某些節點的子節點個數超過 m,這個節點的大
小超過了一個頁的大小,讀取這樣一個節點,就會導致多次磁盤 IO 操作。如何解決這個問題呢?
實際上,處理思路並不複雜。只需要將這個節點分裂成兩個節點。但是,節點分裂之後,其上層父節點的子節點個數就有可能超過 m 個。不過這也沒關係,可以用同樣的方法,將父節點也分裂成兩個節點。這
種級聯反應會從下往上,一直影響到根節點。
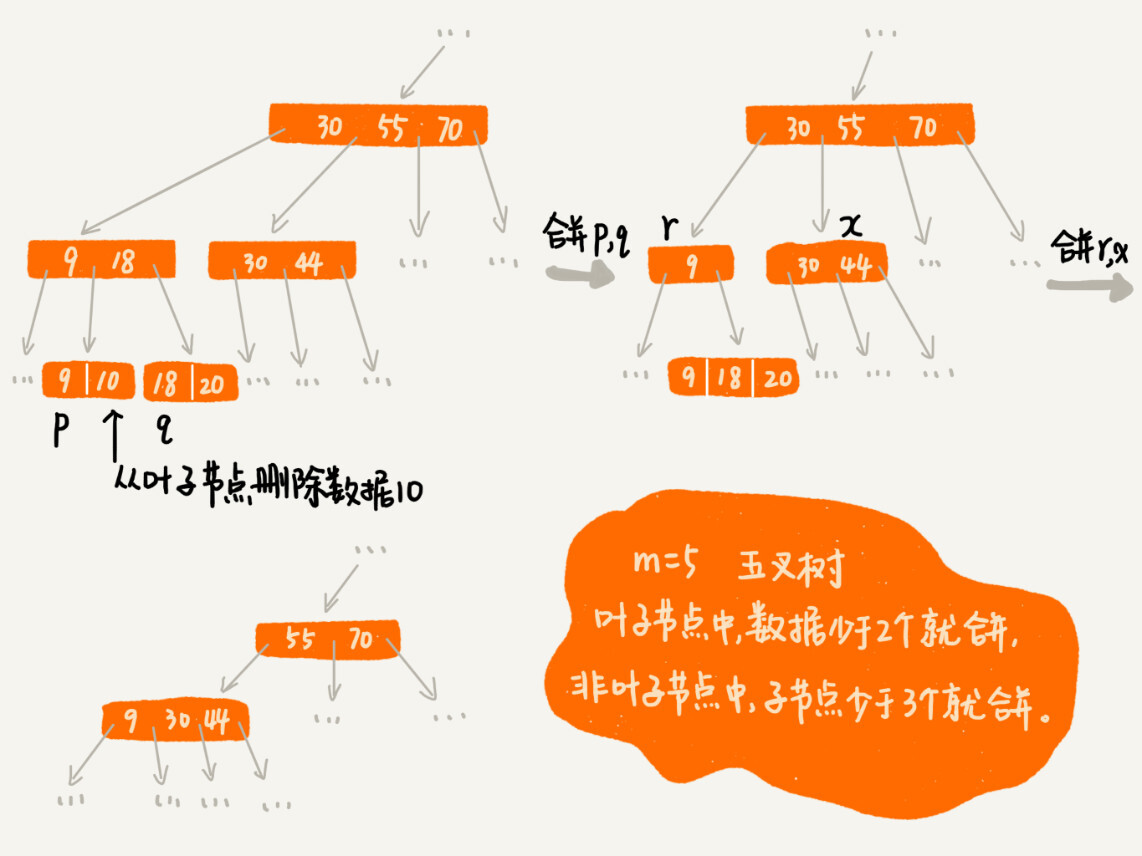
分裂過程如下,(圖中的 B+ 樹是一個三叉樹。限定葉子節點中,數據的個數超過 2 個就分裂節點;非葉子節點中,子節點的個數超過 3 個就分裂節點)。

刪除操作
正是因爲要時刻保證 B+ 樹索引是一個 m 叉樹,所以,索引的存在會導致數據庫寫入的速度降低。實際上,不光寫入數據會變慢,刪除數據也會變慢。
我們在刪除某個數據的時候,也要對應的更新索引節點。這個處理思路有點類似跳錶中刪除數據的處理思路。頻繁的數據刪除,就會導致某些結點中,子節點的個數變得非常少,長此以往,如果每個節點的子節
點都比較少,勢必會影響索引的效率。
我們可以設置一個閾值。在 B+ 樹中,這個閾值等於 m/2。如果某個節點的子節點個數小於 m/2,我們就將它跟相鄰的兄弟節點合併。不過,合併之後結點的子節點個數有可能會超過 m。針對這種情況,藉助插入數據時候的處理方法,再分裂節點。
刪除操作如下:(圖中的 B+ 樹是一個五叉樹。我們限定葉子節點中,數據的個數少於 2 個就合併節點;非葉子節點中,子節點的個數少於 3 個就合併節點。)
 img
img
B+ 樹的結構和操作,跟跳錶非常類似。理論上講,對跳錶稍加改造,也可以替代 B+ 樹,作爲數據庫的索引實現的。
B+ 樹發明於 1972 年,跳錶發明於 1989 年,跳錶的作者有可能就是受了 B+ 樹的啓發,才發明出跳表來的。
B+樹總結
數據庫索引實現,依賴的底層數據結構,B+ 樹。通過存儲在磁盤的多叉樹結構,做到了時間、空間的平衡,既保證了執行效率,又節省了內存。
B+ 樹的特點:
- 每個節點中子節點的個數不能超過 m,也不能小於 m/2;
- 根節點的子節點個數可以不超過 m/2,這是一個例外;
- m 叉樹只存儲索引,並不真正存儲數據,這個有點兒類似跳錶;
- 通過鏈表將葉子節點串聯在一起,這樣可以方便按區間查找;
- 一般情況,根節點會被存儲在內存中,其他節點存儲在磁盤中。
除了 B+ 樹,還有 B 樹、B- 樹。實際上,B- 樹就是 B 樹,英文翻譯都是 B-Tree,這裏的“-”並不是相對 B+ 樹中的“+”,而只是一個連接符。這個很容易誤解。
而 B 樹實際上是低級版的 B+ 樹,或者說 B+ 樹是 B 樹的改進版。B 樹跟 B+ 樹的不同點主要集中在這幾個地方:
- B+ 樹中的節點不存儲數據,只是索引,而 B 樹中的節點存儲數據;
- B 樹中的葉子節點並不需要鏈表來串聯。
也就是說,B 樹只是一個每個節點的子節點個數不能小於 m/2 的 m 叉樹。
B+tree的理解抓住幾個要點:
- 1. 理解二叉查找樹
- 2. 理解二叉查找樹會出現不平衡的問題(紅黑樹理解了,對於平衡性這個關鍵點就理解了)
- 3. 磁盤IO訪問太耗時
- 4. 當然,鏈表知識跑不了 —— 別小瞧這個簡單的數據結構,它是鏈式結構之母
- 5. 最後,要知道典型的應用場景:數據庫的索引結構的設計
對平衡二叉查找樹進行改造,將葉子節點串在鏈表中,就支持了按照區間來查找數據。散列表也經常跟鏈表一塊使用,如果把散列表中的結點,也用鏈表串起來,能否支持按照區間查找數據呢?
可以支持區間查詢。java中linkedHashMap就是鏈表+HashMap的組合,用於實現緩存的lru算法比較方便,不過要支持區間查詢需要在插入時維持鏈表的有序性,複雜度O(n).效率比跳錶和b+tree差
JDK中的LinkedHashMap爲了能做到保持節點的順序(插入順序或者訪問順序),就是用雙向鏈表將節點串起來的。
什麼數據結構可以做到O(logn)的範圍查詢?
跳錶,B+樹,數據庫索引確實也是用的B+樹。
那麼問題來了,跳錶和B+樹在實現難度和性能上有什麼區別,在數據量很大的情況下,表現性能如何,爲什麼redis選跳錶?
B+樹主要是用在外部存儲上,爲了減少磁盤IO次數。
跳錶比較適合內存存儲。
實際上,兩者本質的設計思想是雷同的,性能差距還是要具體看應用場景,無法從時間複雜度這麼寬泛的度量標準來度量了。
2. 索引
索引的需求定義
對於系統設計需求,一般可以從功能性需求和非功能性需求兩方面來分析。
1. 功能性需求
對於功能性需求大致要考慮以下幾點。
數據是格式化的還是非格式化數據?要構建索引的原始數據,類型很多。分爲兩類,一類是結構化數據,比如MySQL中的數據;另一類是非結構化數據,比如搜索引擎中的網頁。對於非結構化數據,我們一般
需要做預處理,提取出查詢關鍵詞,對關鍵詞構建索引。
數據是靜態數據還是動態數據?如果原始是一組靜態數據,也就是說,不會有數據的增加、刪除、更新操作,所以,我們在構建索引的時候,只需要考慮查詢效率就可以了。這樣,索引的構建就相對簡單些。不過,大部分情況下,都是對動態數據構建索引,也就是說,我們不僅要考慮到索引的查詢效率,在原始數據更新時,我們還需要動態的更新索引。支持動態數據集合的索引,設計越來相對更復雜些。
索引是存儲在內存還是硬盤?如果索引存儲在內存中,那技術要求的速度肯定要比存儲的磁盤中的高。但是,如果原始數據量很大的情況下,對應的索引可能也會很大。這個時候,因爲內存有限,我們可能就不得不將索引存儲在硬盤中了。實際上,還有第三種情況,那就是一部分存儲在內存,一部分存儲在磁盤,這樣就可以兼顧內存消耗和查詢效率。
單值查找還是區間查找?所謂單值查找,也就是根據查詢關鍵詞等於某個值的數據。這種查詢需求最常見。所謂區間查找,就是查找關鍵詞處於某個區間值的所有數據。實際上,不同的應用場景,查詢的需求會多種多樣。
單關鍵詞查找還是多關鍵詞組合查找?比如,搜索引擎中構建的索引,既要支持一個關鍵詞的查找,比如“數據結構”,也要支持組合關鍵詞查找,比如“數據結構 AND算法”。對於單關鍵詞查找,索引構建起來相
對簡單些。對於多關鍵詞查找來說,要分多種情況。像MySQL這種結構化數據的查詢需求,我們可以實現針對多個關鍵詞組合,建立索引;對於像搜索引擎這樣的非結構數據的查詢需求,我們可以針對間個關
鍵詞構建索引,然後通過集合操作,比如求並集、求交集等,計算出多個關鍵詞組合的查詢結果。
實際上,不同的場景,不同的原始數據,對於索引的需求也會千差萬別。
2.非功能性需求
不管是存儲在內存中還是磁盤中,索引對存儲空間的消耗不能過大。如果存儲在內存中,索引對佔用存儲空間的限制就會非常苛刻。畢竟內存空間非常有限,一箇中間件啓動後就佔用幾個GB的內存,開發者顯
然是無法接受的。如果存儲在硬盤中,那索引對佔用存儲空間的限制,稍微會放寬一些。但是,我們也不能掉以輕心。因爲,有時候,索引對存儲空間消耗會超過數據。
在考慮索引查詢效率的同時,我們還是考慮索引的維護成本。索引的目的是提高查詢效率,但是,基於動態數據集合構建的索引,我們還要考慮到索引的維護成本。因爲在原始數據動態增刪改的同時,我們也需
要動態的更新索引。而索引的更新勢必會影響到增刪改的操作性能。
構建索引常用的數據結構
實際上,常用來構建索引的數據結構,即支持動態數據集合的數據結構。比如,散列表、紅黑樹、跳錶、B+樹。除此之外,位圖、布隆過濾器可以作爲輔助索引,有序數組可以用來對靜態數據構建索引。
① 散列表增刪改查操作的性能非常好,時間複雜度是O(1)。一些鍵值數據庫,比如Redis、Memcache,就是使用散列表來構建索引的。這類索引,一般都構建在內存中。
② 紅黑樹作爲一種常用的平衡二叉查找樹,數據插入、刪除、查找的時間複雜度是O(logn),也非常適合用來構建內存索引。Ext文件系統中,對磁盤塊的索引,用的就是紅黑樹。
③ B+ 樹比起紅黑樹來說,更加適合構建存儲在磁盤的索引。B+樹是一個多叉樹,所以,以相同個數的數據構建索引,B+樹的高度要低於紅黑樹。當藉助索引查詢數據的時候,讀取B+樹索引,需要的磁盤IO次
數更少。所以,大部分關係型數據庫的索引,比如MySQL、Oracle,都是用B+樹來實現的。
④ 跳錶也支持快速添加、刪除、查找數據。而且,我們通過靈活調整索引結點個數和數據個數之間的比例,可以很好的平衡對內存的消耗及其查詢效率。Redis中的有序集合,就是用跳錶來構建的。
⑤ 位圖和布隆過濾器這兩個數據結構,也可以用於索引中,輔助存儲在磁盤中的索引,加速數據查詢的效率。
布隆過濾器有一定的判錯率。但是,我們可以規避它的短處,發揮它的長處。儘管對於判定存在的數據,有可能並不存在,但是對於判定不存在的數據,那肯定就不存在。而且,布隆過濾器還有一個更大的特點,那就是內存佔用非常少。我們可以針對數據,構建一個布隆過濾器,並且存儲在內存中。當要查詢數據的時候,我們可以先通過布隆過濾器,判定是否存在。如果數據不存在,那我們就沒必要讀取磁盤中的索引了。對於數據不存在的情況,數據查詢就更加快速了。
⑥ 有序數組也可以被作爲索引。如果數據是靜態的,也就是不會插入、刪除、更新操作,那我們可以把數據的關鍵詞(查詢用的)抽取出來,組織成有序數組,然後利用二分查找算法來快速查找數據。