




1. B+树
为了加速数据库中数据的查找速度,常用的处理思路是,对表中数据创建索引。数据库索引是如何实现的呢?底层使用的是什么数据结构和算法呢?
数据库查询需求:
- 根据某个值查找数据,比如 select * from user where id=1234;
- 根据区间值来查找某些数据,比如 select * from user where id > 1234 and id < 2345。
即单值查找和区间查找。
除了这些功能性需求之外,这种问题往往还会涉及一些非功能性需求,比如安全、性能、用户体验等。对于非功能性需求,我们着重考虑性能方面的需求。性能方面的需求,我们主要考察时间和空间两方面,也就是执行效率和存储空间。
在执行效率方面,我们希望通过索引,查询数据的效率尽可能的高;在存储空间方面,我们希望索引不要消耗太多的内存空间。
支持快速查询、插入等操作的动态数据结构
有散列表、平衡二叉查找树、跳表。
散列表。散列表的查询性能很好,时间复杂度是 O(1)。但是,散列表不能支持按照区间快速查找数据。所以,散列表不能满足我们的需求。
平衡二叉查找树。尽管平衡二叉查找树查询的性能也很高,时间复杂度是 O(logn)。而且,对树进行中序遍历,我们还可以得到一个从小到大有序的数据序列,但这仍然不足以支持按照区间快速查找数据。
跳表。跳表是在链表之上加上多层索引构成的。它支持快速地插入、查找、删除数据,对应的时间复杂度是 O(logn)。并且,跳表也支持按照区间快速地查找数据。我们只需要定位到区间起点值对应在链表中的
结点,然后从这个结点开始,顺序遍历链表,直到区间终点对应的结点为止,这期间遍历得到的数据就是满足区间值的数据。

这样看来,跳表是可以解决这个问题。实际上,数据库索引所用到的数据结构跟跳表非常相似,叫作 B+ 树。不过,它是通过二叉查找树演化过来的,而非跳表。
二叉查找树改造成 B+ 树
改造二叉查找树为B+树
为了让二叉查找树支持按照区间来查找数据,我们可以对它进行这样的改造:
树中的节点并不存储数据本身,而只是作为索引。除此之外,我们把每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。经过改造之后的二叉树,就像图中这样,看起来是不是很像跳表呢?

B+ 树中,将叶子节点串起来的链表,是单链表还是双向链表?为什么?
对于B+tree叶子节点,是用双向链表还是用单链表,得从具体的场景思考。
数据库查询,都遇到过升序或降序问题,即类似这样的sql: select name,age, ... from user where uid > 10 and uid < 100 order by uid asc(或者desc),此时,数据底层实现有两种做法:
- 1)保证查出来的数据就是用户想要的顺序
- 2)不保证查出来的数据的有序性,查出来之后再排序
以上两种肯定选第一种,因为第二种做法浪费了时间(如果选用内存排序,还是考虑数据的量级)。那如何能保证查询出来的数据就是有序的呢?单链表肯定做不到,只能从头往后遍历,只能选择双向链表了。
双向链表,多出来了一倍的指针,会多占用空间。可是,数据库索引本身都已经在磁盘中了,对于磁盘来说,这点空间已经微不足道了,用空间换来时间。
在实际工程应用中,双向链表应用的场景非常广泛,毕竟能大量减少链表的遍历时间。
改造之后,如果我们要求某个区间的数据。只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的
数据,就是符合区间值的所有数据。

索引的存储问题
但是,要为几千万、上亿的数据构建索引,如果将索引存储在内存中,尽管内存访问的速度非常快,查询的效率非常高,但是,占用的内存会非常多。
比如,给一亿个数据构建二叉查找树索引,那索引中会包含大约 1 亿个节点,每个节点假设占用 16 个字节,那就需要大约 1GB 的内存空间。给一张表建立索引,我们需要 1GB 的内存空间。如果我们要给 10
张表建立索引,那对内存的需求是无法满足的。如何解决这个索引占用太多内存的问题?
借助时间换空间的思路,把索引存储在硬盘中,而非内存中。硬盘是一个非常慢速的存储设备。通常内存的访问速度是纳秒级别的,而磁盘访问的速度是毫秒级别的。读取同样大小的数据,从磁盘中读
取花费的时间,是从内存中读取所花费时间的上万倍,甚至几十万倍。这种将索引存储在硬盘中的方案,减少了内存消耗,但在数据查找过程中,需要读取磁盘中的索引,因此数据查询效率就相应降低很多。
二叉查找树,改造后,支持区间查找的功能就实现了。为节省内存,如果把树存储在硬盘中,那么每个节点的读取(或者访问),都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。
磁盘IO的优化
比起内存读写操作,磁盘 IO 操作非常耗时,所以我们优化的重点就是尽量减少磁盘 IO 操作,也就是,尽量降低树的高度。那如何降低树的高度呢?
如果我们把索引构建成 m 叉树,高度是不是比二叉树要小呢?如图所示,给 16 个数据构建二叉树索引,树的高度是 4,查找一个数据,就需要 4 个磁盘 IO 操作(如果根节点存储在内存中,其他结点存储在磁
盘中),如果对 16 个数据构建五叉树索引,那高度只有 2,查找一个数据,对应只需要 2 次磁盘操作。如果 m 叉树中的 m 是 100,那对一亿个数据构建索引,树的高度也只是 3,最多只要 3 次磁盘 IO 就能获
取到数据(100的4次方是1亿,第一层的索引节点可以放到内存中,就是3次IO操作 )。磁盘 IO 变少了,查找数据的效率也就提高了。


将 m 叉树实现 B+ 树索引,用代码实现出来,(假设我们给 int 类型的数据库字段添加索引,所以代码中的 keywords 是 int 类型的):
/**
* 这是 B+ 树非叶子节点的定义。
*
* 假设 keywords=[3, 5, 8, 10] keywords字段为int类型,给它添加索引;
* 4 个键值将数据分为 5 个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5 个区间分别对应:children[0]...children[4]
*
* m 值(m叉树)是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = ( m - 1 ) * 4 [keywordss 大小] + m * 8 [children 大小]
*/
public class BPlusTreeNode {
public static int m = 5; // 5 叉树
public int[] keywords = new int[m-1]; // 键值,用来划分数据区间
public BPlusTreeNode[] children = new BPlusTreeNode[m];// 保存子节点指针
}
/**
* 这是 B+ 树中叶子节点的定义。
*
* B+ 树中的叶子节点跟内部结点是不一样的,
* 叶子节点存储的是值,而非区间。
* 这个定义里,每个叶子节点存储 3 个数据行的键值及地址信息。
*
* k 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = k * 4 [keyw.. 大小] + k*8 [dataAd.. 大小] + 8[prev 大小] + 8[next 大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 数据的键值
public long[] dataAddress = new long[k]; // 数据地址
public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点
public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}
对于相同个数的数据构建 m 叉树索引,m 叉树中的 m 越大,那树的高度就越小,那 m 叉树中的 m 是不是越大越好呢?到底多大才最合适呢 ?
不管是内存中的数据,还是磁盘中的数据,操作系统都是按页(一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看)来读取的,一次会读一页的数据。如果要读取的数据量超过一页的大
小,就会触发多次 IO 操作。所以,我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作。
叶子节点存对象,对象包含key和data。 数据是存储在叶子节点指向的磁盘地址

插入操作
尽管索引可以提高数据库的查询效率,索引有利也有弊,它也会让写入数据的效率下降。
数据的写入过程,会涉及索引的更新,这是索引导致写入变慢的主要原因。
对于一个 B+ 树来说,m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大
小超过了一个页的大小,读取这样一个节点,就会导致多次磁盘 IO 操作。如何解决这个问题呢?
实际上,处理思路并不复杂。只需要将这个节点分裂成两个节点。但是,节点分裂之后,其上层父节点的子节点个数就有可能超过 m 个。不过这也没关系,可以用同样的方法,将父节点也分裂成两个节点。这
种级联反应会从下往上,一直影响到根节点。
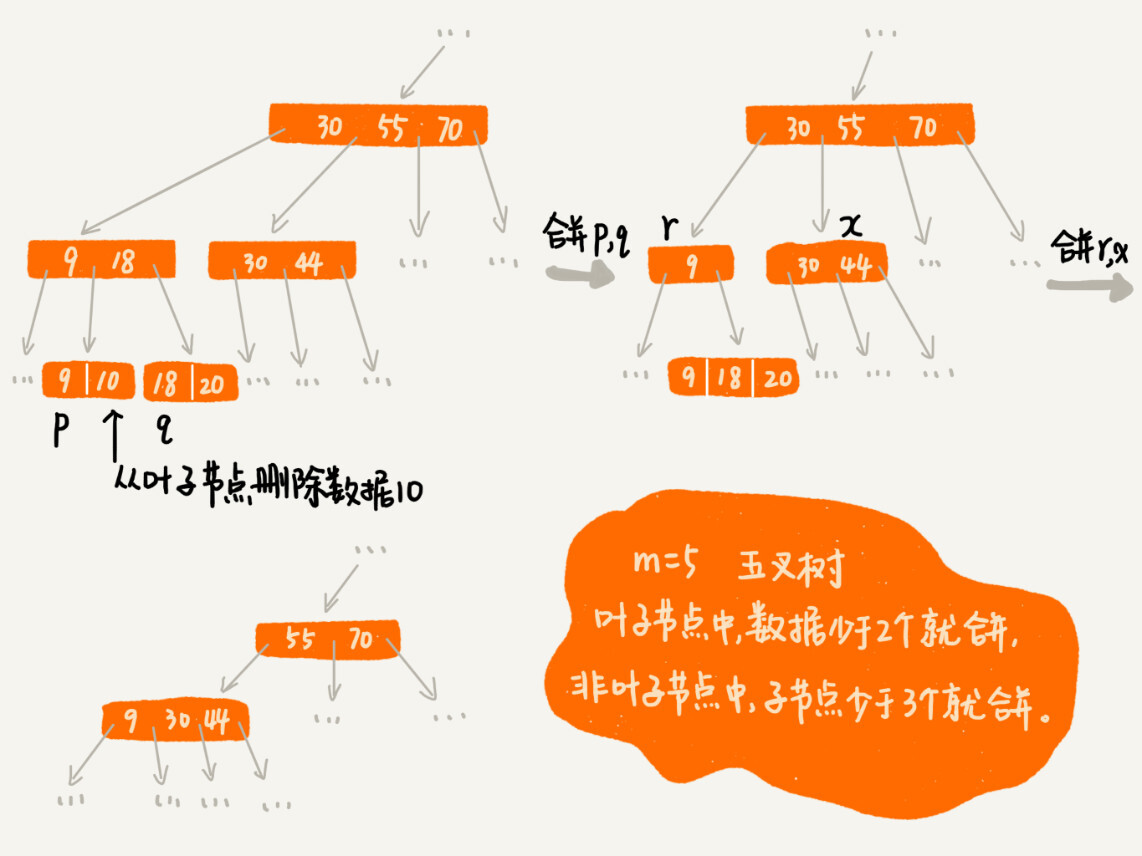
分裂过程如下,(图中的 B+ 树是一个三叉树。限定叶子节点中,数据的个数超过 2 个就分裂节点;非叶子节点中,子节点的个数超过 3 个就分裂节点)。

删除操作
正是因为要时刻保证 B+ 树索引是一个 m 叉树,所以,索引的存在会导致数据库写入的速度降低。实际上,不光写入数据会变慢,删除数据也会变慢。
我们在删除某个数据的时候,也要对应的更新索引节点。这个处理思路有点类似跳表中删除数据的处理思路。频繁的数据删除,就会导致某些结点中,子节点的个数变得非常少,长此以往,如果每个节点的子节
点都比较少,势必会影响索引的效率。
我们可以设置一个阈值。在 B+ 树中,这个阈值等于 m/2。如果某个节点的子节点个数小于 m/2,我们就将它跟相邻的兄弟节点合并。不过,合并之后结点的子节点个数有可能会超过 m。针对这种情况,借助插入数据时候的处理方法,再分裂节点。
删除操作如下:(图中的 B+ 树是一个五叉树。我们限定叶子节点中,数据的个数少于 2 个就合并节点;非叶子节点中,子节点的个数少于 3 个就合并节点。)
 img
img
B+ 树的结构和操作,跟跳表非常类似。理论上讲,对跳表稍加改造,也可以替代 B+ 树,作为数据库的索引实现的。
B+ 树发明于 1972 年,跳表发明于 1989 年,跳表的作者有可能就是受了 B+ 树的启发,才发明出跳表来的。
B+树总结
数据库索引实现,依赖的底层数据结构,B+ 树。通过存储在磁盘的多叉树结构,做到了时间、空间的平衡,既保证了执行效率,又节省了内存。
B+ 树的特点:
- 每个节点中子节点的个数不能超过 m,也不能小于 m/2;
- 根节点的子节点个数可以不超过 m/2,这是一个例外;
- m 叉树只存储索引,并不真正存储数据,这个有点儿类似跳表;
- 通过链表将叶子节点串联在一起,这样可以方便按区间查找;
- 一般情况,根节点会被存储在内存中,其他节点存储在磁盘中。
除了 B+ 树,还有 B 树、B- 树。实际上,B- 树就是 B 树,英文翻译都是 B-Tree,这里的“-”并不是相对 B+ 树中的“+”,而只是一个连接符。这个很容易误解。
而 B 树实际上是低级版的 B+ 树,或者说 B+ 树是 B 树的改进版。B 树跟 B+ 树的不同点主要集中在这几个地方:
- B+ 树中的节点不存储数据,只是索引,而 B 树中的节点存储数据;
- B 树中的叶子节点并不需要链表来串联。
也就是说,B 树只是一个每个节点的子节点个数不能小于 m/2 的 m 叉树。
B+tree的理解抓住几个要点:
- 1. 理解二叉查找树
- 2. 理解二叉查找树会出现不平衡的问题(红黑树理解了,对于平衡性这个关键点就理解了)
- 3. 磁盘IO访问太耗时
- 4. 当然,链表知识跑不了 —— 别小瞧这个简单的数据结构,它是链式结构之母
- 5. 最后,要知道典型的应用场景:数据库的索引结构的设计
对平衡二叉查找树进行改造,将叶子节点串在链表中,就支持了按照区间来查找数据。散列表也经常跟链表一块使用,如果把散列表中的结点,也用链表串起来,能否支持按照区间查找数据呢?
可以支持区间查询。java中linkedHashMap就是链表+HashMap的组合,用于实现缓存的lru算法比较方便,不过要支持区间查询需要在插入时维持链表的有序性,复杂度O(n).效率比跳表和b+tree差
JDK中的LinkedHashMap为了能做到保持节点的顺序(插入顺序或者访问顺序),就是用双向链表将节点串起来的。
什么数据结构可以做到O(logn)的范围查询?
跳表,B+树,数据库索引确实也是用的B+树。
那么问题来了,跳表和B+树在实现难度和性能上有什么区别,在数据量很大的情况下,表现性能如何,为什么redis选跳表?
B+树主要是用在外部存储上,为了减少磁盘IO次数。
跳表比较适合内存存储。
实际上,两者本质的设计思想是雷同的,性能差距还是要具体看应用场景,无法从时间复杂度这么宽泛的度量标准来度量了。
2. 索引
索引的需求定义
对于系统设计需求,一般可以从功能性需求和非功能性需求两方面来分析。
1. 功能性需求
对于功能性需求大致要考虑以下几点。
数据是格式化的还是非格式化数据?要构建索引的原始数据,类型很多。分为两类,一类是结构化数据,比如MySQL中的数据;另一类是非结构化数据,比如搜索引擎中的网页。对于非结构化数据,我们一般
需要做预处理,提取出查询关键词,对关键词构建索引。
数据是静态数据还是动态数据?如果原始是一组静态数据,也就是说,不会有数据的增加、删除、更新操作,所以,我们在构建索引的时候,只需要考虑查询效率就可以了。这样,索引的构建就相对简单些。不过,大部分情况下,都是对动态数据构建索引,也就是说,我们不仅要考虑到索引的查询效率,在原始数据更新时,我们还需要动态的更新索引。支持动态数据集合的索引,设计越来相对更复杂些。
索引是存储在内存还是硬盘?如果索引存储在内存中,那技术要求的速度肯定要比存储的磁盘中的高。但是,如果原始数据量很大的情况下,对应的索引可能也会很大。这个时候,因为内存有限,我们可能就不得不将索引存储在硬盘中了。实际上,还有第三种情况,那就是一部分存储在内存,一部分存储在磁盘,这样就可以兼顾内存消耗和查询效率。
单值查找还是区间查找?所谓单值查找,也就是根据查询关键词等于某个值的数据。这种查询需求最常见。所谓区间查找,就是查找关键词处于某个区间值的所有数据。实际上,不同的应用场景,查询的需求会多种多样。
单关键词查找还是多关键词组合查找?比如,搜索引擎中构建的索引,既要支持一个关键词的查找,比如“数据结构”,也要支持组合关键词查找,比如“数据结构 AND算法”。对於单关键词查找,索引构建起来相
对简单些。对于多关键词查找来说,要分多种情况。像MySQL这种结构化数据的查询需求,我们可以实现针对多个关键词组合,建立索引;对于像搜索引擎这样的非结构数据的查询需求,我们可以针对间个关
键词构建索引,然后通过集合操作,比如求并集、求交集等,计算出多个关键词组合的查询结果。
实际上,不同的场景,不同的原始数据,对于索引的需求也会千差万别。
2.非功能性需求
不管是存储在内存中还是磁盘中,索引对存储空间的消耗不能过大。如果存储在内存中,索引对占用存储空间的限制就会非常苛刻。毕竟内存空间非常有限,一个中间件启动后就占用几个GB的内存,开发者显
然是无法接受的。如果存储在硬盘中,那索引对占用存储空间的限制,稍微会放宽一些。但是,我们也不能掉以轻心。因为,有时候,索引对存储空间消耗会超过数据。
在考虑索引查询效率的同时,我们还是考虑索引的维护成本。索引的目的是提高查询效率,但是,基于动态数据集合构建的索引,我们还要考虑到索引的维护成本。因为在原始数据动态增删改的同时,我们也需
要动态的更新索引。而索引的更新势必会影响到增删改的操作性能。
构建索引常用的数据结构
实际上,常用来构建索引的数据结构,即支持动态数据集合的数据结构。比如,散列表、红黑树、跳表、B+树。除此之外,位图、布隆过滤器可以作为辅助索引,有序数组可以用来对静态数据构建索引。
① 散列表增删改查操作的性能非常好,时间复杂度是O(1)。一些键值数据库,比如Redis、Memcache,就是使用散列表来构建索引的。这类索引,一般都构建在内存中。
② 红黑树作为一种常用的平衡二叉查找树,数据插入、删除、查找的时间复杂度是O(logn),也非常适合用来构建内存索引。Ext文件系统中,对磁盘块的索引,用的就是红黑树。
③ B+ 树比起红黑树来说,更加适合构建存储在磁盘的索引。B+树是一个多叉树,所以,以相同个数的数据构建索引,B+树的高度要低于红黑树。当借助索引查询数据的时候,读取B+树索引,需要的磁盘IO次
数更少。所以,大部分关系型数据库的索引,比如MySQL、Oracle,都是用B+树来实现的。
④ 跳表也支持快速添加、删除、查找数据。而且,我们通过灵活调整索引结点个数和数据个数之间的比例,可以很好的平衡对内存的消耗及其查询效率。Redis中的有序集合,就是用跳表来构建的。
⑤ 位图和布隆过滤器这两个数据结构,也可以用于索引中,辅助存储在磁盘中的索引,加速数据查询的效率。
布隆过滤器有一定的判错率。但是,我们可以规避它的短处,发挥它的长处。尽管对于判定存在的数据,有可能并不存在,但是对于判定不存在的数据,那肯定就不存在。而且,布隆过滤器还有一个更大的特点,那就是内存占用非常少。我们可以针对数据,构建一个布隆过滤器,并且存储在内存中。当要查询数据的时候,我们可以先通过布隆过滤器,判定是否存在。如果数据不存在,那我们就没必要读取磁盘中的索引了。对于数据不存在的情况,数据查询就更加快速了。
⑥ 有序数组也可以被作为索引。如果数据是静态的,也就是不会插入、删除、更新操作,那我们可以把数据的关键词(查询用的)抽取出来,组织成有序数组,然后利用二分查找算法来快速查找数据。