




1. Kafka的事務和 Exactly Once
Kafka 中的事務,它解決的問題是,確保在一個事務中發送的多條消息,要麼都成功,要麼都失敗。注意,這裏面的多條消息不一定要在同一個主題和分區中,可以是發往多個主題和
分區的消息。Kafka 的這種事務機制,單獨來使用的場景不多。更多的情況下被用來配合 Kafka 的冪等機制來實現 Kafka 的 Exactly Once 語義。這裏面的 Exactly Once,和我們通
常理解的消息隊列的服務水平中的 Exactly Once 是不一樣的。
通常理解消息隊列的服務水平中的 Exactly Once,它指的是,消息從生產者發送到 Broker,然後消費者再從 Broker 拉取消息,然後進行消費。這個過程中,確保每一條消息恰好傳輸一次,不重不丟。包括 Kafka 在內的幾個常見的開源消息隊列,都只能做到 At Least Once,也就是至少一次,保證消息不丟,但有可能會重複。做不到 Exactly Once。

那 Kafka 中的 Exactly Once 又是解決的什麼問題呢?它解決的是,在流計算中,用 Kafka 作爲數據源,並且將計算結果保存到 Kafka 這種場景下,數據從 Kafka 的某個主題中消費,在計算集羣中計算,再把計算結果保存在 Kafka 的其他主題中。這樣的過程中,保證每條消息都被恰好計算一次,確保計算結果正確。

比如,我們把所有訂單消息保存在一個 Kafka 的主題 Order 中,在 Flink 集羣中運行一個計算任務,統計每分鐘的訂單收入,然後把結果保存在另一個 Kafka 的主題 Income 裏面。要保證計算結果準確,就要確保,無論是 Kafka 集羣還是 Flink 集羣中任何節點發生故障,每條消息都只能被計算一次,不能重複計算,否則計算結果就錯了。這裏面有一個很重要的限制條件,就是數據必須來自 Kafka 並且計算結果都必須保存到 Kafka 中,纔可以享受到 Kafka 的 Excactly Once 機制。
可以看到,Kafka 的 Exactly Once 機制,是爲了解決在“讀數據 - 計算 - 保存結果”這樣的計算過程中數據不重不丟,而不是我們通常理解的使用消息隊列進行消息生產消費過程中的 Exactly Once。
Kafka 的事務是如何實現的
基於兩階段提交來實現的,但是實現的過程更加複雜。
首先說一下,參與 Kafka 事務的幾個角色,或者說是模塊。爲了解決分佈式事務問題,Kafka 引入了事務協調者這個角色,負責在服務端協調整個事務。這個協調者並不是一個獨立的
進程,而是 Broker 進程的一部分,協調者和分區一樣通過選舉來保證自身的可用性。
和 RocketMQ 類似,Kafka 集羣中也有一個特殊的用於記錄事務日誌的主題,這個事務日誌主題的實現和普通的主題是一樣的,裏面記錄的數據就是類似於“開啓事務”“提交事務”這樣
的事務日誌。日誌主題同樣也包含了很多的分區。在 Kafka 集羣中,可以存在多個協調者,每個協調者負責管理和使用事務日誌中的幾個分區。這樣設計,其實就是爲了能並行執行
多個事務,提升性能。

Kafka 事務的實現流程
首先,當我們開啓事務的時候,生產者會給協調者發一個請求來開啓事務,協調者在事務日誌中記錄下事務 ID。
然後,生產者在發送消息之前,還要給協調者發送請求,告知發送的消息屬於哪個主題和分區,這個信息也會被協調者記錄在事務日誌中。
接下來,生產者就可以像發送普通消息一樣來發送事務消息,這裏和 RocketMQ 不同的是,RocketMQ 選擇把未提交的事務消息保存在特殊的隊列中,而 Kafka 在處理未提交的事務
消息時,和普通消息是一樣的,直接發給Broker,保存在這些消息對應的分區中,Kafka 會在客戶端的消費者中,暫時過濾未提交的事務消息。
消息發送完成後,生產者給協調者發送提交或回滾事務的請求,由協調者來開始兩階段提交,完成事務。第一階段,協調者把事務的狀態設置爲“預提交”,並寫入事務日誌。到這裏,
實際上事務已經成功了,無論接下來發生什麼情況,事務最終都會被提交。
之後便開始第二階段,協調者在事務相關的所有分區中,都會寫一條“事務結束”的特殊消息,當 Kafka 的消費者,也就是客戶端,讀到這個事務結束的特殊消息之後,它就可以把之
前暫時過濾的那些未提交的事務消息,放行給業務代碼進行消費了。最後,協調者記錄最後一條事務日誌,標識這個事務已經結束了。

總結一下 Kafka 這個兩階段的流程,準備階段,生產者發消息給協調者開啓事務,然後消息發送到每個分區上。提交階段,生產者發消息給協調者提交事務,協調者給每個分區發一
條“事務結束”的消息,完成分佈式事務提交。
基於兩階段提交來實現的事務,都利用了特殊的主題中的隊列和分區來記錄事務日誌。
對處於事務中的消息的處理方式, Kafka 直接把消息放到對應的業務分區中,配合客戶端過濾來暫時屏蔽進行中的事務消息。
Kafka 的事務則是用於實現它的 Exactly Once 機制,應用於實時計算的場景中。
其實kafka的Exactly Once模式,是kafka的consumer通過PID去實現了一個冪等操作,原理上來說是和at last once我們業務自己通過其他唯一ID實現冪等是一樣的效果,並不是正真的
只傳輸到客戶端一次,而是重複傳輸實現了冪等。
事務結束消息就是一條特殊的消息,和普通消息一樣保存在分區中。同普通消息一樣,事務結束消息只要不被刪除,就會一直存在。
大量未提交消息對客戶端內存影響不大,因爲Kafka客戶端有一個固定大小的buffer用來保存拉取的消息。
只要你遵循:先執行消費業務邏輯,再提交,這樣的原則。即使客戶端重啓或者Rebalance,也不會丟消息。
“消息發送完成後,生產者給協調者發送提交或回滾事務的請求,由協調者來開始兩階段提交,完成事務。第一階段,協調者把事務的狀態設置爲“預提交”,並寫入事務日誌。到這裏,實際上事務已經成功了,無論接下來發生什麼情況,事務最終都會被提交。”假如協調者執行完第一階段之後還沒有執行第二階段,這時候機器宕機或者進程被KILL掉了,重啓之後還是會繼續執行第二階段。
2. 在流計算中使用Kafka鏈接計算任務
大部分流計算平臺都會採用存儲計算分離的設計,將計算任務的狀態保存在 HDFS 等分佈式存儲系統中。每個子任務將狀態分離出去之後,就變成了無狀態的節點,如果某一個計算
節點發生宕機,使用集羣中任意一個節點都可以替代故障節點。
但是,對流計算來說,這裏面還有一個問題沒解決,就是在集羣中流動的數據並沒有被持久化,所以它們就有可能由於節點故障而丟失,怎麼解決這個問題呢?辦法也比較簡單粗暴,
就是直接重啓整個計算任務,並且從數據源頭向前回溯一些數據。計算任務重啓之後,會重新分配計算節點,順便就完成了故障遷移。
回溯數據源,可以保證數據不丟失,這和消息隊列中,通過重發未成功的消息來保證數據不丟的方法是類似的。所以,它們面臨同樣的問題:可能會出現重複的消息。消息隊列可以通
過在消費端做冪等來克服這個問題,但是對於流計算任務來說,這個問題就很棘手了。
對於接收計算結果的下游系統,它可能會收到重複的計算結果,這還不是最糟糕的。像一些統計類的計算任務,就會有比較大的影響,比如計算IP 地址在統計週期內被訪問了 5 次,產生了 5 條訪問日誌,正確的結果應該是 5 次。如果日誌被重複統計,那結果就會多於 5 次,重複的數據導致統計結果出現了錯誤。怎麼解決這個問題呢?
Kafka 支持 Exactly Once 語義,它的這個特性就是爲了解決這個問題而生的。如何使用 Kafka 配合 Flink,解決數據重複的問題,實現端到端的 Exactly Once 語義。
Flink 是如何保證 Exactly Once 語義的
我們所說的端到端 Exactly Once,這裏面的“端到端”指的是,數據從 Kafka 的 A 主題消費,發送給 Flink 的計算集羣進行計算,計算結果再發給 Kafka 的 B 主題。在這整個過程
中,無論是 Kafka 集羣的節點還是 Flink 集羣的節點發生故障,都不會影響計算結果,每條消息只會被計算一次,不能多也不能少。
在理解端到端 Exactly Once 的實現原理之前,需要先了解一下,Flink 集羣本身是如何保證 Exactly Once 語義的。爲什麼 Flink 也需要保證 Exactly Once 呢?Flink 集羣本身也是一個
分佈式系統,它首先需要保證數據在 Flink 集羣內部只被計算一次,只有在這個基礎上,才談得到端到端的 Exactly Once。
Flink 通過 CheckPoint 機制來定期保存計算任務的快照,這個快照中主要包含兩個重要的數據:
- 整個計算任務的狀態。這個狀態主要是計算任務中,每個子任務在計算過程中需要保存的臨時狀態數據。
- 數據源的位置信息。這個信息記錄了在數據源的這個流中已經計算了哪些數據。如果數據源是 Kafka 的主題,這個位置信息就是 Kafka 主題中的消費位置。
有了 CheckPoint,當計算任務失敗重啓的時候,可以從最近的一個 CheckPoint 恢復計算任務。具體的做法是,每個子任務先從 CheckPoint 中讀取並恢復自己的狀態,然後整個計算任務從 CheckPoint 中記錄的數據源位置開始消費數據,只要這個恢復位置和 CheckPoint 中每個子任務的狀態是完全對應的,或者說,每個子任務的狀態恰好是:“剛剛處理完恢復位置之前的那條數據,還沒有開始處理恢復位置對應的這條數據”,這個時刻保存的狀態,就可以做到嚴絲合縫地恢復計算任務,每一條數據既不會丟失也不會重複。
因爲每個子任務分佈在不同的節點上,並且數據是一直在子任務中流動的,所以確保 CheckPoint 中記錄的恢復位置和每個子任務的狀態完全對應並不是一件容易的事兒,Flink 是怎
麼實現的呢? Flink 通過在數據流中插入一個 Barrier(屏障)來確保 CheckPoint 中的位置和狀態完全對應。下面這張圖來自Flink 官網的說明文檔。
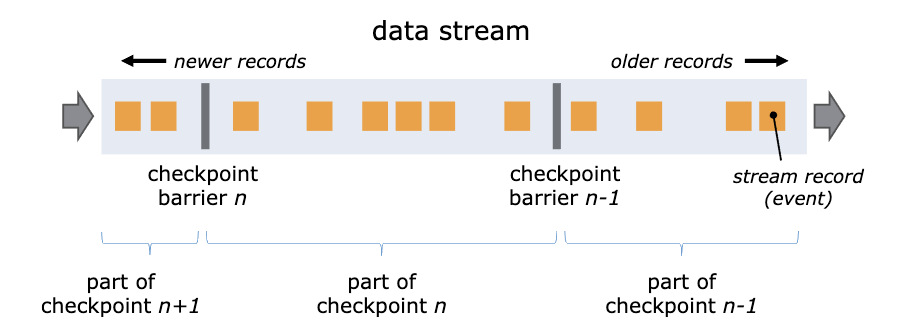
你可以把 Barrier 理解爲一條特殊的數據。Barrier 由 Flink 生成,並在數據進入計算集羣時被插入到數據流中。這樣,無限的數據流就被很多的 Barrier 分隔成很多段。Barrier 在流經
每個計算節點的時候,就會觸發這個節點在 CheckPoint 中保存本節點的狀態,如果這個節點是數據源節點,還會保存數據源的位置。
當一個 Barrier 流過所有計算節點,流出計算集羣后,一個 CheckPoint 也就保存完成了。由於每個節點都是在 Barrier 流過的時候保存的狀態,這時的狀態恰好就是 Barrier 所在位置
(也就是 CheckPoint 數據源位置)對應的狀態,這樣就完美解決了狀態與恢復位置對應的問題。
Flink 通過 CheckPoint 機制實現了集羣內計算任務的 Exactly Once 語義,但是仍然實現不了在輸入和輸出兩端數據不丟不重。比如,Flink 在把一條計算結果發給 Kafka 並收到來自
Kafka 的“發送成功”響應之後,纔會繼續處理下一條數據。如果這個時候重啓計算任務,Flink 集羣內的數據都可以完美地恢復到上一個 CheckPoint,但是已經發給 Kafka 的消息卻沒
辦法撤回,還是會出現數據重複的問題。所以,我們需要配合 Kafka 的 Exactly Once 機制,才能實現端到端的 Exactly Once。
Kafka 如何配合 Flink 實現端到端 Exactly Once?
Kafka 的 Exactly Once 語義是通過它的事務和生產冪等兩個特性來共同實現的。Kafka 事務的實現原理,它可以保證一個事務內的所有消息,要麼都成功投遞,要麼都不投遞。
生產冪等這個特性可以保證,在生產者給 Kafka Broker 發送消息這個過程中,消息不會重複發送。這個實現原理與“檢測消息丟失”的方法是類似的,都是通過連續遞增的序號進行檢
測。Kafka 的生產者給每個消息增加都附加一個連續遞增的序號,Broker 端會檢測這個序號的連續性,如果序號重複了,Broker 會拒絕這個重複消息。
Kafka 的這兩個機制,配合 Flink 就可以來實現端到端的 Exactly Once 了。
簡單地說就是,每個 Flink 的 CheckPoint 對應一個 Kafka 事務。Flink 在創建一個 CheckPoint 的時候,同時開啓一個 Kafka 的事務,完成 CheckPoint 同時提交 Kafka 的事務。當計
算任務重啓的時候,在 Flink 中計算任務會恢復到上一個 CheckPoint,這個 CheckPoint 正好對應 Kafka 上一個成功提交的事務。未完成的 CheckPoint 和未提交的事務中的消息都會
被丟棄,這樣就實現了端到端的 Exactly Once。但是,怎麼才能保證“完成 CheckPoint 同時提交 Kafka 的事務”呢?或者說,如何來保證“完成 CheckPoint”和“提交 Kafka 事務”這兩個
操作,要麼都成功,要麼都失敗呢?這不就是一個典型的分佈式事務問題嘛!
所以,Flink 基於兩階段提交這個常用的分佈式事務算法,實現了一分佈式事務的控制器來解決這個問題。如果你對具體的實現原理感興趣,可以看一下 Flink 官網文檔中的這篇文章。
Exactly Once 版本的 Web 請求的統計
“統計 Web 請求的次數”的 Flink Job 改造一下,讓這個 Job 具備 Exactly Once 特性。這個實時統計任務接收 NGINX 的 access.log,每 5 秒鐘按照 IP 地址統計 Web 請求的次數。假
設我們已經有一個實時發送 access.log 的日誌服務來發送日誌,日誌的內容只包含訪問時間和 IP 地址,這個日誌服務就是我們流計算任務的數據源。
改造之後,我們需要把數據的來源替換成 Kafka 的 ip_count_source 主題,計算結果也要保存到 Kafka 的主題 ip_count_sink 中。
整個系統的數據流向就變成下圖這樣:

日誌服務將日誌數據發送到 Kafka 的主題 ip_count_source,計算任務消費這個主題的數據作爲數據源,計算結果會被寫入到 Kafka 的主題 ip_count_sink 中。
Flink 提供了 Kafka Connector 模塊,可以作爲數據源從 Kafka 中消費數據,也可以作爲 Kafka 的 Producer,將計算結果發送給 Kafka,並且,這個 Kafka Connector 已經實現了
Exactly Once 語義,我們在使用的時候只要做適當的配置就可以了。
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.AbstractDeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.runtime.state.StateBackend;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011;
import org.apache.flink.streaming.connectors.kafka.internals.KeyedSerializationSchemaWrapper;
import java.io.File;
import java.nio.charset.StandardCharsets;
import java.text.ParseException;
import java.text.SimpleDateFormat
public class ExactlyOnceIpCount {
public static void main(String[] args) throws Exception {
// 設置輸入和輸出
FlinkKafkaConsumer011<IpAndCount> sourceConsumer = setupSource();
FlinkKafkaProducer011<String> sinkProducer = setupSink();
// 設置運行時環境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); // 按照EventTime來統計
env.enableCheckpointing(5000); // 每5秒保存一次CheckPoint
// 設置CheckPoint
CheckpointConfig config = env.getCheckpointConfig();
config.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); // 設置CheckPoint模式爲EXACTLY_ONCE
config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); // 取消任務時保留CheckPoint
config.setPreferCheckpointForRecovery(true); // 啓動時從CheckPoint恢復任務
// 設置CheckPoint的StateBackend,在這裏CheckPoint保存在本地臨時目錄中。
// 只適合單節點做實驗,在生產環境應該使用分佈式文件系統,例如HDFS。
File tmpDirFile = new File(System.getProperty("java.io.tmpdir"));
env.setStateBackend((StateBackend) new FsStateBackend(tmpDirFile.toURI().toURL().toString()));
// 設置故障恢復策略:任務失敗的時候自動每隔10秒重啓,一共嘗試重啓3次
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
10000 // delay
));
// 定義輸入:從Kafka中獲取數據
DataStream<IpAndCount> input = env.addSource(sourceConsumer);
// 計算:每5秒鐘按照ip對count求和
DataStream<IpAndCount> output = input
.keyBy(IpAndCount::getIp) // 按照ip地址統計
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // 每5秒鐘統計一次
.allowedLateness(Time.seconds(5))
.sum("count"); // 對count字段求和
// 輸出到kafka topic
output.map(IpAndCount::toString).addSink(sinkProducer);
// execute program
env.execute("Exactly-once IpCount");
}
private static FlinkKafkaProducer011<String> setupSink() {
// 設置Kafka Producer屬性
Properties producerProperties = new Properties();
producerProperties.put("bootstrap.servers", "localhost:9092");
// 事務超時時間設置爲1分鐘
producerProperties.put("transaction.timeout.ms", "60000");
// 創建 FlinkKafkaProducer,指定語義爲EXACTLY_ONCE
return new FlinkKafkaProducer011<>(
"ip_count_sink",
new KeyedSerializationSchemaWrapper<>(new SimpleStringSchema()),
producerProperties,
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
}
private static FlinkKafkaConsumer011<IpAndCount> setupSource() {
// 設置Kafka Consumer屬性
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "IpCount");
// 創建 FlinkKafkaConsumer
FlinkKafkaConsumer011<IpAndCount> sourceConsumer =
new FlinkKafkaConsumer011<>("ip_count_source",
new AbstractDeserializationSchema<IpAndCount>() {
// 自定義反序列化消息的方法:將非結構化的以空格分隔的文本直接轉成結構化數據IpAndCount
@Override
public IpAndCount deserialize(byte[] bytes) {
String str = new String(bytes, StandardCharsets.UTF_8);
String [] splt = str.split("\\s");
try {
return new IpAndCount(new SimpleDateFormat("yyyy-MM-dd_HH:mm:ss").parse(splt[0]),splt[1], 1L);
} catch (ParseException e) {
throw new RuntimeException(e);
}
}
}, properties);
// 告訴Flink時間從哪個字段中獲取
sourceConsumer.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<IpAndCount>() {
@Override
public long extractAscendingTimestamp(IpAndCount ipAndCount) {
return ipAndCount.getDate().getTime();
}
});
return sourceConsumer;
}
}
定義數據源、定義計算邏輯和定義輸入這三大步驟。下面主要來說不同之處,這些不同的地方也就是如何配置 Exactly Once 特性的關鍵點。
首先,我們需要開啓並配置好 CheckPoint。在這段代碼中,我們開啓了 CheckPoint,設置每 5 秒鐘創建一個 CheckPoint。然後,還需要定義保存 CheckPoint 的 StateBackend,也
就是告訴 Flink 把 CheckPoint 保存在哪兒。在生產環境中,CheckPoint 應該保存到 HDFS 這樣的分佈式文件系統中。這個例子中,爲了方便運行調試,直接把 CheckPoint 保存到
本地的臨時目錄中。之後,我們還需要將 Job 配置成自動重啓,這樣當節點發生故障時,Flink 會自動重啓 Job 並從最近一次 CheckPoint 開始恢復。
我們在定義輸出創建 FlinkKafkaProducer 的時候,需要指定 Exactly Once 語義,這樣 Flink 纔會開啓 Kafka 的事務,代碼如下:
private static FlinkKafkaProducer011<String> setupSink() {
// 設置Kafka Producer屬性
Properties producerProperties = new Properties();
producerProperties.put("bootstrap.servers", "localhost:9092");
// 事務超時時間設置爲1分鐘
producerProperties.put("transaction.timeout.ms", "60000");
// 創建 FlinkKafkaProducer,指定語義爲EXACTLY_ONCE
return new FlinkKafkaProducer011<>(
"ip_count_sink",
new KeyedSerializationSchemaWrapper<>(new SimpleStringSchema()),
producerProperties,
FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
}
在從 Kafka 主題 ip_count_sink 中消費計算結果的時候,需要配置 Consumer 屬性:isolation.level=read_committed,也就是隻消費已提交事務的消息。因爲默認情況下,Kafka 的
Consumer 是可以消費到未提交事務的消息的。
小結
端到端 Exactly Once 語義,可以保證在分佈式系統中,每條數據不多不少只被處理一次。在流計算中,因爲數據重複會導致計算結果錯誤,所以 Exactly Once 在流計算場景中尤其重
要。Kafka 和 Flink 都提供了保證 Exactly Once 的特性,配合使用可以實現端到端的 Exactly Once 語義。
在 Flink 中,如果節點出現故障,可以自動重啓計算任務,重新分配計算節點來保證系統的可用性。配合 CheckPoint 機制,可以保證重啓後任務的狀態恢復到最後一次 CheckPoint,
然後從 CheckPoint 中記錄的恢復位置繼續讀取數據進行計算。Flink 通過一個巧妙的 Barrier 使 CheckPoint 中恢復位置和各節點狀態完全對應。
Kafka 的 Exactly Once 語義是通過它的事務和生產冪等兩個特性來共同實現的。在配合 Flink 的時候,每個 Flink 的 CheckPoint 對應一個 Kafka 事務,只要保證 CheckPoint 和 Kafka
事務同步提交就可以實現端到端的 Exactly Once,Flink 通過“二階段提交”這個分佈式事務的經典算法來保證 CheckPoint 和 Kafka 事務狀態的一致性。
可以看到,Flink 配合 Kafka 來實現端到端的 Exactly Once 語義,整個實現過程比較複雜,但是,這個複雜的大問題是由一個一個小問題組成的,每個小問題的原理都是很簡單的。比
如:Kafka 如何實現的生產冪等?Flink 如何通過存儲計算分離解決子任務狀態恢復的?
每一個小問題它面臨的場景是什麼樣的,以及如何解決問題的方法。而不要拘泥於,Kafka 或者 Flink 的某個參數怎麼配這些細節問題。這些問題可以等到你在生產中真正需要使用的
時候,再去讀文檔,“現學現賣”都來得及。
思考
在消息隊列的消費端,一定要“先執行消費業務邏輯,再確認消費”,這樣才能保證不丟數據。在 FlinkKafkaConsumer 在從數據源主題 ip_count_sink 消費數據之後,如何來確認消費的。如果消費位置管理不好,一樣會導致消息丟失或者重複,查閱資料看一下 FlinkKafkaConsumer 是如何來確認消費的。
https://www.infoq.cn/article/58bzvIbT2fqyW*cXzGlG
Kafka Stream目前來說,相關的生態還不夠成熟,可以瞭解一下,但不建議在生產系統中使用。
它和flink最大的區別是,它是一個庫,運行在你的應用程序進程內,而不是一個流計算框架。
1、spark官方文檔說,如果保存到checkpoint和把offset 提交到kafka,必須保證輸出是冪等的,光使用事務是不行的;
2、那麼如果無法保證輸出是冪等的,是否只能把offset 保存在第三方的數據庫(比如redis)中,但是這樣做是否是不可以設置checkpoints ?否則spark依然會從checkpoint中讀取,和從數據庫中讀取會造成衝突呢?
3、但不設置checkpoint,spark如何恢復現場呢?在提交命令時加入--supervise,好像yarn的模式不支持?即使使用supervise重啓,沒有checkpoint,也無法恢復現場吧?
A1:是這樣的,所以Kafka的Exactly Once特性中是有事務和生產冪等(相當於流計算輸出冪等)二個功能組成的。
A2:這個方法不太可行,因爲你很難做到完美的故障恢復。
A3:具體操作細節層面的問題,建議你以官方的文檔爲準。
理論上是可以的,但是實際上hdfs沒有原生事務支持,實現起來比較困難。