




1.1 馮諾伊曼體系簡介
現代計算機之父馮諾伊曼最先提出程序存儲的思想,併成功將其運用在計算機的設計之中,該思想約定了用二進制進行計算和存儲,還定義計算機基本結構爲 5 個部分,分別是中央處理器(CPU)、內存、輸入設備、輸出設備、總線。
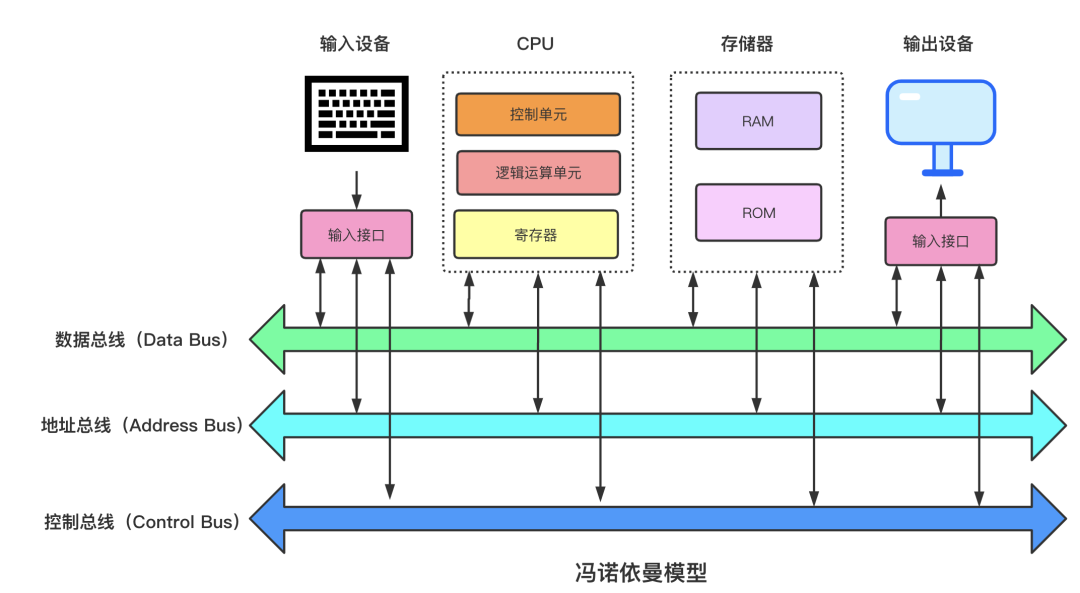
-
存儲器:代碼跟數據在RAM跟ROM中是線性存儲, 數據存儲的單位是一個二進制位。最小的存儲單位是字節。
-
總線:總線是用於 CPU 和內存以及其他設備之間的通信,總線主要有三種:
地址總線:用於指定 CPU 將要操作的內存地址。
數據總線:用於讀寫內存的數據。
控制總線:用於發送和接收信號,比如中斷、設備復位等信號,CPU 收到信號後響應,這時也需要控制總線。
-
輸入/輸出設備:輸入設備向計算機輸入數據,計算機經過計算後,把數據輸出給輸出設備。比如鍵盤按鍵時需要和 CPU 進行交互,這時就需要用到控制總線。
-
CPU:中央處理器,類比人腦,作爲計算機系統的運算和控制核心,是信息處理、程序運行的最終執行單元。CPU用寄存器存儲計算時所需數據,寄存器一般有三種:
通用寄存器:用來存放需要進行運算的數據,比如需進行加法運算的兩個數據。
程序計數器:用來存儲 CPU 要執行下一條指令所在的內存地址。
指令寄存器:用來存放程序計數器指向的指令本身。
在馮諾伊曼體系下電腦指令執行的過程:
-
CPU讀取程序計數器獲得指令內存地址,CPU控制單元操作地址總線從內存地址拿到數據,數據通過數據總線到達CPU被存入指令寄存器。
-
CPU分析指令寄存器中的指令,如果是計算類型的指令交給邏輯運算單元,如果是存儲類型的指令交給控制單元執行。
-
CPU 執行完指令後程序計數器的值通過自增指向下個指令,比如32位CPU會自增4。
-
自增後開始順序執行下一條指令,不斷循環執行直到程序結束。
CPU位寬:32位CPU一次可操作計算4個字節,64位CPU一次可操作計算8個字節,這個是硬件級別的。平常我們說的32位或64位操作系統指的是軟件級別的,指的是程序中指令多少位。
線路位寬:CPU操作指令數據通過高低電壓變化進行數據傳輸,傳輸時候可以串行傳輸,也可以並行傳輸,多少個並行等於多少個位寬。
1.2 CPU 簡介
Central Processing Unit 中央處理器,作爲計算機系統的運算和控制核心,是信息處理、程序運行的最終執行單元。
 CPU
CPU
-
CPU核心:一般一個CPU會有多個CPU核心,平常說的多核是指在一枚處理器中集成兩個或多個完整的計算引擎。核跟CPU的關係是:核屬於CPU的一部分。 -
寄存器:最靠近CPU對存儲單元,32位CPU寄存器可存儲4字節,64位寄存器可存儲8字節。寄存器訪問速度一般是半個CPU時鐘週期,屬於納秒級別, -
L1緩存:每個CPU核心都有,用來緩存數據跟指令,訪問空間大小一般在32~256KB,訪問速度一般是2~4個CPU時鐘週期。cat /sys/devices/system/cpu/cpu0/cache/index0/size # L1 數據緩存
cat /sys/devices/system/cpu/cpu0/cache/index1/size # L1 指令緩存 -
L2緩存:每個CPU核心都有,訪問空間大小在128KB~2MB,訪問速度一般是10~20個CPU時鐘週期。cat /sys/devices/system/cpu/cpu0/cache/index2/size # L2 緩存容量大小 -
L3緩存:多個CPU核心共用,訪問空間大小在2MB~64MB,訪問速度一般是20~60個CPU時鐘週期。cat /sys/devices/system/cpu/cpu0/cache/index3/size # L3 緩存容量大小 -
內存:多個CPU共用,現在一般是4G~512G,訪問速度一般是200~300個CPU時鐘週期。 -
固體硬盤SSD:現在臺式機主流都會配備,上述的寄存器、緩存、內存都是斷電數據立馬丟失的,而SSD裏不會丟失,大小一般是128G~1T,比內存慢10~1000倍。 -
機械盤HDD:很早以前流行的硬盤了,容量可在512G~8T不等,訪問速度比內存慢10W倍不等。 -
訪問數據順序:CPU在拿數據處理的時候幾乎也是按照上面說得流程來操縱的,只有上面一層找不到纔會找下一層。 -
Cache Line: CPU讀取數據時會按照 Cache Line 方式把數據加載到緩存中,每個Cacheline = 64KB,因爲L1、L2是每個核獨有到可能會觸發僞共享,就是 所以可能會將數據劃分到不同到CacheLine中來避免僞共享,比如在JDK8 新增加的 LongAdder 就涉及到此知識點。
僞共享:緩存系統中是以緩存行(cache line)爲單位存儲的,當多線程修改互相獨立的變量時,如果這些變量共享同一個緩存行,就會無意中影響彼此的性能,這就是僞共享。
-
JMM: 數據經過種種分層會導致訪問速度在不斷提升,同時也帶來了各種問題,多個CPU同時操作相同數據可能會造成各種BU個,需要加鎖,這裏在JUC併發已詳細探討過。
1.3 CPU 訪問方式
 CPU訪問方式
CPU訪問方式
內存數據映射到CPU Cache 時通過公式Block N % CacheLineMax決定內存Block數據放到那個CPU Cache Line 裏。CPU Cache 主要有4部分組成。
-
Cache Line Index :CPU緩存讀取數據時不是按照字節來讀取的,而是按照CacheLine方式存儲跟讀取數據的。
-
Valid Bit : 有效位標誌符,值爲0時表示無論 CPU Line 中是否有數據,CPU 都會直接訪問內存,重新加載數據。
-
Tag:組標記,用來標記內存中不同BLock映射到相同CacheLine,用Tag來區分不同的內存Block。
-
Data:真實到內存數據信息。
CPU真實訪問內存數據時只需要指定三個部分即可。
-
Cache Line Index :要訪問到Cache Line 位置。
-
Tag:表示用那個數據塊。
-
Offset:CPU從CPU Cache 讀取數據時不是直接讀取Cache Line整個數據塊,而是讀取CPU所需的數據片段,稱爲Word。如何找到Word就需要個偏移量Offset。
1.4 CPU 訪問速度
 訪問耗時對比
訪問耗時對比
如上圖所示,CPU訪問速度是逐步變慢,所以CPU訪問數據時需儘量在距離CPU近的高速緩存區訪問,根據摩爾定律CPU訪問速度每18個月就會翻倍,而內存的訪問每18個月也就增長10% 左右,導致的結果就是CPU跟內存訪問性能差距逐步變大,那如何儘可能提高CPU緩存命中率呢?
1. 數據緩存:遍歷數據時候按照內存佈局順序訪問,因爲CPU Cache是根據Cache Line批量操作數據的,所以你順序讀取數據會提速,道理跟磁盤順序寫一樣。
-
指令緩存:儘可能的提供有規律的條件分支語句,讓 CPU 的分支預測器發揮作用,進一步提高執行的效率,因爲CPU是自帶分支預測器,自動提前將可能需要的指令放到指令緩存區。 -
線程綁定到CPU:一個任務A在前一個時間片用CPU核心1 運行,後一個時間片用CPU核心2 運行,這樣緩存L1、L2就浪費了。因此操作系統提供了將進程或者線程綁定到某一顆 CPU 上運行的能力。如 Linux 上提供了 sched_setaffinity 方法實現這一功能,其他操作系統也有類似功能的 API 可用。當多線程同時執行密集計算,且 CPU 緩存命中率很高時,如果將每個線程分別綁定在不同的 CPU 核心上,性能便會獲得非常可觀的提升。
1.5 操作系統
2、內存管理

你的電腦是32位操作系統,那可支持的最大內存就是4G,你有沒有好奇爲什麼可以同時運行2個以上的2G內存的程序。應用程序不是直接使用的物理地址,操作系統爲每個運行的進程分配了一套虛擬地址,每個進程都有自己的虛擬內存地址,進程是無法直接進行物理內存地址的訪問的。至於虛擬地址跟物理地址的映射,進程是感知不到的!操作系統自身會提供一套機制將不同進程的虛擬地址和不同內存的物理地址進行映射。
 虛擬內存
虛擬內存
2.1 MMU
Memory Management Unit 內存管理單元是一種負責處理CPU內存訪問請求的計算機硬件。它的功能包括虛擬地址到物理地址的轉換、內存保護、中央處理器高速緩存的控制。現代 CPU 基本上都選擇了使用 MMU。
當進程持有虛擬內存地址的時候,CPU執行該進程時會操作虛擬內存,而MMU會自動的將虛擬內存的操作映射到物理內存上。
 MMU
MMU
這裏提一下,Java操作的時候你看到的地址是JVM地址,不是真正的物理地址。
2.2 內存管理方式
操作系統主要採用內存分段和內存分頁來管理虛擬地址與物理地址之間的關係,其中分段是很早前的方法了,現在大部分用的是分頁,不過分頁也不是完全的分頁,是在分段的基礎上再分頁。
2.2.1 內存分段
 JVM內存模型
JVM內存模型
我們以上圖的JVM內存模型舉例,程序員會認爲我們的代碼是由代碼段、數據段、棧段、堆段組成。不同的段是有不同的屬性的,用戶並不關心這些元素所在內存的位置,而分段就是支持這種用戶視圖的內存管理方案。邏輯地址空間是由一組段構成。每個段都有名稱和長度。地址指定了段名稱和段內偏移。因此用戶段編號和段偏移來指定不同屬性的地址。而虛擬內存地址跟物理內存地址中間是通過段表進行映射的,口說無憑,看圖吧。
 內存分段管理
內存分段管理
如上虛擬地址有 5 個段,各段按如圖所示來存儲。每個段都在段表中有一個條目,它包括段在物理內存內的開始的基地址和該段的界限長度。例如段 2 爲 400 字節長,開始於位置 4300。因此對段 2 字節 53 的引用映射成位置 4300 + 53 = 4353。對段 3 字節 852 的引用映射成位置 3200 + 852 = 4052。
分段映射很簡單,但是會導致內存碎片跟內存交互效率低。這裏先普及下在內存管理中主要有內部內存碎片跟外部內存碎片。
-
內部碎片:已經被分配出去的的內存空間不經常使用,並且分配出去的內存空間大於請求所需的內存空間。
-
外部碎片:指可用空間還沒有分配出去,但是可用空間由於大小太小而無法分配給申請空間的新進程的內存空間空閒塊。
以上圖爲例,現在系統空閒是1400 + 800 + 600 = 2800。那如果有個程序想要連續的使用2000,內存分段模式下提供不了啊!上述三個是外部內存碎片。當然可以使用系統的Swap空間,先把段0寫入到磁盤,然後再重新給段0分配空間。這樣可以實現最終可用,可是但凡涉及到磁盤讀寫就會導致內存交互效率低。
 swap空間利用
swap空間利用
2.2.2 內存分頁
內存分頁,整個虛擬內存和物理內存切成一段段固定尺寸的大小。每個固定大小的尺寸稱之爲頁Page,在 Linux 系統中Page = 4KB。然後虛擬內存跟物理內存之間通過頁表來實現映射。
採用內存分頁時內存的釋放跟使用都是以頁爲單位的,也就不會產生內存碎片了。當空間還不夠時根據操作系統調度算法,可能將最少用的內存頁面 swap-out換出到磁盤,用時候再swap-in換入,儘可能的減少磁盤刷寫量,提高內存交互效率。
分頁模式下虛擬地址主要有頁號跟頁內偏移量兩部分組成。通過頁號查詢頁表找到物理內存地址,然後再配合頁內偏移量就找到了真正的物理內存地址。
 分頁內存尋址
分頁內存尋址
32位操作系統環境下進程可操作的虛擬地址是4GB,假設一個虛擬頁大小爲4KB,那需要4GB/4KB = 2^20 個頁信息。一行頁表記錄爲4字節,2^20等價於4MB頁表存儲信息。這只是一個進程需要的,如果10個、100個、1000個呢?僅僅是頁表存儲都佔據超大內存了。
爲了解決這個問題就需要用到 多級頁表,核心思想就是局部性分配。在32位的操作系統中將將4G空間分爲 1024 行頁目錄項目(4KB),每個頁目錄項又對應1024行頁表項。如下圖所示:
 32位系統二級分頁
32位系統二級分頁
控制寄存器cr3中存放了頁目錄的物理地址,通過cr3寄存器可以找到頁目錄,而32位線性地址中的Directory部分決定頁目錄中的目錄項,而頁目錄項中存放了要找的頁表的物理基地址,再結合線性地址中的中間10位頁表項,就可以找到頁框的頁表項。線性地址中的Offset部分佔12位,因此頁框的物理地址 + 線性地址Offset部分 = 頁框中的任何一個字節。
分頁後一級頁就等價於4G虛擬地址空間,並且如果一級頁表中那些地址沒有就不需要再創建二級頁表了!核心思想就是按需創建,當系統給每個進程分配4G空間,進程不可能佔據全部內存的,如果一級目錄頁只有10%用到了,此時頁表空間 = 一級頁表4KB + 0.1 * 4MB 。這比單獨的每個進程佔據4M好用多了!
多層分頁的弊端就是訪問時間的增加。
-
使用頁表時讀取內存中一頁內容需要2次訪問內存,訪問頁表項 + 並讀取的一頁數據。
-
使用二級頁表的話需要三次訪問,訪問頁目錄項 + 訪問頁表項 + 訪問並讀取的一頁數據。訪存次數的增加也就意味着訪問數據所花費的總時間增加。
而對於64位系統,二級分頁就無法滿足了,Linux 從2.6.11開始採用四級分頁模型。
-
Page Global Directory 全局頁目錄項
-
Page Upper Directory 上層頁目錄項
-
Page Middle Directory 中間頁目錄項
-
Page Table Entry 頁表項
-
Offset 偏移量。
 64位尋址
64位尋址
2.2.2 TLB
Translation Lookaside Buffer 可翻譯爲地址轉換後援緩衝器,簡稱爲快表,屬於CPU內部的一個模塊,TLB是MMU的一部分,實質是cache,它所緩存的是最近使用的數據的頁表項(虛擬地址到物理地址的映射)。他的出現是爲了加快訪問數據(內存)的速度,減少重複的頁表查找。當然它不是必須要有的,但有它,速度就更快。
 CPU讀取數據流程圖
CPU讀取數據流程圖
當進程地址空間進行了上下文切換時,比如現在是進程1運行,TLB中放的是進程1的相關數據的地址,突然切換到進程2,TLB中原有的數據不是進程2相關的,此時TLB刷新數據有兩種辦法。
-
全部刷新:很簡單,但花銷大,很多不必刷新的數據也進行刷新,增加了無畏的花銷。
-
部分刷新:根據標誌位,刷新需要刷新的數據,保留不需要刷新的數據。
2.2.3 段頁式管理
內存分段跟內存分頁不是對立的,這倆可以組合起來在同一個系統中使用的,那麼組合起來後通常稱爲段頁式內存管理。段頁式內存管理實現的方式:
-
先對數據不同劃分出不同的段,也就是前面說的分段機制。
-
然後再把每一個段進行分頁操作,也就是前面說的分頁機制。
-
此時 地址結構 = 段號 + 段內頁號 + 頁內位移。
每一個進程有一張段表,每個段又建立一張頁表,段表中的地址是頁表的起始地址,而頁表中的地址則爲某頁的物理頁號。
 段頁式管理
段頁式管理
同時我們經常看到兩個專業詞邏輯地址跟線性地址。
-
邏輯地址:指的是沒被段式內存管理映射的地址。 -
線性地址:通過段式內存管理映射且頁式內存管理轉換前的地址,俗稱虛擬地址。
目前 Intel X86 CPU 採用的是內存分段 + 內存分頁的管理方式,其中分頁的意思是在由段式內存管理所映射而成的的地址上再加上一層地址映射。
 X86內存管理方式
X86內存管理方式
2.2.4 Linux 內存管理
先說結論:Linux系統基於X86 CPU 而做的操作系統,所以也是用的段頁式內存管理方式。
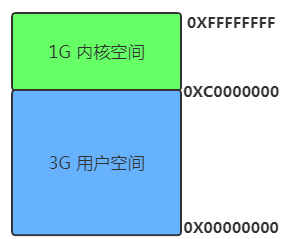
我們知道32位的操作系統可尋址範圍是4G,操作系統會將4G的可訪問內存空間分爲用戶空間跟內核空間。
-
內核空間:操作系統內核訪問的區域,獨立於普通的應用程序,是受保護的內存空間。內核態下CPU可執行任何指令,可自由訪問任何有效地址。 -
用戶空間:普通應用程序可訪問的內存區域。被執行代碼會受到CPU衆多限制,進程只能訪問映射其地址空間的頁表項中規定的在用戶態下可訪問頁面的虛擬地址。
那爲啥要搞倆空間呢?現在嵌入式環境跟以前的WIN98系統是沒有區分倆空間的,須知倆空間是CPU分的,而操作系統是在上面運行的,單一用戶、單一任務服務的操作系統,是沒有分所謂用戶態和內核態的必要。用戶態和內核態是因爲有多用戶,多任務的需求,然後在CPU硬件廠商配合之後,產生的一個操作系統解決多用戶多任務需求的方案。方案就是限制,通過硬件手段(也只能硬件手段才能做到),限制某些代碼,使其無法控制整個物理硬件,進而使各個不同用戶,不同任務的代碼,無權修改整個物理硬件,再進而保護操作系統的核心底層代碼和其他用戶的數據不被無意或者有意地破壞和盜取。

後來研究者根據CPU的運行級別,分成了Ring0~Ring3四個級別。Ring0是最高級別,Ring1次之,Rng2更次之,拿Linux+x86來說, 操作系統內核的代碼運行在最高運行級別Ring0上,可以使用特權指令,控制中斷、修改頁表、訪問設備等。 應用程序的代碼運行在最低運行級別上Ring3上,不能做受控操作,只能訪問用戶被分配的空間。如果要做訪問磁盤跟寫文件等操作,那就要通過執行系統調用函數,執行系統調用的時候,CPU的運行級別會發生從Ring3到Ring0的切換,並跳轉到系統調用對應的內核代碼位置執行,這樣內核就爲你完成了設備訪問,完成之後再從Ring0返回Ring3。這個過程也稱作用戶態和內核態的切換。
用戶態想要使用計算機設備或IO需通過系統調用完成sys call,系統調用就是讓內核來做這些操作。而系統調用是影響整個當前進程上下文的,CPU提供了個軟中斷來是實現保護線程,獲取系統調用號跟參數,交給內核對應系統調用函數執行。
3、進程管理
3.1 進程基礎知識
進程是程序的一次執行,是一個程序及其數據在機器上順序執行時所發生的活動,是具有獨立功能的程序在一個數據集合上的一次運行過程,是系統進行資源分配和調度的一個基本單位。進程的調度狀態如下:
 狀態變化圖
狀態變化圖
重點說下掛起跟阻塞:
-
阻塞一般是當系統執行IO操作時,此時進程進入阻塞狀態,等待某個事件的返回。
-
掛起是指進程沒有佔有物理內存,被寫到磁盤上了。這時進程狀態是掛起狀態。
阻塞掛起:進程被寫入硬盤並等待某個事件的出現。
就緒掛起:進程被寫入硬盤,進入內存可直接進入就緒狀態。
3.2 PCB
爲了描述跟控制進程的運行,系統爲每個進程定義了一個數據結構——進程控制塊 Process Control Block,它是進程實體的一部分,是操作系統中最重要的記錄型數據結構。
PCB 的作用是使一個在多道程序環境下不能獨立運行的程序,成爲一個能獨立運行的基本單位,一個能與其它進程併發執行的進程 :
-
作爲獨立運行基本單位的標誌
-
實現間斷性的運行方式
-
提供進程管理所需要的信息
-
提供進程調度所需要的信息
-
實現與其他進程的同步與通信
3.2.1 PCB 信息
PCB爲實現上述功能,內部包含衆多信息:
-
進程標識符:用於唯一地標識一個進程,一個進程通常有兩種標識符:
內部進程標識符:標識各個進程,每個進程都有一個並且唯一的標識符,設置內部標識符主要是爲了方便系統使用。
外部進程標識符:它由創建者提供,可設置用戶標識,以指示擁有該進程的用戶。往往是由用戶進程在訪問該進程時使用。一般爲了描述進程的家族關係,還應設置父進程標識及子進程標識。
-
處理機狀態:由各種寄存器組成。包含許多信息都放在寄存器中,方便程序restart。
通用寄存器、指令計數器、程序狀態字PSW、用戶棧指針等信息。
-
進程調度信息
進程狀態:指明進程的當前狀態,作爲進程調度和對換時的依據。
進程優先級:用於描述進程使用處理機的優先級別的一個整數,優先級高的進程應優先獲得處理機
進程調度所需的其它信息:與所採用的進程調度算法有關,如進程已等待CPU的時間總和、進程已執行的時間總和等。
事件:指進程由執行狀態轉變爲阻塞狀態所等待發生的事件,即阻塞原因。
-
資源清單
有關內存地址空間或虛擬地址空間的信息,所打開文件的列表和所使用的 I/O 設備信息。
3.2.2 PCB 組織方式
操作系統中有太多 PCB,如何管理是個問題,一般有如下方式。
 線下數組
線下數組
-
線性方式:
將系統所有PCB都組織在一張線性表中,將該表首地址存在內存的一個專用區域
實現簡單,開銷小,但是每次都需要掃描整張表,適合進程數目不多的系統
 索引方式
索引方式
-
索引方式:
將同一狀態的進程組織在一個索引表中,索引表項指向相應的 PCB,不同狀態對應不同的索引表。
 鏈表方式
鏈表方式
-
鏈接方式:
把同一狀態的PCB鏈接成一個隊列,形成就緒隊列、阻塞隊列、空白隊列等。對其中的就緒隊列常按進程優先級的高低排列,優先級高排在隊前。
因爲進程創建、銷燬、調度頻繁,所以一般採用此模式。
3.3 進程控制
進程控制是進程管理最基本的功能,主要包括創建新進程,終止已完成的進程,將發生異常的進程置於阻塞狀態,將進程喚醒等。
3.3.1 進程創建
父進程可創建子進程,父進程終止後子進程也會被終止。子進程可繼承父進程所有資源,子進程終止需將自己所繼承的資源歸還父進程。接下來看下創建的大致流程。
-
爲新進程分配唯一進件標識號,然後創建一個空白PCB,需注意PCB數量是有限的,所以可能會創建失敗。
-
嘗試爲新進程分配所需資源,如果資源不足進程會進入等待狀態。
-
初始化PCB,有如下幾個操作。
標識信息:將系統分配的標識符和父進程標識符填入新PCB
處理機狀態信息:使程序計數器指向程序入口地址,使棧指針指向棧頂
處理機控制信息:將進程設爲就緒/靜止狀態,通常設爲最低優先級
-
如果進程調度隊列能接納新進程,就將進程插入到就緒隊列,等待被調度運行。
3.3.2 進程終止
進程終止情況一般分爲正常結束、異常結束、外界干預三種。
-
正常結束
-
異常結束
越界錯:訪問的存儲區越出該進程的區域
保護錯:試圖訪問不允許訪問的資源,或以不適當的方式訪問(寫只讀)
非法指令:試圖執行不存在的指令(可能是程序錯誤地轉移到數據區,數據當成了指令)
特權指令出錯:用戶進程試圖執行一條只允許OS執行的指令
運行超時:執行時間超過指定的最大值
等待超時:進程等待某件事超過指定的最大值
算數運算錯:試圖執行被禁止的運算(被0除)
I/O故障
-
外界干預
操作員或OS干預(死鎖)
父進程請求,子進程完成父進程指定的任務時
父進程終止,所有子進程都應該結束
終止過程:
-
根據被終止進程的標識符,從PCB集合中檢索出該PCB,讀取進程狀態
-
若處於執行狀態則立即終止執行,將CPU資源分配給其他進程。
-
若進程有子孫進程則將其所有子孫進程終止。
-
全部資源還給父進程或操作系統。
-
該進程的PCB從所在隊列/鏈表中移出。
3.3.3 進程阻塞
意思是該進程執行半路被阻塞,必須由某個事件進程喚醒該進程。常見的就是IO讀取操作。常見阻塞時機/事件如下:
-
請求共享資源失敗,系統無足夠資源分配
-
等待某種操作完成
-
新數據尚未到達(相互合作的進程)
-
等待新任務
阻塞流程:
-
找到要被阻塞進程標識號對應的 PCB。
-
將該進程由運行狀態轉換爲阻塞狀態。
-
將該 進程PCB 插入的阻塞隊列中去。
3.3.4 進程喚醒
喚醒 原語 wake up,一般和阻塞成對使用。喚醒過程如下:
-
從阻塞隊列找到所需PCB。
-
PCB從阻塞隊列溢出,然後變爲就緒狀態。
-
從阻塞隊列溢出該PCB然後插入到就緒狀態隊列等待被分配CPU資源。
3.4 進程調度
進程數一般會大於CPU個數,進程狀態切換主要由調度程序進行調度。一般情況下CPU調度時主要分爲搶佔式調度跟非搶佔式調度。
-
非搶佔式:讓進程運行直到結束或阻塞的調度方式, 容易實現,適合專用系統。 -
搶佔式:每個進程獲得時間片纔可以被CPU調度運行, 可防止單一進程長時間獨佔CPU 系統開銷大。
3.4.1 進程調度原則
-
CPU 利用率
CPU利用率 = 忙碌時間 / 總時間。
調度程序應該儘量讓 CPU 始終處於忙碌的狀態,這可提高 CPU 的利用率。比如當發生IO讀取時候,不要傻傻等待,去執行下別的進程。
-
系統吞吐量
系統吞吐量 = 總共完成多少個作業 / 總共花費時間。
長作業的進程會佔用較長的 CPU 資源導致降低吞吐量,相反短作業的進程會提升系統吞吐量。
-
週轉時間
週轉時間 = 作業完成時間 - 作業提交時間。
平均週轉時間 = 各作業週轉時間和 / 作業數
帶權週轉時間 = 作業週轉時間 / 作業實際運行時間
平均帶權週轉時間 = 各作業帶權週轉時間之和 / 作業數
儘可能使週轉時間降低。
-
等待時間
指的是進程在等待隊列中等待的時間,一般也需要儘可能短。
響應時間
響應時間 = 系統第一次響應時間 - 用戶提交時間,在交互式系統中響應時間是衡量調度算法好壞的主要標準。
3.4.2 調度算法
FCFS 算法
-
First Come First Severd 先來先服務算法,遵循先來後端原則,每次從就緒隊列拿等待時間最久的,運行完畢後再拿下一個。
-
該模式對長作業有利,適用 CPU 繁忙型作業的系統,不適用 I/O 型作業,因爲會導致進程CPU利用率很低。
SJF 算法
-
Shortest Job First 最短作業優先算法,該算法會優先選擇運行所需時間最短的進程執行,可提高吞吐量。
-
跟FCFS正好相反,對長作業很不利。
SRTN 算法
-
Shortest Remaining Time Next 最短剩餘時間優先算法,可以認爲是SJF的搶佔式版本,當一個新就緒的進程比當前運行進程具有更短完成時間時,系統搶佔當前進程,選擇新就緒的進程執行。
-
有最短的平均週轉時間,但不公平,源源不斷的短任務到來,可能使長的任務長時間得不到運行。
HRRN 算法
-
Highest Response Ratio Next 最高響應比優先算法,爲了平衡前面倆而生,按照響應優先權從高到低依次執行。屬於前面倆的折中權衡。
-
優先權 = (等待時間 + 要求服務時間) / 要求服務時間
RR 算法
-
Round Robin 時間片輪轉算法,操作系統設定了個時間片Quantum,時間片導致每個進程只有在該時間片內纔可以運行,這種方式導致每個進程都會均勻的獲得執行權。
-
時間片一般20ms~50ms,如果太小會導致系統頻繁進行上下文切換,太大又可能引起對短的交互請求的響應變差。
HPF 算法
-
Highest Priority First 最高優先級調度算法,從就緒隊列中選擇最高優先級的進程先執行。
-
優先級的設置有初始化固定死的那種,也有在代碼運轉過程中根據等待時間或性能動態調整 這兩種思路。
-
缺點是可能導致低優先級的一直無法被執行。
MFQ 算法
-
Multilevel Feedback Queue 多級反饋隊列調度算法 ,可以認爲是 RR 算法 跟 HPF 算法 的綜合體。
-
系統會同時存在多個就緒隊列,每個隊列優先級從高到低排列,同時優先級越高獲得是時間片越短。
-
新進程會先加入到最高優先級隊列,如果新進程優先級高於當前在執行的進程,會停止當前進程轉而去執行新進程。新進程如果在時間片內沒執行完畢需下移到次優先級隊列。
 多級反饋隊列調度算法
多級反饋隊列調度算法
 多級反饋隊列調度算法
多級反饋隊列調度算法3.5 線程
3.5.1 線程定義
早期操作系統是沒有線程概念的,線程是後來加進來的。爲啥會有線程呢?那是因爲以前在多進程階段,經常會涉及到進程之間如何通訊,如何共享數據的問題。並且進程關聯到PCB的生命週期,管理起來開銷較大。爲了解決這個問題引入了線程。
線程是進程當中的一個執行流程。同一個進程內的多個線程之間可以共享進程的代碼段、數據段、打開的文件等資源。同時每個線程又都有一套獨立的寄存器和棧來確保線程的控制流是獨立的。
進程有個PCB來管理,同理操作系統通過 Thread Control Block線程控制塊來實現線程的管控。
3.5.2 線程優缺點
優點
-
一個進程中可以同時存在1~N個線程,這些線程可以併發的執行。
-
各個線程之間可以共享地址空間和文件等資源。
缺點
-
當進程中的一個線程奔潰時,會導致其所屬進程的所有線程奔潰。
-
多線程編程,讓人頭大的東西。
-
線程執行開銷小,但不利於資源的隔離管理和保護,而進程正相反。
3.5.3 進程跟線程關聯
進程:
-
是系統進行資源分配和調度的一個獨立單位.
-
是程序的一次執行,每個進程都有自己的地址空間、內存、數據棧及其他輔助記錄運行軌跡的數據
線程:
-
是進程的一個實體,是CPU調度和分派的基本單位,它是比進程更小的能獨立運行的基本單位
-
所有的線程運行在同一個進程中,共享相同的運行資源和環境
-
線程一般是併發執行的,使得實現了多任務的並行和數據共享。
進程線程區別:
-
一個線程只能屬於一個進程,而一個進程可以有多個線程,但至少有一個線程。
-
線程的劃分尺度小於進程(資源比進程少),使得多線程程序的併發性高。
-
進程在執行過程中擁有獨立的內存單元,而多個線程共享內存,從而極大地提高了程序的運行效率。
-
資源分配給進程,同一進程的所有線程共享該進程的所有資源。
-
CPU分配資源給進程,但真正在CPU上運行的是線程。
-
線程不能夠獨立執行,必須依存在進程中。
線程快在哪兒?
-
線程創建的時有些資源不需要自己管理,直接從進程拿即可,線程管理寄存器跟棧的生命週期即可。
-
同進程內多線程共享數據,所以進程數據傳輸可以用zero copy技術,不需要經過內核了。
-
進程使用一個虛擬內存跟頁表,然後多線程共用這些虛擬內存,如果同進程內兩個線程進行上下文切換比進程提速很多。
3.5.4 線程實現
在前面的內存管理中說到了內核態跟用戶態。相對應的線程的創建也分爲用戶態線程跟內核態線程。
3.5.4.1 用戶態線程
在用戶空間實現的線程,由用戶態的線程庫來完成線程的管理。操作系統按進程維度進行調度,當線程在用戶態創建時應用程序在用戶空間內要實現線程的創建、維護和調度。操作系統對線程的存在一無所知!操作系統只能看到進程看不到線程。所有的線程都是在用戶空間實現。在操作系統看來,每一個進程只有一個線程。
 用戶態線程
用戶態線程
好處:
-
及時操作系統不支持線程模式也可以通過用戶層庫函數來支持線程模式,TCB 由用戶級線程庫函數來維護。
-
使用庫函數模式實現線程可以避免用戶態到內核態的切換。
壞處:
-
CPU不知道線程存在,CPU的時間片切換是以進程爲維度的,某個線程因爲IO等操作導致線程阻塞,操作系統會阻塞整個進程,即使這個進程中其它線程還在工作。
-
用戶態線程沒法打斷正在運行中的線程,除非線程主動交出CPU使用權。
3.5.4.2 內核態線程
在內核中實現的線程,是由內核管理的線程,線程對應的 TCB 在操作系統裏,這樣線程的創建、終止和管理都是由操作系統負責。內線程模式下一個用戶線程對應一個內核線程。
 內核態線程
內核態線程
注意:Linux中的JVM從1.2版以後是基於pthread實現的,所以現在Java中線程的本質就是操作系統中的線程。
優點:
-
一個進程中某個線程阻塞不會影響其他內核線程運行。
-
用戶態模式一個時間片分給多個線程,內核態模式直接分配給線程的時間片增加。
缺點:
-
內核級線程調度開銷較大。調度內核線程的代價可能和調度進程差不多昂貴,代價要比用戶級線程大很多。一個線程默認棧=1M,線程多了會導致內存消耗很大。
-
線程表是存放在操作系統固定的表格空間或者堆棧空間裏,所以內核級線程的數量是有限的。
3.4.4.3 輕量級進程
最初的進程定義都包含程序、資源及其執行三部分,其中程序通常指代碼,資源在操作系統層面上通常包括內存資源、IO資源、信號處理等部分,而程序的執行通常理解爲執行上下文,包括對CPU的佔用,後來發展爲線程。在線程概念出現以前,爲了減小進程切換的開銷,操作系統設計者逐漸修正進程的概念,逐漸允許將進程所佔有的資源從其主體剝離出來,允許某些進程共享一部分資源,例如文件、信號,數據內存,甚至代碼,這就發展出輕量進程的概念。
Light-weight process 輕量級進程是內核支持的用戶線程,它是基於內核線程的高級抽象,系統只有先支持內核線程纔能有 LWP。一個進程可有1~N個LWP,每個 LWP 是跟內核線程一對一映射的,也就是 LWP 都是由一個內核線程支持。
 LWP模式
LWP模式
輕量級進程本質還是進程,只是跟普通進程相比LWP跟其他進程共享大部分邏輯地址空間跟系統資源,LWP輕量體現在它只有一個最小的執行上下文和調度程序所需的統計信息。他是進程的執行部分,只帶有執行相關的信息。
Linux特性:
-
Linux中沒有真正的線程,因爲Linux並沒有爲線程準備特定的數據結構。在內核看來只有進程而沒有線程,在調度時也是當做進程來調度。Linux所謂的線程其實是與其他進程共享資源的進程。但windows中確實有線程。
-
Linux中沒有的線程,線程是由進程來模擬實現的。
-
所以在Linux中在CPU角度看,進程被稱作輕量級進程LWP。
3.5.5 協程
3.5.5.1 協程定義
大多數web服務跟互聯網服務本質上大部分都是 IO 密集型服務,IO 密集型服務的瓶頸不在CPU處理速度,而在於儘可能快速的完成高併發、多連接下的數據讀寫。以前有兩種解決方案:
-
多進程:存在頻繁調度切換問題,同時還會存在每個進程資源不共享的問題,需要額外引入進程間通信機制來解決。 -
多線程:高併發場景的大量 IO 等待會導致多線程被頻繁掛起和切換,非常消耗系統資源,同時多線程訪問共享資源存在競爭問題。
此時協程出現了,協程 Coroutines 是一種比線程更加輕量級的微線程。類比一個進程可以擁有多個線程,一個線程也可以擁有多個協程。可以簡單的把協程理解成子程序調用,每個子程序都可以在一個單獨的協程內執行。
 協程
協程
協程運行在線程之上,當一個協程執行完成後,可以選擇主動讓出,讓另一個協程運行在當前線程之上。協程並沒有增加線程數量,只是在線程的基礎之上通過分時複用的方式運行多個協程,而且協程的切換在用戶態完成,切換的代價比線程從用戶態到內核態的代價小很多,一般在Python、Go中會涉及到協程的知識,尤其是現在高性能的腳本Go。
3.5.5.2 協程注意事項
協程運行在線程之上,並且協程調用了一個阻塞IO操作,此時操作系統並不知道協程的存在,它只知道線程,因此在協程調用阻塞IO操作時,操作系統會讓線程進入阻塞狀態,當前的協程和其它綁定在該線程之上的協程都會陷入阻塞而得不到調度。
因此在協程中不能調用導致線程阻塞的操作,比如打印、讀取文件、Socket接口等。協程只有和異步IO結合起來才能發揮最大的威力。並且協程只有在IO密集型的任務中才會發揮作用。
3.6 進程通信
進程的用戶地址空間是相互獨立的,不可以互相訪問,但內核空間是進程都共享的,所以進程之間要通信必須通過內核。進程間通信主要通過管道、消息隊列、共享內存、信號量、信號、Socket編程。
3.6.1 管道
管道主要分爲匿名管道跟命名管道兩種,可以實現數據的單向流動性。使用起來很簡單,但是管道這種通信方式效率低,不適合進程間頻繁地交換數據。
匿名管道:
-
日常Linux系統中的
|就是匿名管道。指令的前一個輸入是後一個指令的輸出。
命名管道:
-
一般通過
mkfifo SoWhatPipe創建管道。通過echo "sw" > SoWhatPipe跟cat < SoWhatPipe實現輸入跟輸出。
匿名管道的實現依賴int pipe(int fd[2])函數,其中fd[0]是讀取斷描述符,fd[1]是管道寫入端描述符。它的本質就是在內核中創建個屬於內存的緩存,從一端輸入無格式數據一端輸出無格式數據,需注意管道傳輸大小是有限的。
 管道通信底層
管道通信底層
匿名管道的通信範圍是存在父子關係的進程。由於管道沒有實體,也就是沒有管道文件,不會涉及到文件系統。只能通過fork子進程來複制父進程 fd 文件描述符,父子進程通過共用特殊的管道文件實現跨進程通信,並且因爲管道只能一端寫入,另一端讀出,所以通常父子進程遵從如下要求:
-
父進程關閉讀取的 fd[0],只保留寫入的 fd[1]。
-
子進程關閉寫入的 fd[1],只保留讀取的 fd[0]。
 shell管道通信
shell管道通信
需注意Shell執行匿名管道 a | b其實是通過Shell父進程fork出了兩個子進程來實現通信的,而ab之間是不存在父子進程關係的。而命名管道是可以直接在不想關進程間通信的,因爲有管道文件。
3.6.2 消息隊列
 消息隊列消息隊列是保存在內核中的消息鏈表,會涉及到用戶態跟內核態到來回切換,雙方約定好消息體到數據結構,然後發送數據時將數據分成一個個獨立的數據單元消息體,需注意消息隊列及單個消息都有上限,日常我們到RabbitMQ、Redis 都涉及到消息隊列。
消息隊列消息隊列是保存在內核中的消息鏈表,會涉及到用戶態跟內核態到來回切換,雙方約定好消息體到數據結構,然後發送數據時將數據分成一個個獨立的數據單元消息體,需注意消息隊列及單個消息都有上限,日常我們到RabbitMQ、Redis 都涉及到消息隊列。
3.6.3 共享內存
 共享空間
共享空間
現代操作系統對內存管理採用的是虛擬內存技術,也就是每個進程都有自己獨立的虛擬內存空間,不同進程的虛擬內存映射到不同的物理內存中。所以,即使進程A和進程B虛擬地址是一樣的,真正訪問的也是不同的物理內存地址,該模式不涉及到用戶態跟內核態來回切換,JVM 就是用的共享內存模式。並且併發編程也是個難點。
3.6.4 信號量
既然共享內存容易造成數據紊亂,那爲了簡單的實現共享數據在任意時刻只能被一個進程訪問,此時需要信號量。
信號量其實是一個整型的計數器,主要用於實現進程間的互斥與同步,而不是用於緩存進程間通信的數據。
信號量表示資源的數量,核心點在於原子性的控制一個數據的值,控制信號量的方式有PV兩種原子操作:
-
P 操作會把信號量減去 -1,相減後如果信號量 < 0,則表明資源已被佔用,進程需阻塞等待。相減後如果信號量 >= 0,則表明還有資源可使用,進程可正常繼續執行。
-
V 操作會把信號量加上 1,相加後如果信號量 <= 0,則表明當前有阻塞中的進程,於是會將該進程喚醒運行。相加後如果信號量 > 0,則表明當前沒有阻塞中的進程。
3.6.5 信號
對於異常狀態下進程工作模式需要用到信號工作方式來通知進程。比如Linux系統爲了響應各種事件提供了很多異常信號kill -l,信號是進程間通信機制中唯一的異步通信機制,可以在任何時候發送信號給某一進程。比如:
-
kill -9 1412 ,表示給 PID 爲 1412 的進程發送 SIGKILL 信號,用來立即結束該進程。
-
鍵盤 Ctrl+C 產生 SIGINT 信號,表示終止該進程。
-
鍵盤 Ctrl+Z 產生 SIGTSTP 信號,表示停止該進程,但還未結束。
有信號發生時,進程一般有三種方式響應信號:
-
執行默認操作:Linux操作系統爲衆多信號配備了專門的處理操作。
-
捕捉信號:給捕捉到的信號配備專門的信號處理函數。
-
忽略信號:專門用來忽略某些信號,但 SIGKILL 和 SEGSTOP是無法被忽略的,爲了能在任何時候結束或停止某個進程而存在。
3.6.6 Socket編程
前面提到的管道、消息隊列、共享內存、信號量和信號都是在同一臺主機上進行進程間通信,那要想跨網絡與不同主機上的進程之間通信,就需要 Socket 通信。
int socket(int domain, int type, int protocal)
上面是socket編程的核心函數,可以指定IPV4或IPV6類型,TCP或UDP類型。比如TCP協議通信的 socket 編程模型如下:
 Socket編程
Socket編程
-
服務端和客戶端初始化
socket,得到文件描述符。 -
服務端調用
bind,將綁定在 IP 地址和端口。 -
服務端調用
listen,進行監聽。 -
服務端調用
accept,等待客戶端連接。 -
客戶端調用
connect,向服務器端的地址和端口發起連接請求。 -
服務端
accept返回用於傳輸的socket的文件描述符。 -
客戶端調用
write寫入數據,服務端調用read讀取數據。 -
客戶端斷開連接時,會調用
close,那麼服務端read讀取數據的時候,就會讀取到了EOF,待處理完數據後,服務端調用 close,表示連接關閉。 -
服務端調用
accept時,連接成功會返回一個已完成連接的socket,後續用來傳輸數據。服務端有倆socket,一個叫作監聽socket,一個叫作已完成連接socket。 -
成功連接建立之後雙方開始通過 read 和 write 函數來讀寫數據。
 UDP傳輸
UDP傳輸
UDP比較簡單,屬於類似廣播性質的傳輸,不需要維護連接。但也需要 bind,每次通信時調用 sendto 和 recvfrom 都要傳入目標主機的 IP 地址和端口。
3.7 多線程編程
既然多進程開銷過大,那平常我們經常使用到的就是多線程編程了。期間可能涉及到內存模型、JMM、Volatile、臨界區等等。這些在Java併發編程專欄有講。
4、文件管理
4.1 VFS 虛擬文件系統
文件系統在操作系統中主要負責將文件數據信息存儲到磁盤中,起到持久化文件的作用。文件系統的基本組成單元就是文件,文件組成方式不同就會形成不同的文件系統。
文件系統有很多種而不同的文件系統應用到操作系統後需要提供統一的對外接口,此時用到了一個設計理念沒有什麼是加一層解決不了的,在用戶層跟不同的文件系統之間加入一個虛擬文件系統層 Virtual File System。
虛擬文件系統層定義了一組所有文件系統都支持的數據結構和標準接口,這樣程序員不需要了解文件系統的工作原理,只需要瞭解 VFS 提供的統一接口即可。
 虛擬文件系統
虛擬文件系統
日常的文件系統一般有如下三種:
-
磁盤文件系統:就是我們常見的EXT 2/3/4系列。 -
內存文件系統:數據沒存儲到磁盤,佔用內存數據,比如/sys、/proc。進程中的一些數據映射到/proc中了。 -
網絡文件系統:常見的網盤掛載NFS等,通過訪問其他主機數據實現。
4.2 文件組成
以Linux系統爲例,在Linux系統中一切皆文件,Linux文件系統會爲每個文件分配索引節點 inode跟目錄項directory entry來記錄文件內容跟目錄層次結構。
4.2.1 inode
要理解inode要從文件儲存說起。文件存儲在硬盤上,硬盤的最小存儲單位叫做扇區。每個扇區儲存512字節。操作系統讀取硬盤的時候,不會一個個扇區的讀取,這樣效率太低,一般一次性連續讀取8個扇區(4KB)來當做一塊,這種由多個扇區組成的塊,是文件存取的最小單位。
文件數據都儲存在塊中,我們還必須找到一個地方儲存文件的元信息,比如inode編號、文件大小、創建時間、修改時間、磁盤位置、訪問權限等。幾乎除了文件名以爲的所有文件元數據信息都存儲在一個叫叫索引節點inode的地方。可通過stat 文件名查看 inode 信息
每個inode都有一個號碼,操作系統用inode號碼來識別不同的文件。Unix/Linux系統內部不使用文件名,而使用inode號碼來識別文件,用戶可通過ls -i查看每個文件對應編號。對於系統來說文件名只是inode號碼便於識別的別稱或者綽號。特殊名字的文件不好刪除時可以嘗試用inode號刪除,移動跟重命名不會導致文件inode變化,當用戶嘗試根據文件名打開文件時,實際上系統內部將這個過程分成三步:
-
系統找到這個文件名對應的inode號碼。
-
通過inode號碼,獲取inode信息,進行權限驗證等操作。
-
根據inode信息,找到文件數據所在的block,讀出數據。
需注意 inode也會消耗硬盤空間,硬盤格式化後會被分成超級塊、索引節點區和數據塊區三個區域:
-
超級塊區:用來存儲文件系統的詳細信息,比如塊大小,塊個數等信息。一般文件系統掛載後就會將數據信息同步到內存。 -
索引節點區:用來存儲索引節點 inode table。每個inode一般爲128字節或256字節,一般每1KB或2KB數據就需設置一個inode。一般爲了加速查詢會把索引數據緩存到內存。 -
數據塊區:真正存儲磁盤數據的地方。df -i # 查看每個硬盤分區的inode總數和已經使用的數量
sudo dumpe2fs -h /dev/hda | grep "Inode size" # 查看每個inode節點的大小
4.2.2 目錄
Unix/Linux系統中目錄directory也是一種文件,打開目錄實際上就是打開目錄文件。目錄文件內容就是一系列目錄項的列,目錄項的內容包含文件的名字、文件類型、索引節點指針以及與其他目錄項的層級關係。
爲避免頻繁讀取磁盤裏的目錄文件,內核會把已經讀過的目錄文件用目錄項這個數據結構緩存在內存,方便用戶下次讀取目錄信息,目錄項可包含目錄或文件,不要驚訝於可以保存目錄,目錄格式的目錄項裏面保存的是目錄裏面一項一項的文件信息。
4.2.3 軟連接跟硬鏈接
 軟連接跟硬鏈接
軟連接跟硬鏈接
硬鏈接:老文件A被創建若干個硬鏈接B、C後。A、B、C三個文件的inode是相同的,所以不能跨文件系統。同時只有ABC全部刪除,系統纔會刪除源文件。
軟鏈接:相當於基於老文件A新建了個文件B,該文件B有新的inode,不過文件B內容是老文件A的路徑。所以軟鏈接可以跨文件系統。當老文件A刪除後,文件B仍然存在,不過找不到指定文件了。
[sowhat@localhost ~]$ ln [選項] 源文件 目標文件
選項:
-s:建立軟鏈接文件。如果不加 "-s" 選項,則建立硬鏈接文件;
-f:強制。如果目標文件已經存在,則刪除目標文件後再建立鏈接文件;
4.3 文件存儲
說文件存儲前需瞭解文件系統操作基本單位是數據塊,而平常用戶操作字節到數據塊之間是需要轉換的,當然這些文件系統都幫我們對接好了。接下來看文件系統是如何按照數據塊, 文件在磁盤中存儲時候主要分爲連續空間存儲跟非連續空間存儲
4.3.1 連續空間存儲
-
實現:連續空間存儲的意思就跟數組存儲一樣,找個連續的空間一次性把數據存儲進去,文件頭存儲起始位置跟數據長度即可。 -
優勢:讀寫效率高,磁盤尋址一次即可。 -
劣勢:容易產生空間碎片,並且文件擴容不方便。 連續存儲
連續存儲
 連續存儲
連續存儲4.3.2 非連續空間存儲之鏈表
隱式鏈表
-
實現:文件頭包含StartBlock、EndBlock。每個BLock有隱藏的next指針,跟單向鏈表一樣。 -
缺點:只能通過鏈式不斷往下查找數據,不支持快速直接訪問。
 隱式鏈表
隱式鏈表
顯式鏈表
-
實現:把每個Block中的next指針存儲到內存文件分配表中,通過遍歷數組方式實現拿到全部數據。 -
缺點:前面說1KB就有個inode指針,如果磁盤數據很大那就需要很大的文件分配表來存儲映射關係了, 顯示鏈表
顯示鏈表
 顯示鏈表
顯示鏈表4.3.3 非連續空間存儲之索引
-
實現:整個文件類型一本新華字典,真實的數據塊在詞典實際位置存儲着,但文件所需數據塊的索引位置會被彙總起來形成目錄索引放在字典前頭。 -
優勢:不會產生碎片,文件可動態擴容,並且支持順序跟隨機讀寫。 -
劣勢:可能一個小文件都要佔用一個目錄索引,文件過大導致索引指針一個容不下,可能還需要有多級索引或索引+鏈表模式。
 索引存儲
索引存儲
這些存儲方式各有利弊,所以操作系統才存儲的時候一般是根據文件的大小進行動態的變化存儲方式的,跟STL中的快排底層 = 快排 + 插入排序 + 堆排 一樣的道理。
4.3.4 空閒空間管理
爲了避免用戶存儲數據時候遍歷全部磁盤空間來尋找可以數據塊,一般有如下幾種記錄方法。
-
空閒表:動態的維護一個空閒數據塊列表,每行存儲空閒塊的開始位置跟空閒長度。適合少量有少量空閒數據塊時。 空閒表
空閒表 -
空閒鏈表:將空閒的數據庫用next指針串聯起來,缺點是不能隨機訪問。 空閒鏈表
空閒鏈表 -
位圖法:利用Bit的 01 表示數據塊可用跟不可用,簡單方便,inode跟空閒數據庫都用的此方法。 位圖法
位圖法
 空閒表
空閒表 空閒鏈表
空閒鏈表 位圖法
位圖法
5、輸入輸出管理
5.1 設備控制器跟驅動程序
5.1.1 設備控制器
 設備控制器
設備控制器
操作系統爲統一管理衆多的設備並且屏蔽設備之間的差異,給每個設備都安裝了個小CPU叫設備控制器。每個設備控制器都知道自己對應外設的功能跟用法,並且每個設備控制器都有獨有的寄存器用來跟CPU通信。
-
讀設備寄存器值瞭解設備狀態,是否可以接收新指令。
-
操作系統給設備寄存器寫入一些指令可以實現發送數據、接收數據等等操作。
控制器一般分爲數據寄存器、命令寄存器跟狀態寄存器,CPU 通過讀、寫設備控制器中的寄存器來便捷的控制設備:
-
數據寄存器:CPU 向 I/O 設備寫入需要傳輸的數據,比如打印what,CPU 就要先發送一個w字符給到對應的 I/O 設備。 -
命令寄存器:CPU 發送命令來告訴 I/O 設備要進行輸入/輸出操作,於是就會交給 I/O 設備去工作,任務完成後,會把狀態寄存器裏面的狀態標記爲完成。 -
狀態寄存器:用來告訴 CPU 現在已經在工作或工作已經完成,只有狀態寄存標記成已完成,CPU 才能發送下一個字符和命令。
同時輸入輸出設備可分爲塊設備跟字符設備。
-
塊設備:用來把數據存儲在固定大小的塊中,每個塊有自己的地址,硬盤、U盤等是常見的塊設備。塊設備一般數據傳輸較大爲避免頻繁IO,控制器中有個可讀寫等數據緩衝區。Linux操作系統爲屏蔽不同塊設備帶來的差異引入了通用塊層,通用塊層是處於文件系統和磁盤驅動中間的一個塊設備抽象層,主要提供如下倆功能:
向上爲文件系統和應用程序,提供訪問塊設備的標準接口,向下把各種不同的磁盤設備抽象爲統一的塊設備,並在內核層面提供一個框架來管理這些設備的驅動程序。
通用層還會給文件系統和應用程序發來的 I/O進行調度,主要目的是爲了提高磁盤讀寫的效率。
-
字符設備:以字符爲單位發送或接收一個字符流,字符設備是不可尋址的,也沒有任何尋道操作,鼠標是常見的字符設備。
CPU一般通過IO端口跟內存映射IO來跟設備的控制寄存器和數據緩衝區進行通信
-
IO端口:每個控制寄存器被分配一個 I/O 端口,可以通過特殊的彙編指令操作這些寄存器,比如 in/out 類似的指令。 -
內存映射IO:將所有控制寄存器映射到內存空間中,這樣就可以像讀寫內存一樣讀寫數據緩衝區。
5.1.2 驅動接口
 驅動程序
驅動程序
設備控制器屏蔽了設備細節,但每種設備的控制器的寄存器、緩衝區等使用模式都是不同的,它屬於硬件。在操作系統圖範疇內爲了屏蔽設備控制器的差異,引入了設備驅動程序,不同設備到驅動程序會提供統一接口給操作系統來調用,這樣操作系統內核會像調用本地代碼一樣使用設備驅動程序接口。
設備發出IO請求就是在設備驅動程序中來響應到,它會根據中斷類型調用響應到中斷處理程序進行處理。
 中斷請求流程
中斷請求流程
5.2 IO 控制
CPU發送指令讓那個設備控制器去讀寫數據,完畢後如何通知CPU呢?
5.2.1 輪詢模式
控制器中有個狀態寄存器,CPU不斷輪詢查看寄存器狀態,該模式會傻瓜式的一直佔用CPU。
 輪詢模式
輪詢模式
5.2.2 IO 中斷請求
 中斷模式
中斷模式
控制器有個中斷控制器,當設備完成任務後觸發中斷到中斷控制器,中斷控制器就通知 CPU來處理中斷請求。中斷有兩種,一種是軟中斷,比如代碼調用 INT 指令觸發。一種是硬件中斷,硬件通過中斷控制器觸發的。但中斷方式對於頻繁讀寫磁盤數據的操作就不太友好了,會頻繁打斷CPU。
這裏說下磁盤高速緩存 PageCache,它是用來緩存最近被CPU訪問的數據到內存中,並且還具有預讀功能,可能你讀前16KB數據,已經把後16KB數據給你緩存好了。
pagecache : 頁緩存,當進程需讀取磁盤文件時,linux先分配一些內存,將數據從磁盤讀區到內存中,然後再將數據傳給進程。當進程需寫數據到磁盤時,linux先分配內存接收用戶數據,然後再將數據從內存寫到磁盤。同時pagecache由於大小受限,所以一般只緩存最近被訪問的數據,數據不足時還需訪問磁盤。
5.2.3 DMA 模式
Direct Memory Access 直接內存訪問,在硬件DMA控制器的支持下,在進行 I/O 設備和內存的數據傳輸的時候,數據搬運的工作全部交給 DMA 控制器,而 CPU 不再參與任何與數據搬運相關的事情,讓CPU 去處理別的事。
 DMA模式可以發現整個數據傳輸過程中CPU是不會直接參與數據搬運工作,由DMA來直接負責數據讀取工作,現如今每個IO設備一般都自帶DMA控制器。讀數據時候僅僅在傳送開始跟結束時需要CPU干預。
DMA模式可以發現整個數據傳輸過程中CPU是不會直接參與數據搬運工作,由DMA來直接負責數據讀取工作,現如今每個IO設備一般都自帶DMA控制器。讀數據時候僅僅在傳送開始跟結束時需要CPU干預。
5.2.4 Zero Copy
Zero Copy 全程不會通過 CPU 來搬運數據,所有的數據都是通過 DMA 來進行傳輸的,中間只需要經過2次上下文切換跟2次DMA數據拷貝,相比最原始讀寫方式至少速度翻倍。其實在Kafka中已經講過Zero Copy了。
5.2.4.1 老版本讀寫
老版本的簡單讀寫操作中間不對數據做任何操作。期間會發生4次用戶態跟內核態的切換。2次DMA數據拷貝,2次CPU數據拷貝。
 老式讀寫
老式讀寫
提速方法就是需減少用戶態與內核態的上下文切換和內存拷貝的次數。數據傳輸時從內核的讀緩衝區拷貝到用戶的緩衝區,再從用戶緩衝區拷貝到 socket 緩衝區的這個過程是沒有必要的。接下來
接下來按照三個版本說下Zero Copy 發展史。
5.2.4.2 mmap 跟 write
 mmap + write
mmap + write
思路就是用mmap替代read函數,mmap調用時會直接把內核緩衝區裏的數據映射到用戶空間,此時減少了一次數據拷貝,但仍然需要通過 CPU 把內核緩衝區的數據拷貝到 socket 緩衝區裏,而且仍然需要 4 次上下文切換,因爲系統調用還是 2 次。
buf = mmap(file, len);
write(sockfd, buf, len);
5.2.4.3 sendfile
Linux 內核版本 2.1版本提供了函數 sendfile()。
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
out_fd : 目的文件描述符
in_fd:源文件描述符
offset:源文件內偏移量
count:打算複製數據長度
ssize_t:實際上覆制數據的長度
可以發現一個 sendfile = read + write,避免了2次用戶態跟內核態來回切換,並且可以直接把內核緩衝區裏的數據拷貝到 socket 緩衝區裏,這樣就只有 2 次上下文切換,和 3 次數據拷貝。
 sendfile模式
sendfile模式
5.2.4.4 真正的零拷貝
Linux 內核 2.4如果網卡支持SG-DMA 技術,可以減少通過 CPU 把內核緩衝區裏的數據拷貝到 socket 緩衝區的過程。
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
SG-DMA 技術可以直接將內核緩存中的數據拷貝到網卡的緩衝區裏,此過程不需要將數據從操作系統內核緩衝區拷貝到 socket 緩衝區中,這樣就減少了一次數據拷貝。
 ZeroCopy
ZeroCopy
5.2.4.5 文件傳輸規則
不要以爲會了Zero Copy後,無論大小文件都用Zero Copy。實際工作中一般小文件採用Zero Copy技術,而大文件會用異步IO。至於爲啥,且看如下分析:
前面說的數據從磁盤讀到內核緩衝區就是讀到PageCache中,PageCache具有緩存跟預讀功能。但當傳輸超大文件時PageCache會不失效,因爲大文件會快速佔滿PageCache區,但這些文件又只是一次訪問,會造成其他熱點小文件無法使用PageCache,所以索性不用PageCache,使用異步IO的了。至於異步IO是啥呢?下文在說。
5.3 IO分層
 IO分層
IO分層
Linux 存儲系統的 I/O 由上到下可以分爲文件系統層、通用塊層、設備層。
-
文件系統層向上爲應用程序統一提供了標準的文件訪問接口,向下會通過通用塊層來存儲和管理磁盤數據。
-
通用塊層包括塊設備的 I/O 隊列和 I/O 調度器,通過IO調度器處理IO請求。
-
設備層包括硬件設備、設備控制器和驅動程序,負責最終物理設備的 I/O 操作。
Linux系統中的IO讀取提速:
-
爲提高文件訪問效率會使用頁緩存、索引節點緩存、目錄項緩存等多種緩存機制,目的是爲了減少對塊設備的直接調用。
-
爲了提高塊設備的訪問效率, 會使用緩衝區,來緩存塊設備的數據。
END
小3W字,終於吹逼完了。希望讀完可以讓你對操作系統有個大概的印象,你在用Window,卻不知經過30年的基礎沉澱,Windows 的完整源代碼樹的大小超過 0.5 TB,涉及超過56萬個文件夾,400 多萬個文件,總規模超十億行。再加上各個功能之間需要兼容性,可維護性,可管理性等這些隨着代碼的越來越多可推敲,最終產生了這樣的一個藝術品!
參考
-
MMU:https://www.zhihu.com/question/63375062
-
OS高頻面試題:https://t.1yb.co/ivNG
-
小林OS:https://t.1yb.co/hwm7