




在經過編寫 CLI 程序的嘗試之後,我們繼續回來聊 Go 語言的基礎知識。
相信實際寫過一些代碼之後,會更容易理解。
原計劃這期聊 數組和切片。考慮到聊切片時,無論如何繞不開指針和引用的話題,乾脆提到前面來。
目錄
[TOC]
指針
指針(Pointer)本質上是一個指向某塊計算機內存的地址。就像日常的門牌地址一樣。只不過內存地址是一個數字編號,對應的是一個個字節(byte)。
當然,高級語言能訪問到的內存,經過了操作系統內存管理的抽象,並不是連續的物理內存,而是映射得到的虛擬內存。但現在不必關注這些細節,當它是連續內存就好。

出於內存安全和屏蔽底層細節的考慮,C++ 以後的高級語言大多不再支持指針,而是改爲使用『引用』。引用和指針的差別,我們後面說。
Go 作爲 C 的『嫡親』後繼,爲了性能和靈活性,保留了指針,而且用法基本一樣。但 Go 增加了 逃逸分析 和 垃圾回收(GC),一定程度上解決掉了 懸掛指針 和 內存泄漏 的問題,降低了開發者的認知負擔。(注意,Go 還是可能發生內存泄漏,只是需要特定的條件,發生概率大大降低了。)
Go 指針
先上代碼,來點直觀認識
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 聲明
var pa, pb *int
// 取址
var a = 10 // 默認爲 int
pa = &a
// 解引用(取值)
var b = *pa
// 輸出
fmt.Println("a:", a)
fmt.Println("b:", b)
fmt.Println("&a:", &a)
fmt.Println("&b:", &b)
fmt.Println("pa:", pa)
fmt.Println("pb:", pb)
fmt.Println("*pa:", *pa)
fmt.Println("*pb:", *pb)
|
關於取址運算符
&和 解引用運算符*的詳細介紹(優先級、可尋址等內容),請參考第 4 期的《運算符》。解引用 dereference:取址 address 的反操作,意味根據類型,從地址中取出對應的值。
上面的代碼輸出
|
1
2
3
4
5
6
7
8
|
a: 10
b: 10
&a: 0xc0000140a0
&b: 0xc0000140a8
pa: 0xc0000140a0
pb: <nil>
*pa: 10
panic: runtime error: invalid memory address or nil pointer dereference
|
指針的零值是 nil ,對一個 nil 指針解引用會引起運行時錯誤,引發一個 panic。
通過下圖,可以清晰看到4 個變量之間的關係。

注1:
int類型在 64 位機器上是 64 位,佔據 8 個字節。注2:兩個指針實際上也是保存在內存上,但是爲了特意區分,也爲了避免內存的圖示畫得太長,所以把它們單獨放在左邊示意。
指針允許程序以簡潔的方式引用另一個(較大的)值而不必拷貝它,允許在不同的地方之間共享一個值,可以簡化很多數據結構的實現。保留指針,讓 Go 的代碼更靈活,以及更好的性能表現。
指針的類型
指針是派生類型,派生自其它類型。類型 *Type 表示『指向 Type 類型變量的指針』,常常簡稱『Type 類型的指針』,其中 Type 可以爲任意類型,被稱作指針的 基類型(base type)。換言之,從 Type 類型,派生出 *Type 類型。
前面說到,內存地址是一個編號,指針的底層類型(underlying type)相當於是整型數(uintptr),寬度與平臺相關,保證可以存下內存地址。
但指針又不僅僅是一個整型數,上面還附加了類型信息。指針指向的類型不同,派生出的指針類型也不同。所以指針不是一個類型,而是一類類型;類型有無數多種,對應的指針(包括指向指針的指針)的類型也有無數種。
*int16 跟 *int8 就是不同類型。它們雖然存了同樣長度的地址,但 基類型 不同,解引用時會有不同的行爲。不同類型的指針之間無法進行轉換。(除非通過 unsafe 包進行強制轉換。包名 unsafe 道出風險,這個包裏的都是危險操作,後果自負。)
|
1
2
3
4
5
6
7
8
9
|
// 爲了方便理解,寫成二進制,高8位的字節是 3,低 8 位的字節是 1,對應的數字是 3x2^8+1 = 769
var c uint16 = 0b00000011_00000001
pc16 := &c
fmt.Println("pc16:", pc16)
fmt.Println("*pc16:", *pc16)
// 爲了演示,將 *uint16 強制轉換爲 *uint8,實際開發中不推薦,除非你清楚自己在做什麼
pc8 := (*uint8)(unsafe.Pointer(pc16))
fmt.Println("pc8:", pc8)
fmt.Println("*pc8:", *pc8)
|
輸出
|
1
2
3
4
|
pc16: 0xc0000a2058
*pc16: 769
pc8: 0xc0000a2058
*pc8: 1
|
可以看到,兩個指針保存了同樣的地址,按理說解引用取出的內容應該是一樣的。但事實是,解引用還跟類型相關:地址只指明瞭取內容的起點,基類型指定取多少個字節,以及如何解釋取出來的比特。在這裏,對 *uint16 解引用取出了兩個字節,按整型數解釋爲 796 ;對 *uint8 解引用則取了一個字節,解釋爲 1 。

這裏還得知了一個額外的信息:我的電腦是小端字節序,換句話說,數字是從低字節到高字節存儲的,也就是 00000001 00000011 ,跟手寫的習慣是相反的,所以纔會在只取一個字節時,取到了低字節。
逃逸分析與垃圾回收
在 C/C++ 裏面使用指針,容易發生兩類問題:
-
懸空指針(dangling pointer):又叫野指針(wild pointer),是指非空的指針沒能指向相應類型的有效對象,或者換句話說,不能解析到一個有效的值。這有可能是對指針做了錯誤的運算,或者目標內存被意外回收了。
-
內存泄漏(memory leak):是指因爲疏忽或者錯誤,沒有釋放已經不再使用的內存,造成內存的浪費。在 C/C++ 這類沒有內存管理的語言裏,常見的泄漏原因是在釋放動態分配的內存之前,就失去了對這些內存的控制。
Go 裏面不允許對指針做算術運算,基本排除對指針運算錯誤導致的問題。剩下還能出問題的,就是釋放內存的時機:釋放早了,懸空指針;釋放晚了或者乾脆沒釋放,內存泄漏。來看看 C 的例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// 注意這是 C 代碼,不要跟 Go 代碼混淆
int* getPtrOnStack()
{
// n 分配在棧上,函數返回即被回收
int n;
int* pi = &n;
return pi;
}
int* mallocInt()
{
// 動態分配的內存分配在堆上,需要自行釋放
return (int*)malloc(sizeof(int));
}
int main()
{
// pi 爲懸空指針
int* pi = getPtrOnStack();
int* pi2 = mallocInt();
// 申請的內存沒有釋放,應該先 free(pi2)
pi2 = 0;
// pi2 置零後,失去了對未釋放內存的控制,因爲地址已經找不回了
// 短時間內一次過運行的程序內存泄漏問題不大,到程序退出都會釋放;
// 但對於需要持續運行的程序,內存泄漏會造成嚴重後果。
}
|
Go 的解決方案是
-
逃逸分析:由編譯器對變量進行逃逸分析,判斷變量的作用域是否超出函數的作用域,以此決定將內存分配在棧上還是堆上,不需要人工指定。這就解決了第一個問題,函數內部聲明的變量,其內存可以在函數返回後繼續使用。
-
垃圾回收:由運行時(runtime)負責不再引用的內存的回收。回收算法一直在改進,這裏不展開。這就解決了第二個問題,當內存不再使用的時候,只要不引用即可(指針置零,或者指向別的內存),不需要手動釋放。
因爲這些改進,Go 裏面的指針看起來跟 C/C++ 差不多,實際使用的負擔卻小很多。
需要注意的是,垃圾回收無法解決『邏輯上』的內存泄漏。這是指程序邏輯已經不再用到某些內存,但是仍然持有這些內存的引用,導致垃圾回收無法識別並回收這些內存。這就好比清潔工只能保證地上和垃圾桶的乾淨,卻無法判斷辦公桌上有哪些東西是沒用的。
字段選擇器
對於操作數 x ,如果想訪問它的成員字段或者方法,可以使用字段選擇器(field selector),實際上就是一個句點 . 加上字段名。
舉例說 p 是 Person 類型的變量,而 Person 有一個 Name 字段和 Run() 方法,就可以通過 p.Name 和 p.Run() 訪問。
這部分的詳細內容,要等到結構體和方法部分再展開。這裏只提一點與 C/C++ 的區別。
還是以 p 和 Person 爲例。在 C/C++ 裏,只有 p 是一個 Person 類型變量的時候(相當於Go 語言的 var p Person ),才能用句點訪問成員字段。如果 p 是一個 Person 類型的指針(相當於 Go 的 var p *Person ),則要用箭頭操作符 -> 訪問成員。p->Name 跟 (*p).Name 等價。
Go 裏沒有箭頭操作符。兩種操作都用字段選擇器 . 表示。實際上這是 Go 提供的一個語法糖,當Go 發現 p 是一個指針而且沒有相應名字的成員時,會自動在 *p 裏尋找對應的成員。
這樣做,好處是省了一個操作符(Go 真的很省操作符和關鍵字),並且將值變量和指針變量的使用統一起來,在很多場景中可以不必關心使用的是一個值還是一個指針。而壞處也在於,在一些場景混淆了這兩者。這個也是到結構體和方法時再細說。這裏給一個直觀的例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
type Person struct {
Name string
}
var d Person
d.Name = "David"
fmt.Println("d.Name", d.Name) // 輸出 d.Name David
pd := &d
fmt.Println("pd.Name", pd.Name) // 輸出 pd.Name David
// 這部分無法通過編譯,錯誤是 ppd.Name undefined (type **Person has no field or method Name)
// ppd := &pd
// fmt.Println("ppd.Name", ppd.Name)
|
從 **Person 的角度看,會覺得很不講理:明明 *Person 也沒有 Name 這個字段啊,爲什麼 pd 不報錯?
因爲編譯器識別到它是一個指針,自動從 *pd 裏找字段。但是這個忙只幫忙向下找一層,對於 ppd ,ppd.Name 不存在,(*ppd).Name 也沒有,就放棄了。
不像在 C/C++ 裏很多操作都依賴指針,指針的指針並不少見,Go 裏很少用到多級指針,所以這種語法糖只包一層大部分情況夠用。
指針、引用和值
這三個概念既存在包含關係,又存在對比,解釋起來非常拗口。如果你看完之後還是雲裏霧裏,請耐心再多看幾遍,或者實際寫代碼感受一下。如果還是不能理解,一定是我水平的問題,請先跳過這一部分。歡迎留言告知你的想法。
在第 2 期《常量與變量》裏,有提到值的定義:『無法進一步求值的表達式(expression)』,例如 4 + 3 * 2 / 1 的值是 10 。而常量和變量,則可以理解爲值的容器。(儘管常量在具體實現上,往往是編譯期直接替換爲目標值。)
這個定義,強調與量並列。
值也可以理解爲『可以被程序操作的實體的表示』。這時不強調與量的區別,如果一個變量保存了一個值,出於方便,有時也稱這個變量爲一個值。
雖然標題將指針、引用和值並列,其實引用和指針,本身也是值。它們都用來表示『可被程序操作的實體』。
同時指針是引用的一種,是最簡單的透明引用。
換言之,三者之間構成這樣一種包含關係:引用是值的一種特例,是一類可以間接訪問其它值的值,區別於直接使用的值;指針是引用的一種特例,是一類簡單的透明引用,區別於不透明的引用。
指針和值
先對比指針和值。
如果不考慮實際使用,從理論上說,指針類型跟別的整型一樣,也是一個『可操作實體』,所以它也是值。在Go 裏,指針跟所有值一樣,賦值和參數傳遞的時候發生了拷貝。

但在使用中,大部分情況下,指針只是改善性能(避免拷貝)、提高代碼靈活性(共享對象)、實現複雜數據結構的工具。我們並不關心指針的值本身,而是關心指針指向的值。爲了方便討論,指針變量跟它指向的值,常常會被等同看待。就像送禮或者頒獎時,不會有人舉着汽車交給對方,而是會遞交車鑰匙;我們會將拿到車鑰匙等同於拿到了車。(特別是 Go 取消了箭頭操作符 ->,值和指針都用同樣的方式訪問成員,更是弱化了這個區分。)
幾乎沒有人會關心指針保存的地址值是多少,只會關心它是否有效,兩個地址是否相等。地址的大小對於程序邏輯幾乎沒有影響。
當強調 指針 和 值 的區別時,這裏的值,就是指我們關心的,可以直接使用的值。
實際上,這些區別同樣存在於 引用 和 值 之間。只是指針的機制更簡單透明,所以用了指針作爲討論的對象。
不透明引用
引用(reference)是指可以讓程序間接訪問其它值的值。指針是最簡單的、透明的引用,也因爲其機制透明和自由使用,是最強大有效的引用。
但透明和自由,也要求使用者更瞭解底層細節,程序更容易出錯。想降低使用難度,避免出錯,就加上限制,屏蔽底層細節,變成不透明引用。例如,無法獲取引用真實的值,無法控制引用的解釋,強制的類型安全,禁止類型轉換,甚至讓它看起來像一個直接訪問的值,不像引用。
當我們將 指針 和 引用 並列時,指的就是不透明引用。
來看看其它語言的情況:
-
C++ 既有指針也有引用。C++ 的引用更接近別名(alias),是受限的指針(不能讀取或修改地址值,也不需要顯式的解引用,所有操作都作用於指向的值)。
-
Python 和 Java 都取消了指針,只保留了引用。Java 的基本類型是直接值,除此以外都是引用。Python 更徹底,一切皆對象,所有變量都是對象的引用。所以它們在賦值和傳遞時,沒有拷貝對象,只拷貝引用。如果需要拷貝對象,就需要顯式地調用拷貝函數或者克隆方法。一些 Python 教程很形象地稱這種引用爲『貼標籤』。

Go 語言的引用,不像一般意義上的引用。
其它語言的不透明引用,是一種語言級別的統一機制,是作爲指針的替代方案出現的。
Go 的引用,則是在已經有了 直接值 和 指針 的前提下,針對特定類型的優化:爲了兼顧易用性和性能,針對具體類型,在 值 和 指針 之間折中。每種引用類型,有自己獨特的機制。一般是由一個結構體負責管理元數據,結構體裏有一個指針,指向真正要使用的目標數據。
這種東西,如果在 C++ 或者 Java 裏,就是一個官方提供的類(如 Java 的 String 類),可以看到它的內部機制。而 Go 引用的實現邏輯卻內置在 runtime 裏,不僅無法直接訪問元數據,還表現得像在直接操作目標數據。你會以爲它是個普通的值,直到某些行爲跟想象中不一樣,纔想起了解它的底層結構。如果不去看 runtime 的源碼,這些元數據結構體彷彿不存在。
Go 的引用類型有:
-
字符串
string:底層的數據結構爲stringStruct,裏面有一個指針指向實際存放數據的字節數組,另外還記錄着字符串的長度。不過由於string是隻讀類型(所有看起來對string變量的修改,實際上都是生成了新的實例),在使用上常常把它當做值類型看待。由於做了特殊處理,它甚至可以作爲常量。string也是唯一零值不爲nil的引用類型。 -
切片(slice):底層數據結構爲
slice結構體 ,整體結構跟stringStruct接近,只是多了一個容量(capacity)字段。數據存放在指針指向的底層數組裏。 -
映射(map):底層數據結構爲
hmap,數據存放在數據桶(buckets)中,桶對應的數據結構爲bmap。 -
函數(func):底層數據結構爲
funcval,有一個指向真正函數的指針,指向另外的_func或者funcinl結構體(funcinl代表被行內優化之後的函數)。 -
接口(interface):底層數據結構爲
iface或eface(專門爲空接口優化的結構體),裏面持有動態值和值對應的真實類型。 -
通道(chan):底層數據結構爲
hchan,分別持有一個數據緩衝區,一個發送者隊列和一個接收者隊列。
這些類型在直接賦值拷貝的時候,都只會拷貝它們的直接值,也就是元數據結構體;間接指向的底層數據,是在各個拷貝值之間共享的。除非是發生了類型轉換這樣的特殊情況。

如果覺得不好記憶,有一個識別引用類型的快捷辦法:凡是零值是 nil 的,都是引用類型。指針作爲特殊的透明引用,一般單獨討論。而 字符串 string 因爲做了特殊處理,零值爲 "" ,需要額外記住。除了引用類型和指針,剩下的類型都是直接值類型。
那些說引用類型只有需要 make() 的切片、映射、通道 三種的說法,是錯誤的!
如果不記得都有哪些類型,零值是什麼,可以看第 3 期《類型》。或者看下圖的整理:
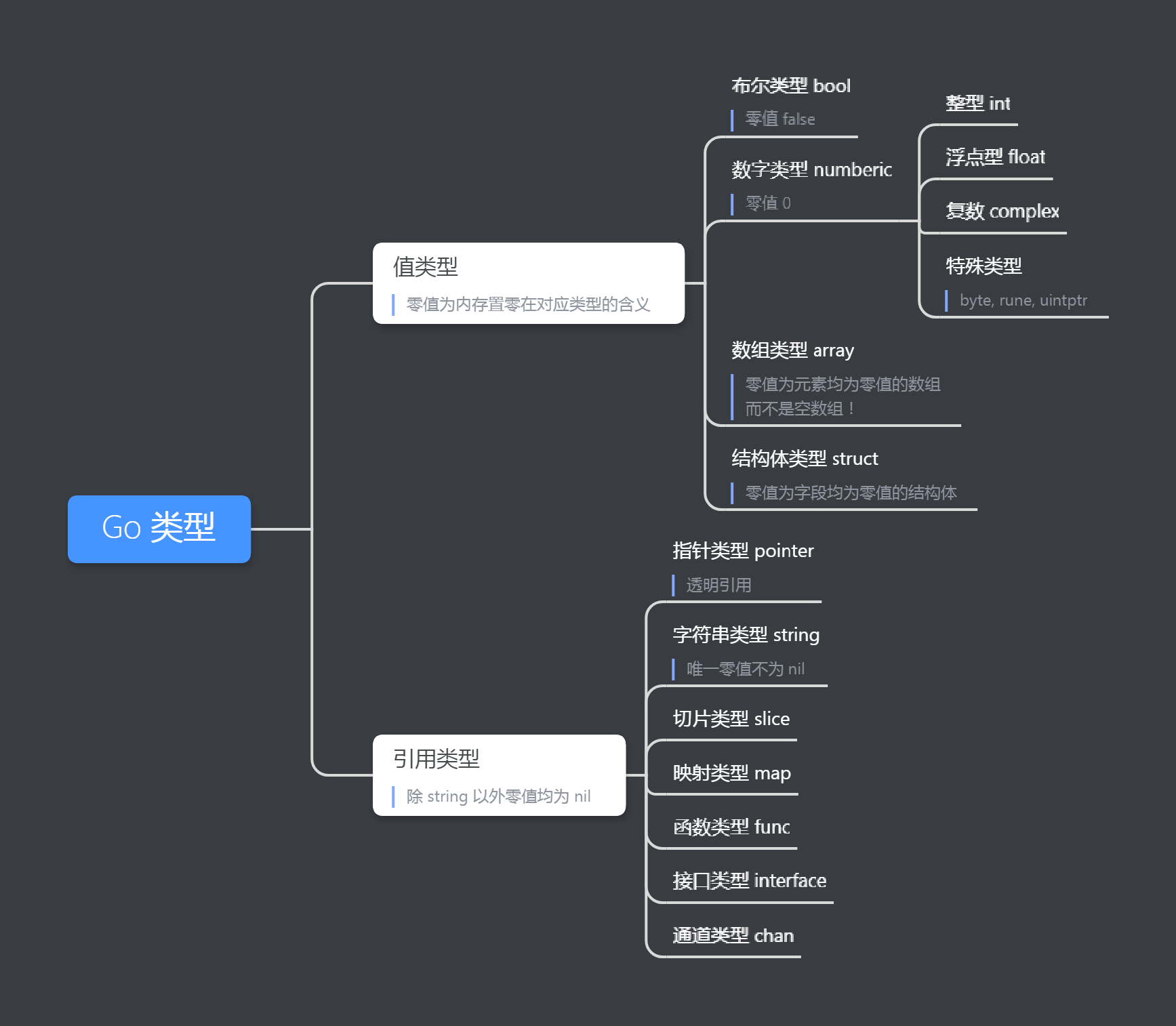
由於每一個類型的實現機制都有所不同,具體細節留到介紹這些類型時再討論,不在這裏展開。感興趣可以到 go目錄/src/runtime 下看源碼(每個類型有自己單獨的文件,如 string.go,個別沒有單獨源碼的,在 runtime2.go 裏面)。
需要注意的是,Go 通過封裝,刻意隱藏引用類型的內部細節。隱藏細節,意味着沒有對這些細節作出承諾,這些細節完全可能在後續版本中變更。實際上這樣的變更已經發生過。瞭解這些細節,是爲了更好理解類型的一些特殊行爲,而不是要依賴於這些細節。(考慮到海勒姆定律,這些細節最終還是會被一些程序依賴。)
由於『引用類型』這個術語邊界不明,特別是 Go 的實現方式跟其它語言存在差異,在表述上常常會造成混亂和誤解,go101 的作者老貘推薦在 Go 裏改爲使用『指針持有者類型』來代替。新術語是指一個類型要麼本身就是一個指針,要麼是一個包裹着指針的結構體,它的變量本身是一個直接值,這個值另外指向間接的值。當賦值或傳參發生拷貝時,只拷貝了直接值部分,間接值被多個直接值共享。
這種提法提供了新的理解角度。但我仍然使用『引用類型』這個術語,是想強調這些類型的不透明屬性。它們由 runtime 內置,其元數據和實現機制被封裝隱藏。按照『指針持有者類型』的定義,我們也可以自行實現一個包裹指針的結構體。但這種結構體跟普通結構體沒有什麼區別,runtime 不會對它做特殊處理。
指針傳遞、引用傳遞和值傳遞
因爲指針和引用本質上也是值,字面意義上,Go 裏面所有傳遞都是值傳遞。這句話正確卻沒有指導意義。
Go 裏的賦值和傳參,總是會把傳遞的值本身拷貝一份。但如果這個(直接)值指向別的(間接)值,它所指向的(間接)值不會發生遞歸拷貝。就好比把大門鑰匙多配一把交出去,而不是新建一模一樣的房子。
因爲這個特性,加上前面介紹的 直接值 、不透明引用 和 指針 的區別,這三種傳遞在使用上是有區別的。區分也很簡單,賦值和參數的類型是什麼類型,就是對應的傳遞方式。
-
(直接)值傳遞:值發生了拷貝。對新值的任何修改,都不會影響原來的值。
除非這個值是一個結構體,結構體成員字段裏有引用類型或者指針,那麼對這個字段而言,則是引用傳遞/指針傳遞。
-
引用傳遞:元數據發生了拷貝,但底層的間接值沒有拷貝,仍然共享。
-
對間接值的修改,會影響所有副本。(如,修改切片裏的某個元素,就是修改了底層數組裏的某個元素)
-
但對元數據的修改則不會影響其它副本。(如,對切片提取子切片,實際上修改了切片的訪問範圍)
-
有一種特殊的情況,就是修改元數據時改變了指向的間接值的指針,這之後對間接值的修改,都不再會影響其它副本。因爲不再共享間接值。(如,對切片追加元素時,促發了底層數組的重新分配,指向了新的底層數組)
-
-
指針傳遞:指針值(地址)發生了拷貝,共享指向的值。對間接值的修改,會影響所有副本。由於 Go 不允許對指針進行運算,不存在意外改變指針的情況。而如果是給指針賦新的值,後續的修改當然不再影響舊值指向的值。由於指針的機制透明,這點很好理解。
因爲指針本身也是一種引用,本來指針和引用可以合併討論。但由於引用屏蔽了實現細節,使得程序員不一定知道對引用的操作,作用的具體是哪一部分,也就比透明的指針多了更多的意外情況需要指出。
練習題
以下代碼有 8 個真假判斷,請在不運行的情況下,判斷 true 還是 false,並說出理由。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
func main(){
var a1 = [5]int{1, 2, 3, 4, 5}
var a2 = a1
a2[0] = 99
//fmt.Println(a1, a2)
fmt.Println("a1[0]==a2[0]? ", a1[0] == a2[0])
var sa = a1[:]
sa[1] = 88
//fmt.Println(a1, sa)
fmt.Println("a1[1]==sa[1]? ", a1[1] == sa[1])
var s1 = []int{1, 2, 3, 4, 5}
var s2 = s1
s2[0] = 99
//fmt.Println(s1, s2)
fmt.Println("s1[0]==s2[0]? ", s1[0] == s2[0])
var s3 = s2[1:4]
s3[0] = 88
//fmt.Println(s1, s3)
fmt.Println("s1[1]==s3[0]? ", s1[1] == s3[0])
var s4 = append(s2, 6)
s4[2] = 77
//fmt.Println(s1, s4)
fmt.Println("s1[2]==s4[2]? ", s1[2] == s4[2])
var oldLen int
oldLen = len(s1)
//fmt.Println(s1)
appendInt(s1, 6)
//fmt.Println(s1)
fmt.Println("len(s1)==oldLen+1?", len(s1) == oldLen+1)
oldLen = len(s1)
//fmt.Println(s1, s2)
appendIntPtr(&s2, 6)
//fmt.Println(s1, s2)
fmt.Println("len(s1)==oldLen+1?", len(s1) == oldLen+1)
oldLen = len(s1)
//fmt.Println(s1)
appendIntPtr(&s1, 6)
//fmt.Println(s1)
fmt.Println("len(s1)==oldLen+1?", len(s1) == oldLen+1)
}
func appendInt(s []int, elems ...int) {
s = append(s, elems...)
}
func appendIntPtr(ps *[]int, elems ...int) {
*ps = append(*ps, elems...)
}
|
-
滿分:無需運行代碼,全部判斷正確。
-
優秀:有個別判斷不確定,但看到運行結果可以推斷出原因。
-
及格:有比較多的判斷不確定,但在輸出數組/切片元素(註釋掉的代碼行)之後能說出原因。
-
加把勁:即使看到元素輸出,還是雲裏霧裏。
對於從頭開始學習的朋友來說,即使感覺雲裏霧裏也不要緊,因爲練習題不可避免地涉及到下一期要討論的 數組 和 切片。如果之前沒有了解,判斷不了也是正常。這道題既是這期的課後練習,也可以理解爲下期的課前預習。
答案和解析會在下期公佈。
參考資料
- Value-英文維基:https://en.wikipedia.org/wiki/Value_(computer_science)
- Reference-英文維基:https://en.wikipedia.org/wiki/Reference_(computer_science)
- Pointer-英文維基:https://en.wikipedia.org/wiki/Pointer_(computer_programming)
- 值部-Go語言101:https://gfw.go101.org/article/value-part.html
- https://jaycechant.info/2021/golang-in-action-day-9-pointer-reference-and-value/