




在經過試驗發現:網絡層數的增加可以有效的提升準確率沒錯,但如果到達一定的層數後,訓練的準確率就會下降了,因此如果網絡過深的話,會變得更加難以訓練。
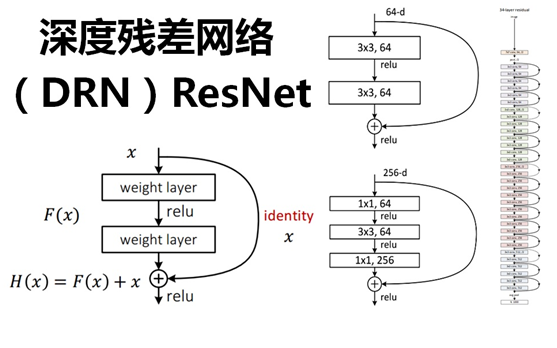
那麼我們作這樣一個假設:假設現有一個比較淺的網絡(Shallow Net)已達到了飽和的準確率,這時在它後面再加上幾個恆等映射層(Identity mapping,也即y=x,輸出等於輸入),這樣就增加了網絡的深度,並且起碼誤差不會增加,也即更深的網絡不應該帶來訓練集上誤差的上升。而這裏提到的使用恆等映射直接將前一層輸出傳到後面的思想,便是著名深度殘差網絡ResNet的靈感來源。
ResNet引入了殘差網絡結構(residual network),通過這種殘差網絡結構,可以把網絡層弄的很深(據說目前可以達到1000多層),並且最終的分類效果也非常好,殘差網絡的基本結構如下圖所示,很明顯,該圖是帶有跳躍結構的:

殘差結構
在上圖的殘差網絡結構圖中,通過“shortcut connections(捷徑連接)”的方式,直接把輸入x傳到輸出作爲初始結果,輸出結果爲H(x)=F(x)+x,當F(x)=0時,那麼H(x)=x,也就是上面所提到的恆等映射。於是,ResNet相當於將學習目標改變了,不再是學習一個完整的輸出,而是目標值H(X)和x的差值,也就是所謂的殘差F(x) := H(x)-x,因此,後面的訓練目標就是要將殘差結果逼近於0,使到隨着網絡加深,準確率不下降。
這種殘差跳躍式的結構,打破了傳統的神經網絡n-1層的輸出只能給n層作爲輸入的慣例,使某一層的輸出可以直接跨過幾層作爲後面某一層的輸入,其意義在於爲疊加多層網絡而使得整個學習模型的錯誤率不降反升的難題提供了新的方向。
至此,神經網絡的層數可以超越之前的約束,達到幾十層、上百層甚至千層,爲高級語義特徵提取和分類提供了可行性。
下圖是一個不同架構的對比,感受下:
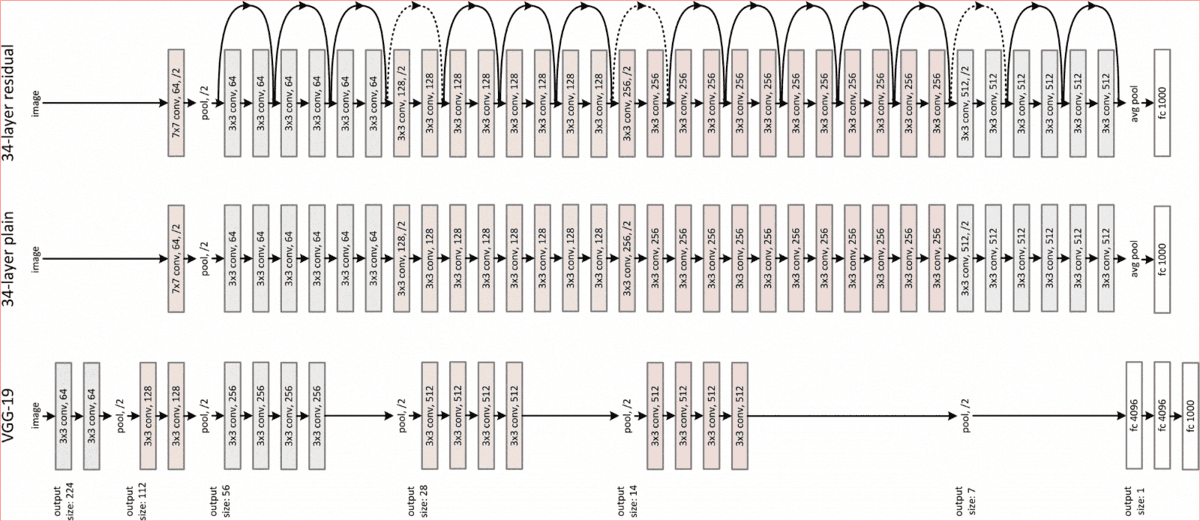
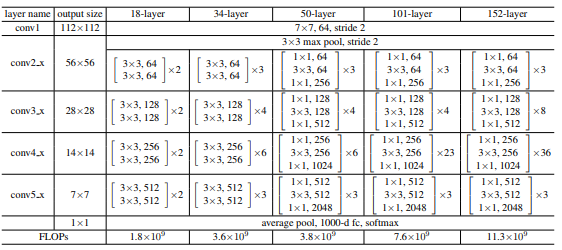
訓練結果:

全部都得到了提高,訓練時間變長。