




今天介紹將樹形結構存儲在數據庫中的第三種方法——閉包表Closure Table
繼續用上一篇的栗子,下面是要存儲的結構圖:
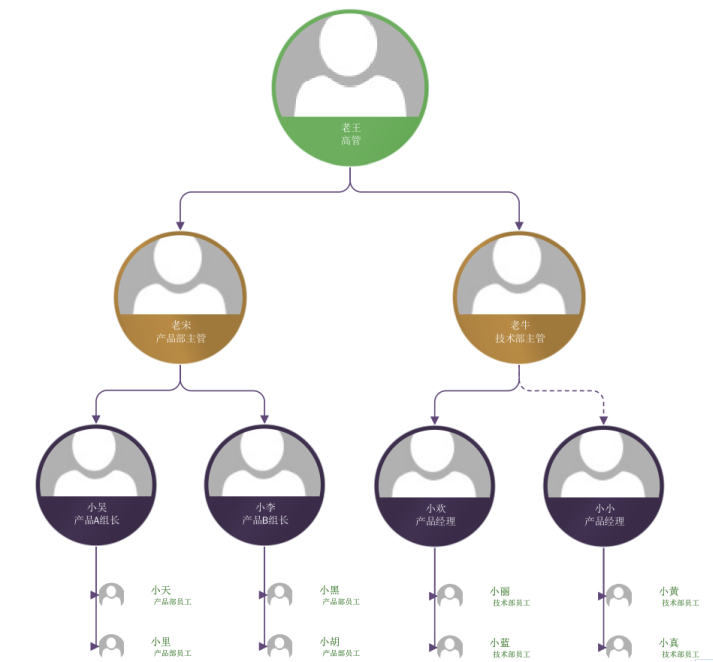
需要回答的問題依舊是這樣幾個:
1.查詢小天的直接上司。
2.查詢老宋管理下的直屬員工。
3.查詢小天的所有上司。
4.查詢老王管理的所有員工。
方案三、Closure Table 閉包表法,保存每個節點與其各個子節點的關係,也就是記錄以其爲根節點的全部子節點信息。直接上代碼就明白了:
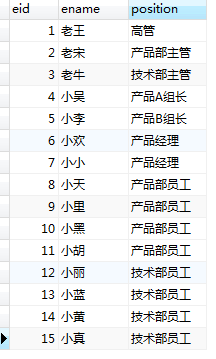
這裏要創建兩個表,一個表用來存儲信息:
CREATE TABLE employees3( eid INT, ename VARCHAR(100), position VARCHAR(100) )
一個表用來存儲關係:
CREATE TABLE emp_relations( root_id INT, depth INT, is_leaf TINYINT(1), node_id INT )
這裏的root_id用來存放以其爲根節點的路徑,node_id表示節點處的eid,depth表示根節點到該節點的深度,is_leaf表示該節點是否爲葉子節點。
接下來插入數據:
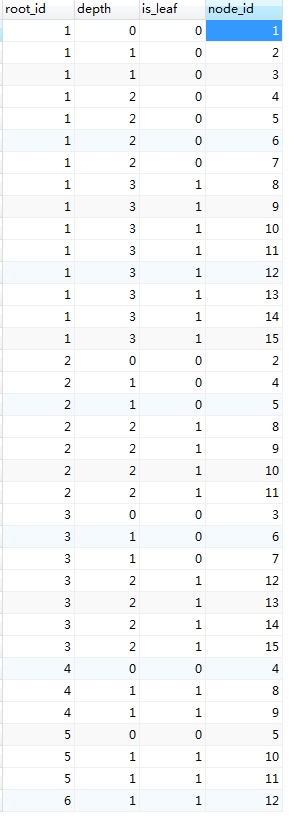
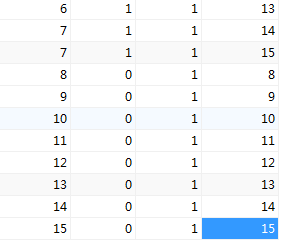
可以看出,這個關係表有點大,我們先來看看查詢效果如何:
1.查詢小天的直接上司。
這裏只需要在關係表中找到node_id爲小天id,depth爲1的根節點id即可。
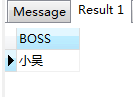
SELECT e2.ename BOSS FROM employees3 e1,employees3 e2,emp_relations rel WHERE e1.ename='小天' AND rel.node_id=e1.eid AND rel.depth=1 AND e2.eid=rel.root_id
查詢結果如下:
2.查詢老宋管理下的直屬員工。
思路差不多,只要查詢root_id爲老宋eid且深度爲1的node_id即爲其直接下屬員工id
SELECT e1.eid,e1.ename 直接下屬 FROM employees3 e1,employees3 e2,emp_relations rel WHERE e2.ename='老宋' AND rel.root_id=e2.eid AND rel.depth=1 AND e1.eid=rel.node_id
查詢結果如下:

3.查詢小天的所有上司。
只要在關係表中找到node_id爲小天eid且depth大於0的root_id即可
SELECT e2.eid,e2.ename 上司 FROM employees3 e1,employees3 e2,emp_relations rel WHERE e1.ename='小天' AND rel.node_id=e1.eid AND rel.depth>0 AND e2.eid=rel.root_id
查詢結果如下:

4.查詢老王管理的所有員工。
只要在關係表中查找root_id爲老王eid,depth大於0的node_id即可
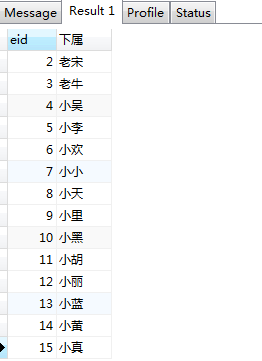
SELECT e1.eid,e1.ename 下屬 FROM employees3 e1,employees3 e2,emp_relations rel WHERE e2.ename='老王' AND rel.root_id=e2.eid AND rel.depth>0 AND e1.eid=rel.node_id
查詢結果如下:
我們可以發現,這四個查詢的複雜程度是一樣的,這就是這種存儲方式的優點,而且可以讓另一張表只存儲跟節點緊密相關的信息,看起來更簡潔。但缺點也顯而易見,關係表會很龐大,當層次很深,結構很龐大的時候,關係表數據的增長會越來越快,相當於用空間效率來換取了查找上的時間效率。
至此,樹形結構在數據庫中存儲的三種方式就介紹完了,接下來對比一下三種方法:
方案一:Adjacency List
優點:只存儲上級id,存儲數據少,結構類似於單鏈表,在查詢相鄰節點的時候很方便。添加刪除節點都比較簡單。
缺點:查詢多級結構的時候會顯得力不從心。
適用場合:對多級查詢需求不大的場景比較適用。
方案二:Path Enumeration
優點:查詢多級結構的時候比較方便。查詢相鄰節點時也比較ok。增加或者刪除節點的時候比較簡單。
缺點:需要存儲的path值可能會很大,甚至超過設置的最大值範圍,理論上無法無限擴張。
適用場合:結構相對簡單的場景比較適合。
方案三:Closure Table
優點:在查詢樹形結構的任意關係時都很方便。
缺點:需要存儲的數據量比較多,索引表需要的空間比較大,增加和刪除節點相對麻煩。
適用場合:縱向結構不是很深,增刪操作不頻繁的場景比較適用。
當然,也可以再自己創新出其他更好的存儲方案,如果有更好的想法,歡迎提出交流。
至此三種方案全部介紹完畢,歡迎大家繼續關注。