




【轉載】 基於Zookeeper的分佈式鎖與領導選舉
原創文章,轉載請務必將下面這段話置於文章開頭處。
本文轉發自技術世界,原文鏈接 http://www.jasongj.com/zookeeper/distributedlock/
Zookeeper特點
Zookeeper節點類型
如上文《Zookeeper架構及FastLeaderElection機制》所述,Zookeeper 提供了一個類似於 Linux 文件系統的樹形結構。該樹形結構中每個節點被稱爲 znode ,可按如下兩個維度分類
- Persist vs. Ephemeral
- *Persist*節點,一旦被創建,便不會意外丟失,即使服務器全部重啓也依然存在。每個 Persist 節點即可包含數據,也可包含子節點
- *Ephemeral*節點,在創建它的客戶端與服務器間的 Session 結束時自動被刪除。服務器重啓會導致 Session 結束,因此 Ephemeral 類型的 znode 此時也會自動刪除
- Sequence vs. Non-sequence
- *Non-sequence*節點,多個客戶端同時創建同一 Non-sequence 節點時,只有一個可創建成功,其它勻失敗。並且創建出的節點名稱與創建時指定的節點名完全一樣
- *Sequence*節點,創建出的節點名在指定的名稱之後帶有10位10進制數的序號。多個客戶端創建同一名稱的節點時,都能創建成功,只是序號不同
Zookeeper語義保證
Zookeeper 簡單高效,同時提供如下語義保證,從而使得我們可以利用這些特性提供複雜的服務。
- *順序性* 客戶端發起的更新會按發送順序被應用到 Zookeeper 上
- *原子性* 更新操作要麼成功要麼失敗,不會出現中間狀態
- 單一系統鏡像* 一個客戶端無論連接到哪一個服務器都能看到完全一樣的系統鏡像(即完全一樣的樹形結構)。注:*根據上文《Zookeeper架構及FastLeaderElection機制》介紹的 ZAB 協議,寫操作並不保證更新被所有的 Follower 立即確認,因此通過部分 Follower 讀取數據並不能保證讀到最新的數據,而部分 Follwer 及 Leader 可讀到最新數據。如果一定要保證*單一系統鏡像*,可在讀操作前使用 sync 方法。
- *可靠性* 一個更新操作一旦被接受即不會意外丟失,除非被其它更新操作覆蓋
- *最終一致性* 寫操作最終(而非立即)會對客戶端可見
Zookeeper Watch機制
所有對 Zookeeper 的讀操作,都可附帶一個 Watch 。一旦相應的數據有變化,該 Watch 即被觸發。Watch 有如下特點
- *主動推送* Watch被觸發時,由 Zookeeper 服務器主動將更新推送給客戶端,而不需要客戶端輪詢。
- *一次性* 數據變化時,Watch 只會被觸發一次。如果客戶端想得到後續更新的通知,必須要在 Watch 被觸發後重新註冊一個 Watch。
- *可見性* 如果一個客戶端在讀請求中附帶 Watch,Watch 被觸發的同時再次讀取數據,客戶端在得到 Watch 消息之前肯定不可能看到更新後的數據。換句話說,更新通知先於更新結果。
- *順序性* 如果多個更新觸發了多個 Watch ,那 Watch 被觸發的順序與更新順序一致。
分佈式鎖與領導選舉關鍵點
最多一個獲取鎖 / 成爲Leader
對於分佈式鎖(這裏特指排它鎖)而言,任意時刻,最多隻有一個進程(對於單進程內的鎖而言是單線程)可以獲得鎖。
對於領導選舉而言,任意時間,最多隻有一個成功當選爲Leader。否則即出現腦裂(Split brain)
鎖重入 / 確認自己是Leader
對於分佈式鎖,需要保證獲得鎖的進程在釋放鎖之前可再次獲得鎖,即鎖的可重入性。
對於領導選舉,Leader需要能夠確認自己已經獲得領導權,即確認自己是Leader。
釋放鎖 / 放棄領導權
鎖的獲得者應該能夠正確釋放已經獲得的鎖,並且當獲得鎖的進程宕機時,鎖應該自動釋放,從而使得其它競爭方可以獲得該鎖,從而避免出現死鎖的狀態。
領導應該可以主動放棄領導權,並且當領導所在進程宕機時,領導權應該自動釋放,從而使得其它參與者可重新競爭領導而避免進入無主狀態。
感知鎖釋放 / 領導權的放棄
當獲得鎖的一方釋放鎖時,其它對於鎖的競爭方需要能夠感知到鎖的釋放,並再次嘗試獲取鎖。
原來的Leader放棄領導權時,其它參與方應該能夠感知該事件,並重新發起選舉流程。
非公平領導選舉
從上面幾個方面可見,分佈式鎖與領導選舉的技術要點非常相似,實際上其實現機制也相近。本章就以領導選舉爲例來說明二者的實現原理,分佈式鎖的實現原理也幾乎一致。
選主過程
假設有三個Zookeeper的客戶端,如下圖所示,同時競爭Leader。這三個客戶端同時向Zookeeper集羣註冊Ephemeral*且Non-sequence*類型的節點,路徑都爲/zkroot/leader(工程實踐中,路徑名可自定義)。
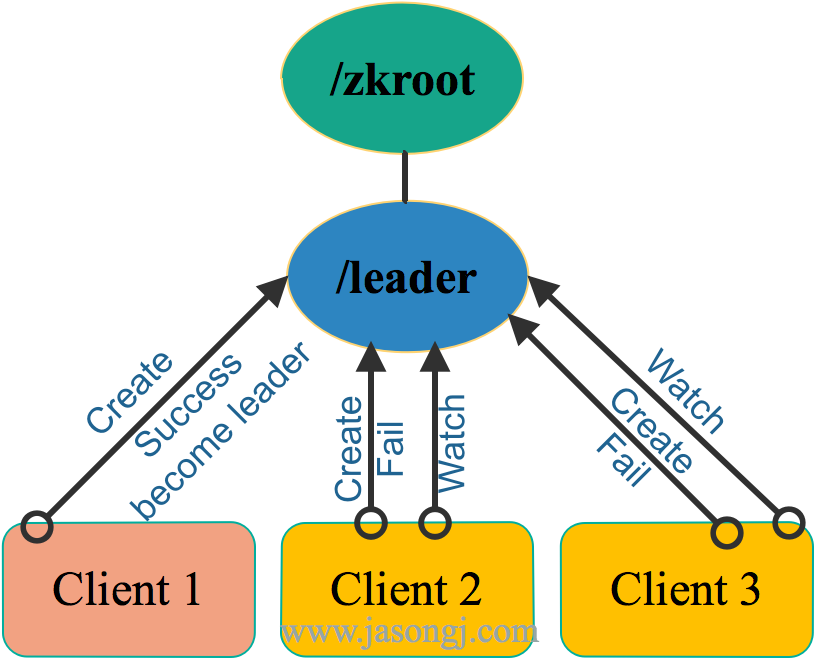
如上圖所示,由於是*Non-sequence*節點,這三個客戶端只會有一個創建成功,其它節點均創建失敗。此時,創建成功的客戶端(即上圖中的Client 1)即成功競選爲 Leader 。其它客戶端(即上圖中的Client 2和Client 3)此時勻爲 Follower。
放棄領導權
如果 Leader 打算主動放棄領導權,直接刪除/zkroot/leader節點即可。
如果 Leader 進程意外宕機,其與 Zookeeper 間的 Session 也結束,該節點由於是*Ephemeral*類型的節點,因此也會自動被刪除。
此時/zkroot/leader節點不復存在,對於其它參與競選的客戶端而言,之前的 Leader 已經放棄了領導權。
感知領導權的放棄
由上圖可見,創建節點失敗的節點,除了成爲 Follower 以外,還會向/zkroot/leader註冊一個 Watch ,一旦 Leader 放棄領導權,也即該節點被刪除,所有的 Follower 會收到通知。
重新選舉
感知到舊 Leader 放棄領導權後,所有的 Follower 可以再次發起新一輪的領導選舉,如下圖所示。
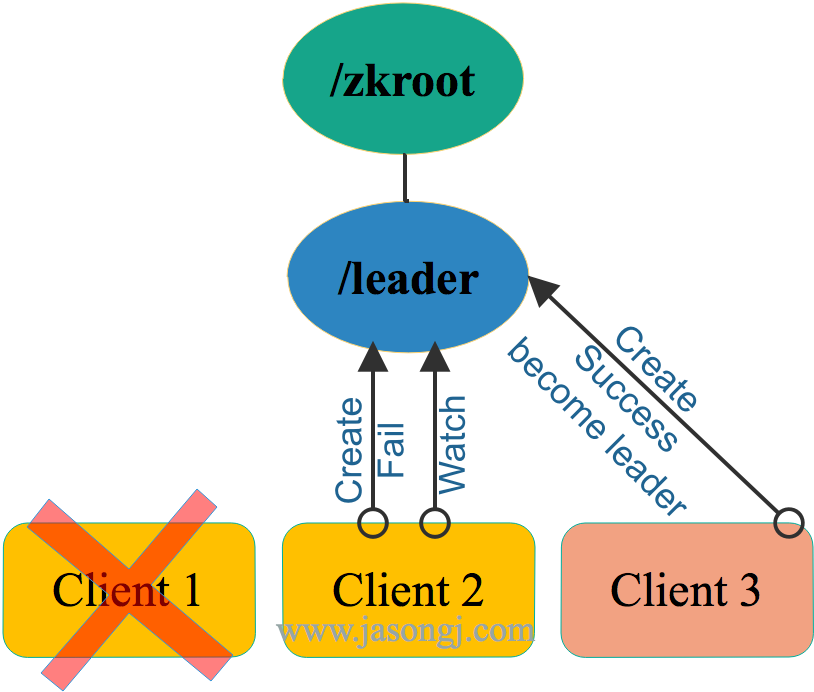
從上圖中可見
- 新一輪的領導選舉方法與最初的領導選舉方法完全一樣,都是發起節點創建請求,創建成功即爲 Leader,否則爲 Follower ,且 Follower 會 Watch 該節點
- 新一輪的選舉結果,無法預測,與它們在第一輪選舉中的順序無關。這也是該方案被稱爲
非公平模式的原因
非公平模式總結
- 非公平模式實現簡單,每一輪選舉方法都完全一樣
- 競爭參與方不多的情況下,效率高。每個 Follower 通過 Watch 感知到節點被刪除的時間不完全一樣,只要有一個 Follower 得到通知即發起競選,即可保證當時有新的 Leader 被選出
- 給Zookeeper 集羣造成的負載大,因此擴展性差。如果有上萬個客戶端都參與競選,意味着同時會有上萬個寫請求發送給 Zookeper。如《Zookeeper架構》一文所述,Zookeeper 存在單點寫的問題,寫性能不高。同時一旦 Leader 放棄領導權,Zookeeper 需要同時通知上萬個 Follower,負載較大。
公平領導選舉
選主過程
如下圖所示,公平領導選舉中,各客戶端均創建/zkroot/leader節點,且其類型爲Ephemeral*與Sequence*。
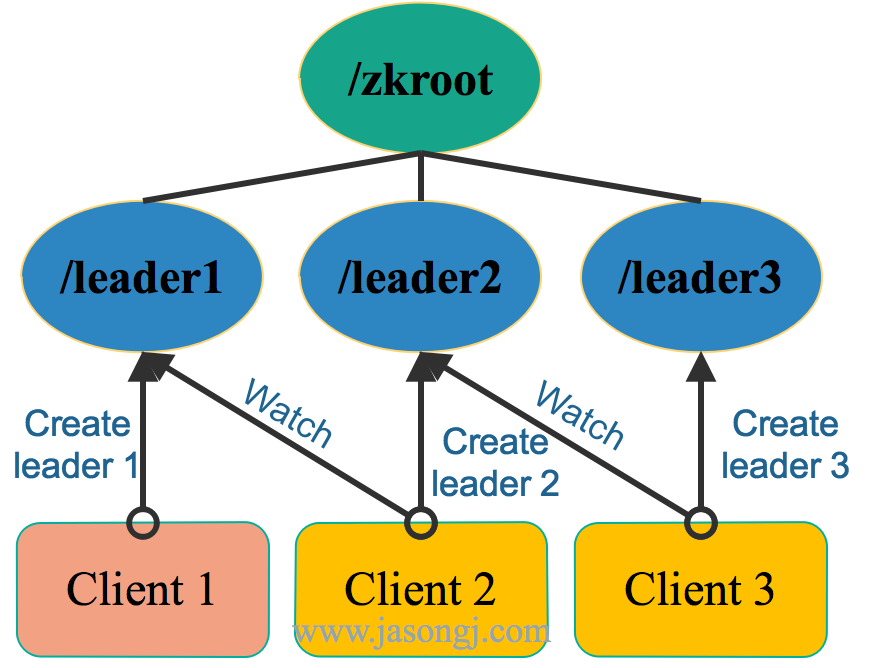
由於是*Sequence*類型節點,故上圖中三個客戶端均創建成功,只是序號不一樣。此時,每個客戶端都會判斷自己創建成功的節點的序號是不是當前最小的。如果是,則該客戶端爲 Leader,否則即爲 Follower。
在上圖中,Client 1創建的節點序號爲 1 ,Client 2創建的節點序號爲 2,Client 3創建的節點序號爲3。由於最小序號爲 1 ,且該節點由Client 1創建,故Client 1爲 Leader 。
放棄領導權
Leader 如果主動放棄領導權,直接刪除其創建的節點即可。
如果 Leader 所在進程意外宕機,其與 Zookeeper 間的 Session 結束,由於其創建的節點爲*Ephemeral*類型,故該節點自動被刪除。
感知領導權的放棄
與非公平模式不同,每個 Follower 並非都 Watch 由 Leader 創建出來的節點,而是 Watch 序號剛好比自己序號小的節點。
在上圖中,總共有 1、2、3 共三個節點,因此Client 2 Watch /zkroot/leader1,Client 3 Watch /zkroot/leader2。(注:序號應該是10位數字,而非一位數字,這裏爲了方便,以一位數字代替)
一旦 Leader 宕機,/zkroot/leader1被刪除,Client 2可得到通知。此時Client 3由於 Watch 的是/zkroot/leader2,故不會得到通知。
重新選舉
Client 2得到/zkroot/leader1被刪除的通知後,不會立即成爲新的 Leader 。而是先判斷自己的序號 2 是不是當前最小的序號。在該場景下,其序號確爲最小。因此Client 2成爲新的 Leader 。

這裏要注意,如果在Client 1放棄領導權之前,Client 2就宕機了,Client 3會收到通知。此時Client 3不會立即成爲Leader,而是要先判斷自己的序號 3 是否爲當前最小序號。很顯然,由於Client 1創建的/zkroot/leader1還在,因此Client 3不會成爲新的 Leader ,並向Client 2序號 2 前面的序號,也即 1 創建 Watch。該過程如下圖所示。

公平模式總結
- 實現相對複雜
- 擴展性好,每個客戶端都只 Watch 一個節點且每次節點被刪除只須通知一個客戶端
- 舊 Leader 放棄領導權時,其它客戶端根據競選的先後順序(也即節點序號)成爲新 Leader,這也是
公平模式的由來 - 延遲相對非公平模式要高,因爲它必須等待特定節點得到通知才能選出新的 Leader
總結
基於 Zookeeper 的領導選舉或者分佈式鎖的實現均基於 Zookeeper 節點的特性及通知機制。充分利用這些特性,還可以開發出適用於其它場景的分佈式應用。