




https://www.jiqizhixin.com/articles/2016-11-21-4
batch批訓練—不同的更新梯度的方式
batch梯度下降分爲三種:batch梯度下降、隨機化batch梯度下降、mini-batch梯度下降
1.batch
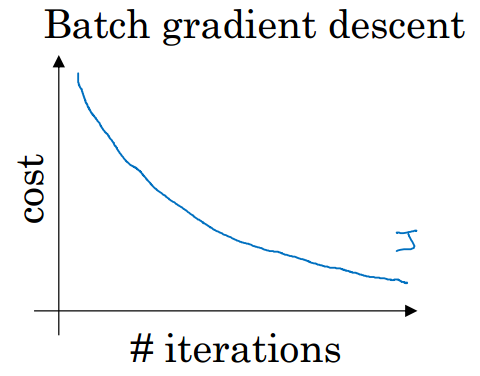
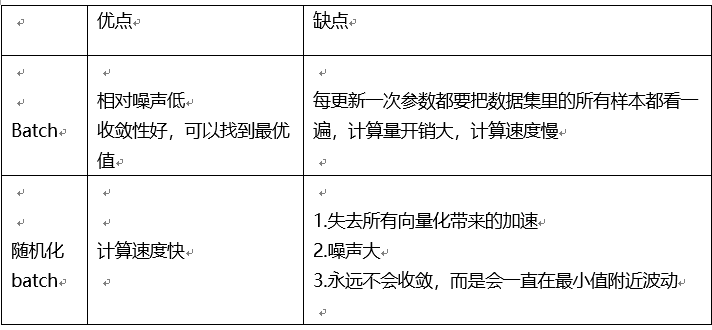
遍歷全部數據集算一次損失函數,然後算函數對各個參數的梯度,更新梯度。這種方法每更新一次參數都要把數據集裏的所有樣本都看一遍
每次迭代,成本函數都會減小
2.隨機化batch
每一個數據都計算一次損失函數,然後求梯度更新參數
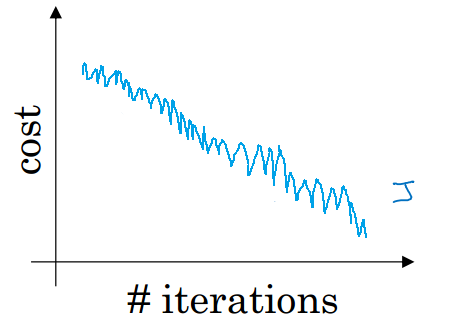
每次只對一個樣本進行訓練,cost不是單調下降,而是受類似噪聲的影響,出現振盪。但整體的趨勢是下降的,最終也能得到較低的cost值。

成本函數輪廓圖
隨機梯度下降法永遠不會收斂,而是會一直在最小值附近波動
3.mini-batch梯度下降
把m個訓練樣本分成若干個子集,稱爲mini-batches,然後每次在單一子集上進行神經網絡訓練。這樣,一個批中的一組數據共同決定了本次梯度的方向,下降起來就不容易跑偏,減少了隨機性。另一方面因爲一批的樣本數與整個數據集相比小了很多,計算量也不是很大
假如有50萬個訓練集,每個mini-batch包括1000個樣本,總共500個mini-batches。使用 batch 梯度下降法,一個mini-batch只做一次梯度下降。則只需要進行500次梯度下降即可。

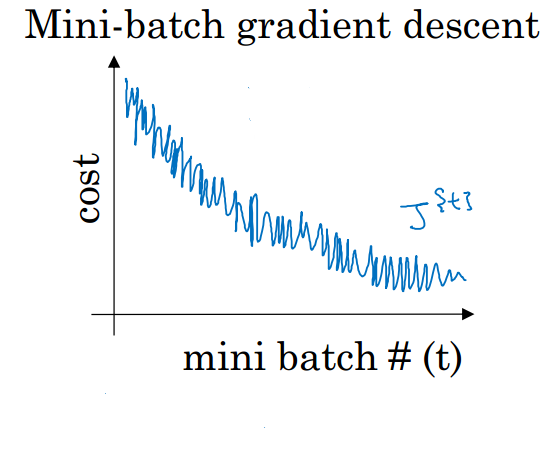
1.噪聲
2.代價函數並不是單調較小的,不能精準收斂到最小值,只是在最小值附近波動。
mini-batch梯度下降優化-Learning rate decay
隨時間慢慢減少學習率,我們將之稱爲學習率衰減。
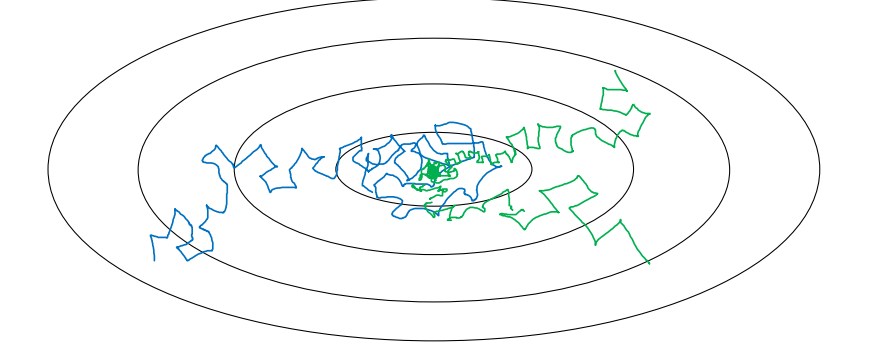
上圖中,藍色折線表示使用恆定的學習率 ,由於每次訓練 學習率相同,步進長度不變,在接近最小值處的振盪也大,在最小值附近較大範圍內振盪,與最小值距離就比較遠。
綠色折線表示使用不斷減小的 學習率,隨着訓練次數增加, 學習率逐漸減小,步進長度減小,使得能夠在最小值處較小範圍內微弱振盪,不斷逼近最小值。相比較恆定的 學習率來說,learning rate decay更接近最小值。
常用的公式有:
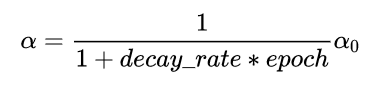
其中,decay_rate是參數(可調),epoch是已訓練樣本集的次數。隨着epoch增加, 學習率會不斷變小。
總結:
1.如果訓練集較小(小於 2000 個樣本),直接使用 batch 梯度下降法
2.一般的 mini-batch 大小爲 64 到 512,而且如果 mini-batch 大小是 2 的n次方,代碼運行會快些
(因爲計算機存儲數據一般是2的冪,這樣設置可以提高運算速度)