




Gradient Checking(梯度檢驗)
我們有時候實現完backward propagation,我們不知道自己實現的backward propagation到底是不是完全正確的(這篇博客只面向自己手擼的網絡,直接搬磚的不需要考慮這個問題…..),因此,通常要用梯度檢驗來檢查自己實現的bp是否正確。其實所謂梯度檢驗,就是自己實現下導數的定義,去求w和b的導數(梯度),然後去和bp求到的梯度比較,如果差值在很小的範圍內,則可以認爲我們實現的bp沒問題。
先來回顧下,導數的定義:
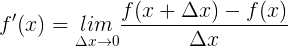
具體應用到神經網絡的梯度檢驗中,因爲我們沒法做到 ,只能取一個比較小的數,所以爲了結果更精確,我們可以把上面的公式稍微變下形:
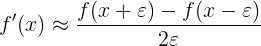
通常設置 即可。
具體到神經網絡中,我們做梯度檢驗的步驟通常爲:
- 把 轉化成向量 。
- 同樣把 轉化成向量 。
- 接下來是實現導數定義:
- 接下來我們比較 與 是否大致相等,主要是計算兩個向量之間的歐式距離:
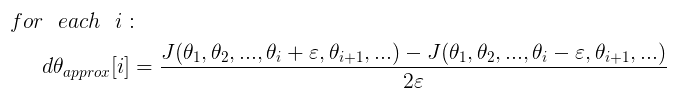
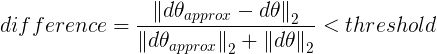
通常設置閾值 。 如果difference小於閾值,則認爲實現的bp沒問題。
關於上面的步驟,我們來看看代碼實現,
1.把 轉化成向量 。
#convert parameter into vector
def dictionary_to_vector(parameters):
"""
Roll all our parameters dictionary into a single vector satisfying our specific required shape.
"""
count = 0
for key in parameters:
# flatten parameter
new_vector = np.reshape(parameters[key], (-1, 1))#convert matrix into vector
if count == 0:#剛開始時新建一個向量
theta = new_vector
else:
theta = np.concatenate((theta, new_vector), axis=0)#和已有的向量合併成新向量
count = count + 1
return theta2.把 轉化成向量 。
注:這個地方一定要注意bp求得的gradients字典的存儲順序是{dWL,dbL,….dW2,db2,dW1,db1},因爲後面要求歐式距離,所以一定要把順序轉化爲[dW1,db1,…dWL,dbL]。在這個地方踩過坑,花了很長時間才找出bug。
#convert gradients into vector
def gradients_to_vector(gradients):
"""
Roll all our parameters dictionary into a single vector satisfying our specific required shape.
"""
# 因爲gradient的存儲順序是{dWL,dbL,....dW2,db2,dW1,db1},
#爲了統一採用[dW1,db1,...dWL,dbL]方面後面求歐式距離(對應元素)
L = len(gradients) // 2
keys = []
for l in range(L):
keys.append("dW" + str(l + 1))
keys.append("db" + str(l + 1))
count = 0
for key in keys:
# flatten parameter
new_vector = np.reshape(gradients[key], (-1, 1))#convert matrix into vector
if count == 0:#剛開始時新建一個向量
theta = new_vector
else:
theta = np.concatenate((theta, new_vector), axis=0)#和已有的向量合併成新向量
count = count + 1
return theta第三步、第四步的代碼如下:
def gradient_check(parameters, gradients, X, Y, layer_dims, epsilon=1e-7):
"""
Checks if backward_propagation_n computes correctly the gradient of the cost output by forward_propagation_n
Arguments:
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
grad -- output of backward_propagation_n, contains gradients of the cost with respect to the parameters.
x -- input datapoint, of shape (input size, 1)
y -- true "label"
epsilon -- tiny shift to the input to compute approximated gradient with formula(1)
layer_dims -- the layer dimension of nn
Returns:
difference -- difference (2) between the approximated gradient and the backward propagation gradient
"""
parameters_vector = dictionary_to_vector(parameters) # parameters_values
grad = gradients_to_vector(gradients)
num_parameters = parameters_vector.shape[0]
J_plus = np.zeros((num_parameters, 1))
J_minus = np.zeros((num_parameters, 1))
gradapprox = np.zeros((num_parameters, 1))
# Compute gradapprox
for i in range(num_parameters):
thetaplus = np.copy(parameters_vector)
thetaplus[i] = thetaplus[i] + epsilon
AL, _ = forward_propagation(X, vector_to_dictionary(thetaplus,layer_dims))
J_plus[i] = compute_cost(AL,Y)
thetaminus = np.copy(parameters_vector)
thetaminus[i] = thetaminus[i] - epsilon
AL, _ = forward_propagation(X, vector_to_dictionary(thetaminus, layer_dims))
J_minus[i] = compute_cost(AL,Y)
gradapprox[i] = (J_plus[i] - J_minus[i]) / (2 * epsilon)
numerator = np.linalg.norm(grad - gradapprox)
denominator = np.linalg.norm(grad) + np.linalg.norm(gradapprox)
difference = numerator / denominator
if difference > 2e-7:
print(
"\033[93m" + "There is a mistake in the backward propagation! difference = " + str(difference) + "\033[0m")
else:
print(
"\033[92m" + "Your backward propagation works perfectly fine! difference = " + str(difference) + "\033[0m")
return difference這裏在每一次計算bp時,還要把向量轉化成矩陣,具體實現如下:
#convert vector into dictionary
def vector_to_dictionary(theta, layer_dims):
"""
Unroll all our parameters dictionary from a single vector satisfying our specific required shape.
"""
parameters = {}
L = len(layer_dims) # the number of layers in the network
start = 0
end = 0
for l in range(1, L):
end += layer_dims[l]*layer_dims[l-1]
parameters["W" + str(l)] = theta[start:end].reshape((layer_dims[l],layer_dims[l-1]))
start = end
end += layer_dims[l]*1
parameters["b" + str(l)] = theta[start:end].reshape((layer_dims[l],1))
start = end
return parameters
還是拿sklearn中自帶的breast_cancer數據集,來測試下,自己實現的bp到底對不對,順便也是測下我們的gradient checking的代碼對不對,測試結果如下:
Your backward propagation works perfectly fine! difference = 5.649104934345307e-11
可以看到我們實現的bp求到的梯度和用導數定義實現的梯度之間的差距是 這個數量級,所以我們實現的bp正確無誤。
完整的代碼已放到github上:gradient_checking.py
cs231n中也有講解關於gradient cheking的資料,不過它的 定義和ng講的有些細微的差別,不過不是什麼大問題,只是定義不一樣而已,只要改變相應的閾值即可。具體見:CS231n Convolutional Neural Networks for Visual Recognition
參考資料
- ng Coursera 《Improving Deep Neural Networks Hyperparameter tuning, Regularization and Optimization》課