




VI. Logistic Regression (Week 3)
- Classification
在分類問題中,我們所嘗試預測的是結果是否屬於某一類(例如正確或錯誤)。分類問題的例子有:判斷一封電子郵件是否是垃圾郵件;判斷一封電子郵件是否是垃圾郵件;判斷一次金融交易是否是欺詐等等。
我們從二元的分類問題開始討論。
我們將因變量(dependent variable)可能屬於的兩個類分別稱爲負向類(negative class)和正向類(positive class),則因變量

- Hypothesis representation
下面,我們回顧一開始提到的乳腺癌分類問題,我們可以用線性迴歸的方法求出適合數據的一條直線。
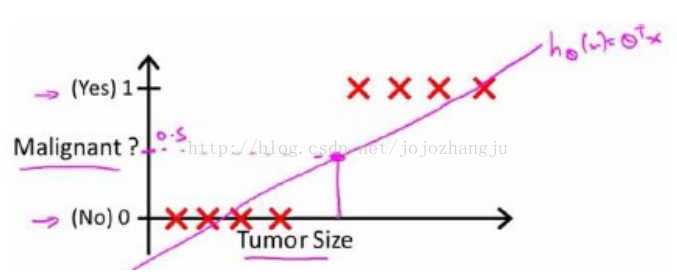
根據線性迴歸模型我們只能預測連續的值,然而對於分類問題,我們需要輸出0或1,我們可以預測:

對於上圖所示的數據,這樣的一個線性模型似乎能很好地完成分類任務。然而,假設我們又觀測到一個非常大尺寸的惡性腫瘤,將其作爲實例加入到我們的訓練集中來,這將使得我們獲得一條新的直線。
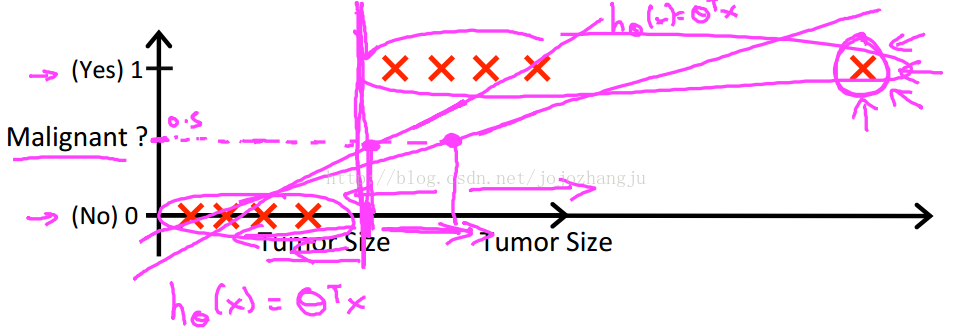
此時,再使用0.5作爲閾值來預測腫瘤是良性還是惡性便不合適了。可以看出,線性迴歸模型,因爲其預測的值可以超越[0,1]的範圍,並不適合解決這樣的問題。
於是,我們引入一個新的模型,邏輯迴歸,該模型的輸出變量範圍始終在0和1之間。

其中,
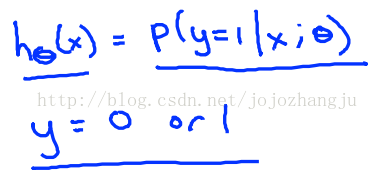
例如,如果對於給定的x,通過已經確定的參數計算得出
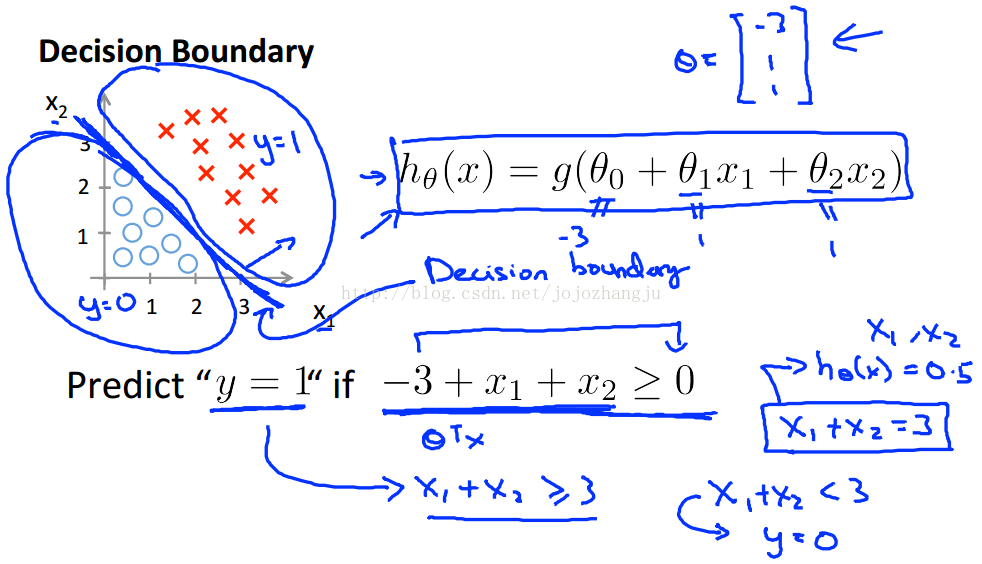
- Decision boundary
在邏輯迴歸中,我們預測:

根據之前繪製出的S形函數圖像,我們知道當:

又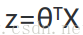

舉個例子,假設我們有一個模型: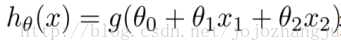
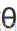
則當大於等於0,即
大於等於3時,模型將預測y = 1。
我們可以繪製直線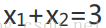
假使我們的數據呈現如下情況,究竟需要怎樣的模型才合適呢?
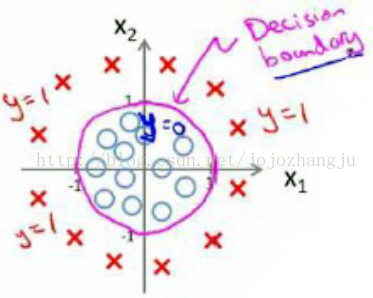
因爲需要用曲線才能分隔開y = 0的區域和y = 1的區域,我們需要二次方特徵:

假設參數是[-1 0 0 1 1],則我們得到的判定邊界恰好是圓點在原點且半徑爲1的圓形。
我們可以用非常複雜的模型來適應非常複雜形狀的判定邊界。