




僞分佈模式主要涉及一下的配置信息:
-
修改Hadoop的核心配置文件core-site.xml,主要是配置HDFS的地址和端口號;
-
修改Hadoop中HDFS的配置文件hdfs-site.xml,主要是配置replication;
-
修改Hadoop的MapReduce的配置文件mapred-site.xml,主要是配置JobTracker的地址和端口;
在具體操作前我們先在Hadoop目錄下創建幾個文件夾:
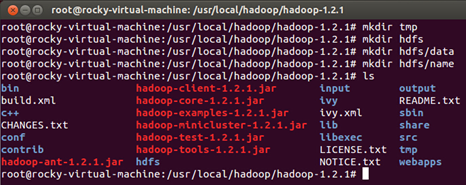
下面開始構建具體的僞分佈式的過程並進行測試:
首先配置core-site.xml文件:

進入core-site.xml文件:

配置後文件的內容如下所示:

使用“:wq”命令保存並退出。
接下來配置hdfs-site.xml,打開文件:

打開後的文件:

配置後的文件:
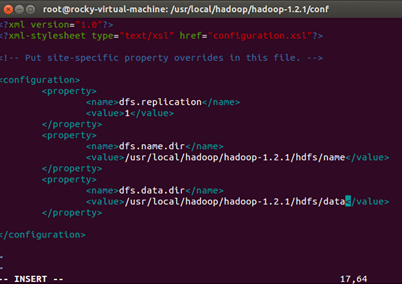
輸入“:wq”保存修改信息並退出。
接下來修改mapred-site.xml配置文件:

進入配置文件:

修改後的mapred-site.xml配置文件的內容爲:
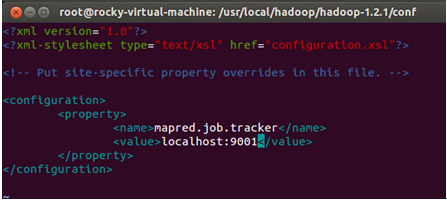
使用“:wq”命令保存並退出。
通過上面的配置,我們完成了最簡單的僞分佈式配置。
接下來進行hadoop的namenode格式化:

輸入“Y”,完成格式化過程:

接下來啓動Hadoop!
啓動Hadoop,如下所示:

使用java自帶的jps命令查詢出所有的守護進程:
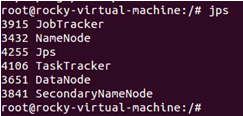
啓動Hadoop!!!
接下來使用Hadoop中用於監控集羣狀態的Web頁面查看Hadoop的運行狀況,具體的頁面如下:
http://localhost:50030/jobtracker.jsp
http://localhost:50060/tasttracker.jsp
http://localhost:50070/dfshealth.jsp
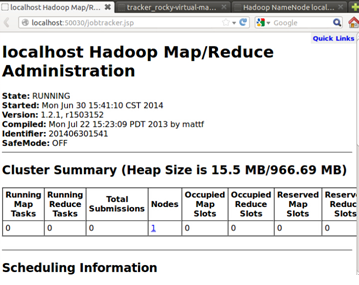


上述Hadoop運行狀態監控頁面表明我們的僞分佈式開發環境完全搭建成功!
接下來我們使用新建的僞分佈式平臺運行wordcount程序:
首先在dfs中創建input目錄:

此時創建的文件因爲沒有指定hdfs具體的目錄,所以會在當前用戶“rocky”下創建“input”目錄,查看Web控制檯:

執行文件拷貝操作
執行文件拷貝操作

拷貝後的“input”文件夾的內容如下所示:

和我們的hadoop安裝目錄下的“conf”文件的內容是一樣的。
現在,在我們剛剛構建的僞分佈式模式下運行wordcount程序:
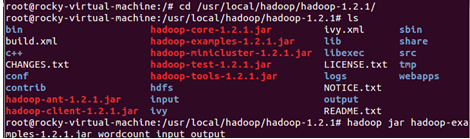
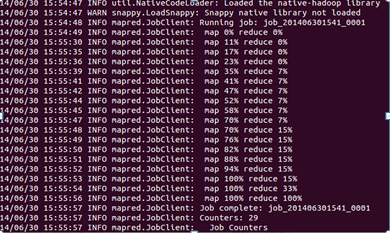
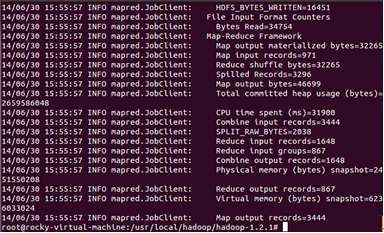
運行完成後我們查看一下輸出的結果:

部分統計結果如下:

此時我們到達Hadoop的web控制檯會發現我們提交併成功的運行了任務:
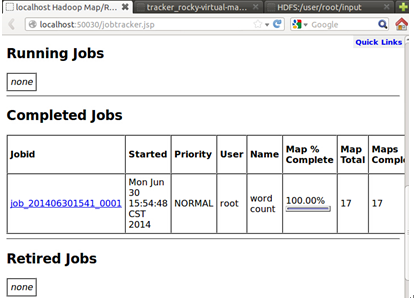
最後在Hadoop執行完任務後,可以關閉Hadoop後臺服務:

至此,Hadoop僞分佈式環境的搭建和測試你完全成功!
至此,我們徹底完成了實驗。