




第一步:Spark集羣需要的軟件;
在1、2講的從零起步構建好的Hadoop集羣的基礎上構建Spark集羣,我們這裏採用2014年5月30日發佈的Spark 1.0.0版本,也就是Spark的最新版本,要想基於Spark 1.0.0構建Spark集羣,需要的軟件如下:
1.Spark 1.0.0,筆者這裏使用的是spark-1.0.0-bin-hadoop1.tgz, 具體的下載地址是http://d3kbcqa49mib13.cloudfront.net/spark-1.0.0-bin-hadoop1.tgz
如下圖所示:
筆者是保存在了Master節點如下圖所示的位置:
2.下載和Spark 1.0.0對應的Scala版本,官方要求的是Scala必須爲Scala 2.10.x:
筆者下載的是“Scala 2.10.4”,具體官方下載地址爲http://www.scala-lang.org/download/2.10.4.html 下載後在Master節點上保存爲:
第二步:安裝每個軟件
安裝Scala
-
打開終端,建立新目錄“/usr/lib/scala”,如下圖所示:
2.解壓Scala文件,如下圖所示:

把解壓好的Scala移到剛剛創建的“/usr/lib/scala”中,如下圖所示

3.修改環境變量:

進入如下圖所示的配置文件中:

按下“i”進入INSERT模式,把Scala的環境編寫信息加入其中,如下圖所示:

從配置文件中可以看出,我們設置了“SCALA_HOME”並把Scala的bin目錄設置到了PATH中。
按下“esc“鍵回到正常模式,保存並退出配置文件:
執行以下命令是配置文件的修改生效:

4.在終端中顯示剛剛安裝的Scala版本,如下圖所示

發現版本是”2.10.4”,這正是我們期望的。
當我們輸入“scala”這個命令的的時候,可以直接進入Scala的命令行交互界面:

此時我們輸入“9*9”這個表達式:
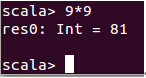
此時我們發現Scala正確的幫我們計算出了結果 。
此時我們完成了Master上Scala的安裝;
由於我們的 Spark要運行在Master、Slave1、Slave2三臺機器上,此時我們需要在Slave1和Slave2上安裝同樣的Scala,使用scp命令把Scala安裝目錄和“~/.bashrc”都複製到Slave1和Slave2相同的目錄之之下,當然,你也可以按照Master節點的方式手動在Slave1和Slave2上安裝。
在Slave1上Scala安裝好後的測試效果如下:
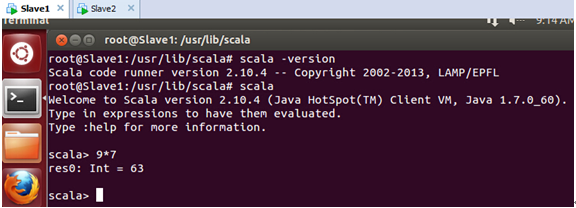
在Slave2上Scala安裝好後的測試效果如下:

至此,我們在Master、Slave1、Slave2這三臺機器上成功部署Scala。
安裝Spark
Master、Slave1、Slave2這三臺機器上均需要安裝Spark。
首先在Master上安裝Spark,具體步驟如下:
第一步:把Master上的Spark解壓:
我們直接解壓到當前目錄下:

此時,我們創建Spark的目錄“/usr/local/spark”:

把解壓後的“spark-1.0.0-bin-hadoop1”複製到/usr/local/spark”下面:

第二步:配置環境變量
進入配置文件:

在配置文件中加入“SPARK_HOME”並把spark的bin目錄加到PATH中:

配置後保存退出,然後使配置生效:

第三步:配置Spark
進入Spark的conf目錄:

在配置文件中加入“SPARK_HOME”並把spark的bin目錄加到PATH中:
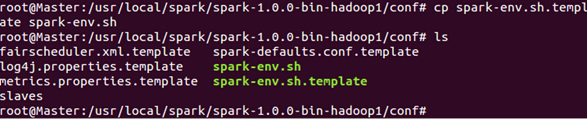
把spark-env.sh.template 拷貝到spark-env.sh:

在配置文件中添加如下配置信息:

其中:
JAVA_HOME:指定的是Java的安裝目錄;
SCALA_HOME:指定的是Scala的安裝目錄;
SPARK_MASTER_IP:指定的是Spark集羣的Master節點的IP地址;
SPARK_WORKER_MEMOERY:指定的Worker節點能夠最大分配給Excutors的內存大小,因爲我們的三臺機器配置都是2g,爲了最充分的使用內存,這裏設置爲了2g;
HADOOP_CONF_DIR:指定的是我們原來的Hadoop集羣的配置文件的目錄;
保存退出。
接下來配置Spark的conf下的slaves文件,把Worker節點都添加進去:

打開後文件的內容:

我們需要把內容修改爲:

可以看出我們把三臺機器都設置爲了Worker節點,也就是我們的主節點即是Master又是Worker節點。
保存退出。
上述就是Master上的Spark的安裝。
第四步:Slave1和Slave2採用和Master完全一樣的Spark安裝配置,在此不再贅述。
啓動並查看集羣的狀況
第一步:啓動Hadoop集羣,這個在第二講中講解的非常細緻,在此不再贅述:
啓動之後在Master這臺機器上使用jps命令,可以看到如下進程信息:

在Slave1 和Slave2上使用jps會看到如下進程信息:


第二步:啓動Spark集羣
在Hadoop集羣成功啓動的基礎上,啓動Spark集羣需要使用Spark的sbin目錄下“start-all.sh”:

接下來使用“start-all.sh”來啓動Spark集羣!

讀者必須注意的是此時必須寫成“./start-all.sh”來表明是當前目錄下的“start-all.sh”,因爲我們在配置Hadoop的bin目錄中也有一個“start-all.sh”文件!
此時使用jps發現我們在主節點正如預期一樣出現了“Master”和“Worker”兩個新進程!

此時的Slave1和Slave2會出現新的進程“Worker”:


此時,我們可以進入Spark集羣的Web頁面,訪問“http://Master:8080”: 如下所示:

從頁面上我們可以看到我們有三個Worker節點及這三個節點的信息。
此時,我們進入Spark的bin目錄,使用“spark-shell”控制檯:
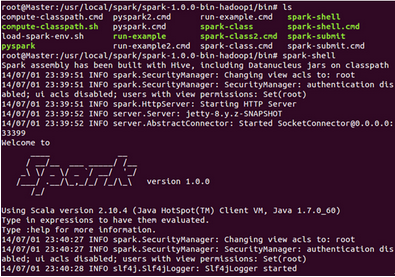

此時我們進入了Spark的shell世界,根據輸出的提示信息,我們可以通過“http://Master:4040” 從Web的角度看一下SparkUI的情況,如下圖所示:

當然,你也可以查看一些其它的信息,例如Environment:



同時,我們也可以看一下Executors:

可以看到對於我們的shell而言,Driver是Master:50777.
至此,我們 的Spark集羣搭建成功,Congratulations!