




1 Exactly-Once事務處理
2 輸出不重複的解決辦法
1 Exactly-Once事務處理
1)什麼是Exactly-Once事務?
數據僅處理一次並且僅輸出一次,這樣纔是完整的事務處理。
以銀行轉帳爲例,A用戶轉賬給B用戶,B用戶可能收到多筆錢,保證事務的一致性,也就是說事務輸出,能夠輸出且只會輸出一次,即A只轉一次,B只收一次。
2)從事務視角解密Spark Streaming架構
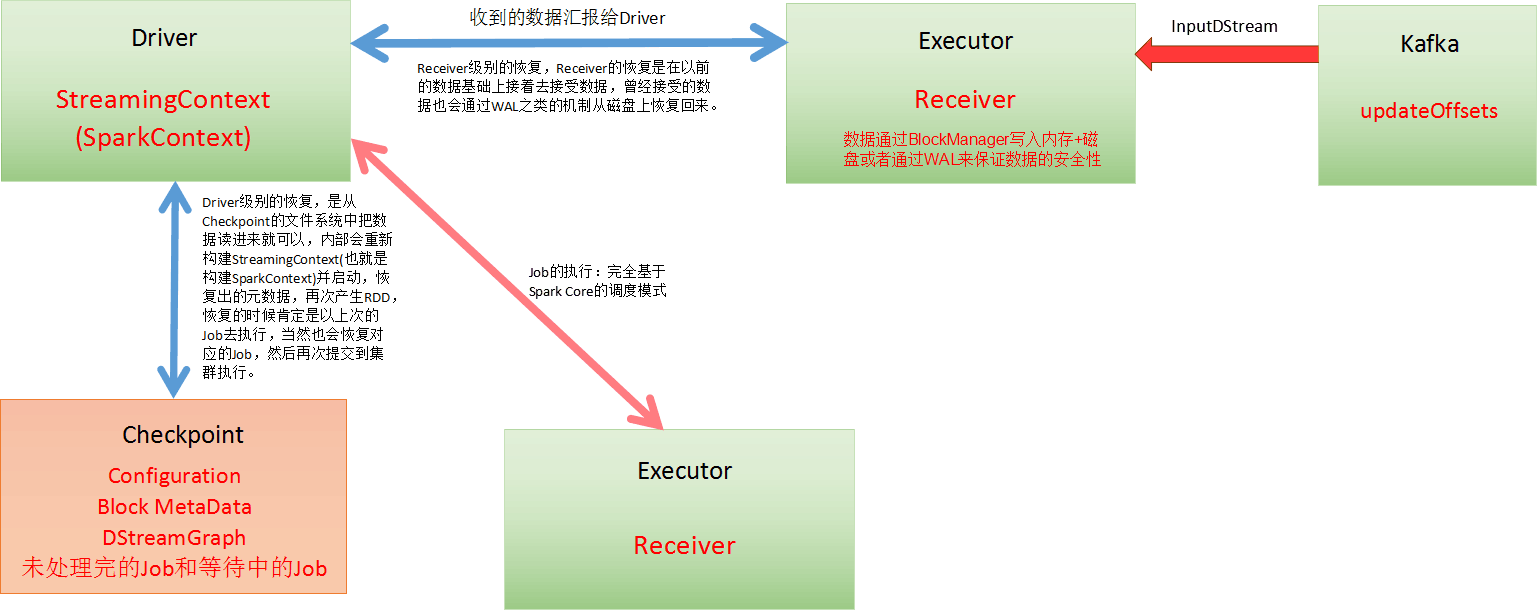
如下圖,Spark Streaming應用程序啓動,會分配資源,除非整個集羣硬件資源崩潰,一般情況下都不會有問題。Spark Streaming程序分成兩部分,一部分是Driver,另外一部分是Executor。Receiver接收到數據後不斷髮送元數據給Driver,Driver接收到元數據信息後進行CheckPoint處理。其中CheckPoint的元數據包括:Configuration(含有Spark Conf、Spark Streaming等配置信息)、Block MetaData、DStreamGraph、未處理完和等待中的Job。當然Receiver可以在多個Executor節點的上執行Job,Job的執行完全基於SparkCore的調度模式進行的。

Executor只有函數處理邏輯和數據,外部InputStream流入到Receiver中通過BlockManager寫入磁盤、內存、WAL進行容錯。WAL先寫入磁盤然後寫入Executor中,失敗可能性不大。如果1G數據要處理,Executor一條一條接收,Receiver接收數據是積累到一定記錄後纔會寫入WAL,如果Receiver線程失敗時,數據有可能會丟失。
Driver處理元數據前會進行CheckPoint,Spark Streaming獲取數據、產生作業,但沒有解決執行的問題,執行一定要經過SparkContext。Driver級別的數據修復從Driver CheckPoint中需要把數據讀入,在其內部會重新構建SparkContext、StreamingContext、SparkJob,再提交Spark集羣運行。Receiver的重新恢復時會通過磁盤的WAL從磁盤恢復過來。
3)數據可能丟失的情況及通常的解決方式
在Receiver收到數據且通過Driver的調度Executor開始計算數據的時候,如果Driver突然奔潰,則此時Executor會被殺死,那麼Executor中的數據就會丟失(如果沒有進行WAL的操作)。
此時就必須通過例如WAL的方式,讓所有的數據都通過例如HDFS的方式首先進行安全性容錯處理。此時如果Executor中的數據丟失的話,就可以通過WAL恢復回來。
注意:這種方式的弊端是通過WAL的方式會極大額損傷SparkStreaming中Receivers接收數據的性能。
4)Exactly-Once事務處理如何解決數據零丟失?
解決數據零丟失,必須有可靠的數據來源和可靠的Receiver,且整個應用程序的metadata必須進行checkpoint,且通過WAL來保證數據安全。
我們以數據來自Kafka爲例,運行在Executor上的Receiver在接收到來自Kafka的數據時會向Kafka發送ACK確認收到信息並讀取下一條信息,Kafka會通過updateOffset來記錄Receiver接收到的偏移,這種方式保證了在Executor數據零丟失。在Driver端,定期進行checkpoint操作,出錯時從Checkpoint的文件系統中把數據讀取進來進行恢復,內部會重新構建StreamingContext(也就是構建SparkContext)並啓動,恢復出元數據metedata,再次產生RDD,恢復的是上次的Job,然後再次提交到集羣執行。

{kind=link}
5)Exactly-Once事務處理如何解決數據重複讀取?
在Receiver收到數據保存到HDFS等持久化引擎但是沒有來得及進行updateOffsets(以Kafka爲例),此時Receiver崩潰後重新啓動就會通過管理Kafka的Zookeeper中元數據再次重複讀取數據,但是此時Spark Streaming認爲是成功的,但是Kafka認爲是失敗的(因爲沒有更新offset到ZooKeeper中),此時就會導致數據重新消費的情況。
以Receiver基於ZooKeeper的方式,當讀取數據時去訪問Kafka的元數據信息,在處理代碼中例如foreachRDD或transform時,將信息寫入到內存數據庫中(memorySet),在計算時讀取內存數據庫信息,判斷是否已處理過,如果以處理過則跳過計算。這些元數據信息可以保存到內存數據結構或者memsql,sqllite中。
注意:如果通過Kafka作爲數據來源的話,Kafka中有數據,然後Receiver接收的時候又會有數據副本,這個時候其實是存儲資源的浪費。Spark在1.3的時候爲了避免WAL的性能損失和實現Exactly Once而提供了Kafka Direct API,把Kafka作爲文件存儲系統。此時兼具有流的優勢和文件系統的優勢,至此Spark Streaming+Kafka就構建了完美的流處理世界(1,數據不需要拷貝副本;2,不需要WAL對性能的損耗;3,Kafka使用ZeroCopy比HDFS更高效)。所有的Executors通過Kafka API直接消息數據,直接管理Offset,所以也不會重複消費數據。
2 輸出不重複的解決辦法
1)爲什麼會有數據輸出多次重寫這個問題?
因爲Spark Streaming在計算的時候基於Spark Core天生會做以下事情導致Spark Streaming的結果(部分)重複輸出:
-
Task重試
-
慢任務推測
-
Stage重試
-
Job重試
2)具體解決方案?
-
設置spark.task.maxFailures次數爲1,這樣就不會有Task重試了。
-
設置spark.speculation爲關閉狀態,就不會有慢任務推測了,因爲慢任務推測非常消耗性能,所以關閉後可以顯著提高Spark Streaming處理性能。
-
Spark Streaming On Kafka的話,Job失敗後可以設置Kafka的參數auto.offset.reset爲largest方式。
最後再次強調可以通過transform和foreachRDD基於業務邏輯代碼進行邏輯控制來實現數據不重複消費和輸出不重複。這兩個方法類似於Spark Streaming的後門,可以做任意想象的控制操作。
備註:
資料來源於:DT_大數據夢工廠(Spark發行版本定製)
更多私密內容,請關注微信公衆號:DT_Spark
如果您對大數據Spark感興趣,可以免費聽由王家林老師每天晚上20:00開設的Spark永久免費公開課,地址YY房間號:68917580