




ASCII碼
在計算機內部,所有的信息最終都表示爲一個二進制的字符串。
每一個二進制位有0和1兩種狀態,因此八個二進制位就可以組合出256種狀態,這被稱爲一個字節。
一個字節一共可以用來表示256種不同的狀態,每一個狀態對應一個符號,就是256個符號,從0000000到11111111。
上個世紀60年代,美國製定了一套字符編碼,對英語字符與二進制位之間的關係,做了統一規定。
這被稱爲ASCII碼,一直沿用至今。
ASCII碼一共規定了128個字符的編碼。
這128個符號,只佔用了一個字節的後面7位,最前面的1位統一規定爲0。
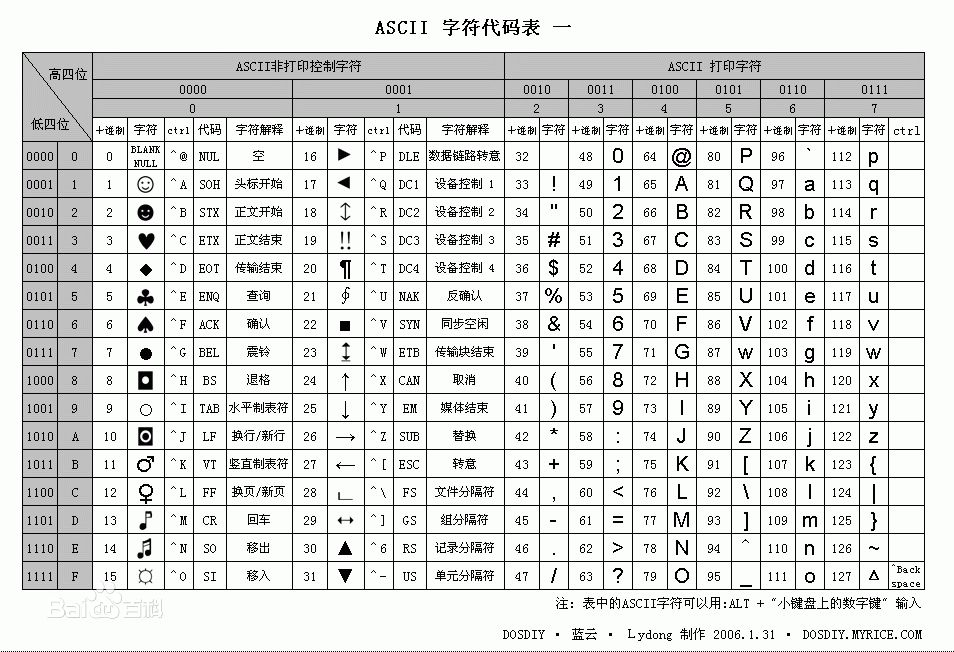
ASCII 碼剛開始制定時雖然用了一個字節的長度,但是空着最前的一位,所以只用了7位,還有一位沒用起來,那麼如果把這一位也用起來的話,也就是8位二進制,那麼就可以表示256個字符了,於是擴展 ASCII 碼誕生,保留原始的7位的基礎上,使用了最前的一位。
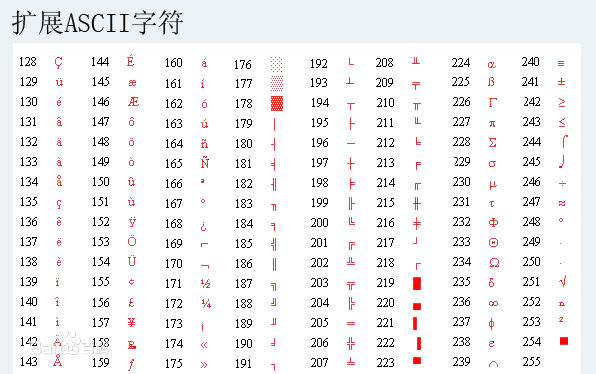
2、非ASCII編碼
英語用128個符號編碼就夠了,但是用來表示其他語言,128個符號是不夠的。
於是,一些歐洲國家就決定,利用字節中閒置的最高位編入新的符號。
這樣一來,這些歐洲國家使用的編碼體系,可以表示最多256個符號。
但是,這裏又出現了新的問題。
不同的國家有不同的字母,因此,哪怕它們都使用256個符號的編碼方式,代表的字母卻不一樣。
3.Unicode
正如上一節所說,世界上存在着多種編碼方式,同一個二進制數字可以被解釋成不同的符號。
可以想象,如果有一種編碼,將世界上所有的符號都納入其中。每一個符號都給予一個獨一無二的編碼,那麼亂碼問題就會消失。這就是Unicode,就像它的名字都表示的,這是一種所有符號的編碼。
Unicode當然是一個很大的集合,現在的規模可以容納100多萬個符號。每個符號的編碼都不一樣,比如,U+0639表示阿拉伯字母Ain,U+0041表示英語的大寫字母A,U+4E25表示漢字"嚴"。具體的符號對應表,可以查詢unicode.org,或者專門的漢字對應表。
4. Unicode的問題
Unicode只是一個符號集,它只規定了符號的二進制代碼,卻沒有規定這個二進制代碼應該如何存儲。
這裏就有兩個嚴重的問題,第一個問題是,如何才能區別Unicode和ASCII?
計算機怎麼知道三個字節表示一個符號,而不是分別表示三個符號呢?
第二個問題是,英文字母只用一個字節表示就夠了,如果Unicode統一規定,每個符號用三個或四個字節表示,那麼每個英文字母前都必然有二到三個字節是0,這對於存儲來說是極大的浪費,文本文件的大小會因此大出二三倍,這是無法接受的。
它們造成的結果是:
1)出現了Unicode的多種存儲方式,也就是說有許多種不同的二進制格式,可以用來表示Unicode。
2)Unicode在很長一段時間內無法推廣,直到互聯網的出現。
5.UTF-8
UTF-8就是在互聯網上使用最廣的一種Unicode的實現方式。
其他實現方式還包括UTF-16和UTF-32,不過在互聯網上基本不用。
重複一遍,這裏的關係是,UTF-8是Unicode的實現方式之一。
UTF-8最大的一個特點,就是它是一種變長的編碼方式。
它可以使用1~4個字節表示一個符號,根據不同的符號而變化字節長度。
UTF-8的編碼規則很簡單,只有二條:
1)對於單字節的符號,字節的第一位設爲0,後面7位爲這個符號的unicode碼。
因此對於英語字母,UTF-8編碼和ASCII碼是相同的。
2)對於n字節的符號,第一個字節的前n位都設爲1,第n+1位設爲0,後面字節的前兩位一律設爲10。
剩下的沒有提及的二進制位,全部爲這個符號的unicode碼。
下表總結了編碼規則,字母x表示可用編碼的位。
Unicode符號範圍 | UTF-8編碼方式
(十六進制) | (二進制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟據上表,解讀UTF-8編碼非常簡單。如果一個字節的第一位是0,則這個字節單獨就是一個字符;
如果第一位是1,則連續有多少個1,就表示當前字符佔用多少個字節。
6. Little endian和Big endian
Unicode碼可以採用UCS-2格式直接存儲。
以漢字"嚴"爲例,Unicode碼是4E25,需要用兩個字節存儲,一個字節是4E,另一個字節是25。
存儲的時候,4E在前,25在後,就是Big endian方式;25在前,4E在後,就是Little endian方式。
因此,第一個字節在前,就是"大頭方式"(Big endian),第二個字節在前就是"小頭方式"(Little endian)。
Unicode規範中定義,每一個文件的最前面分別加入一個表示編碼順序的字符,這個字符的名字叫做"零寬度非換行空格",用FEFF表示。這正好是兩個字節,而且FF比FE大1。
如果一個文本文件的頭兩個字節是FE FF,就表示該文件採用大頭方式;如果頭兩個字節是FF FE,就表示該文件採用小頭方式。
Unicode 雖然能容納上百萬數量的字符,但是它只是一個巨大的字符集,僅僅規定了每個符號的二進制代碼,卻沒有制定細化的存儲規則,例如當用三個字節存儲一個字符時,它同時也可以被理解爲存儲了三個 ASCII 碼,另外我們之前知道 ASCII 碼只需要一個字節,但是如果 Unicode 規定每個字符使用三個字節來存儲的話,那豈不是額外浪費兩個字節的空間?所有這些未細化的問題都將導致 Unicode 的不一致性。
首先我們要明確 UTF-8(8-bit
Unicode Transformation Format)是在統一碼(Unicode)基礎上細化並優化後的一種長度可變的字符編碼方式,它是實現 Unicode 的方式之一,除了 UTF-8,還有UTF-16,UTF-32 等都可以實現 Unicode,但是 UTF-8 相對而言是用的最爲廣泛的。
UTF-8 可以使用1到4個字節來表示字符,它通過自身的規則能夠靈活地變化長度來存儲 Unicode 字符。