HDFS是Hadoop Distribute File System 的簡稱,也就是Hadoop的一個分佈式文件系統。
一、HDFS的主要設計理念
1、存儲超大文件
這裏的“超大文件”是指幾百MB、GB甚至TB級別的文件。
2、最高效的訪問模式是 一次寫入、多次讀取(流式數據訪問)
HDFS存儲的數據集作爲hadoop的分析對象。在數據集生成後,長時間在此數據集上進行各種分析。每次分析都將設計該數據集的大部分數據甚至全部數據,因此讀取整個數據集的時間延遲比讀取第一條記錄的時間延遲更重要。
3、運行在普通廉價的服務器上
HDFS設計理念之一就是讓它能運行在普通的硬件之上,即便硬件出現故障,也可以通過容錯策略來保證數據的高可用。
二、HDFS的忌諱
1、將HDFS用於對數據訪問要求低延遲的場景
由於HDFS是爲高數據吞吐量應用而設計的,必然以高延遲爲代價。
2、存儲大量小文件
HDFS中元數據(文件的基本信息)存儲在namenode的內存中,而namenode爲單點,小文件數量大到一定程度,namenode內存就吃不消了。
三、HDFS基本概念
數據塊(block):大文件會被分割成多個block進行存儲,block大小默認爲64MB。每一個block會在多個datanode上存儲多份副本,默認是3份。
namenode:namenode負責管理文件目錄、文件和block的對應關係以及block和datanode的對應關係。
datanode:datanode就負責存儲了,當然大部分容錯機制都是在datanode上實現的。
四、HDFS基本架構圖

圖中有幾個概念需要介紹一下
Rack 是指機櫃的意思,一個block的三個副本通常會保存到兩個或者兩個以上的機櫃中(當然是機櫃中的服務器),這樣做的目的是做防災容錯,因爲發生一個機櫃掉電或者一個機櫃的交換機掛了的概率還是蠻高的。
五、HDFS寫文件流程

思考:
在datanode執行create file後,namenode採用什麼策略給client分配datanode?
順序寫入三個datanode,寫入過程中有一個datanode掛掉了,如何容錯?
client往datanode寫入數據時掛掉了,怎麼容錯?
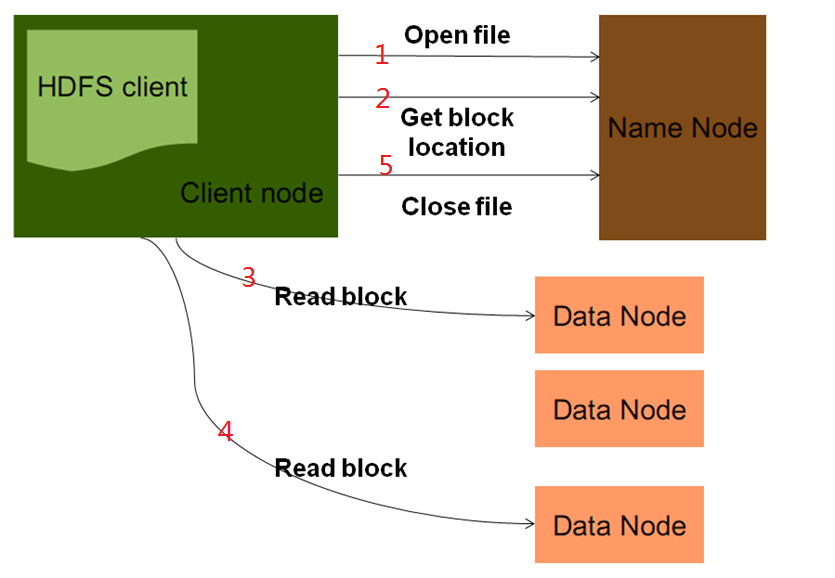
六、HDFS讀文件流程