




深度學習框架概述
author: jason_ql
Blog: https://blog.csdn.net/lql0716
1、引言
- Machine learning = looking for a Function
機器學習,其實就是尋找一個能夠描述整個數據集狀態的函數,這個函數可以是線性,也可以是非線性
1.1 應用領域
語音識別(speech recognition)
圖片識別(image recognition)
圍棋(playing go)
問答系統(dialogue system)




1.2 圖片識別框架
A set of function Model:
流程
如下圖所示,訓練出一些函數之後,篩選出效果較好的函數作爲訓練之後的最終模型,利用模型對輸入的圖片進行處理判斷識別
訓練與測試的流程圖
由以上流程可以發現,深度學習可以分爲三步,如下圖
其中第一步定義函數的過程即爲定義一個神經網絡(如下圖)
這就類比於人類的大腦的神經網絡(如下圖)





1.3 神經網絡(neural network)
1.3.1 神經元(neuron)
- 數據:
- 權重參數:
- 偏差(bias):
- 函數:
- 激活函數:
- 參數:

其中激活函數爲 S 型函數,其曲線如下圖
常用的激活函數有:


1.3.2 神經網絡
- 將神經元連接起來,就組成了一個神經網絡結構,不同的神經元可以有不同的數值,網絡結構圖如下

1.3.3 全連接前饋神經網絡(full connect feedforward network)
全連接前饋神經網絡示例
圖1
圖2
圖3
如上圖所示,如果輸入數據 ,則神經網絡會輸出全連接神經網絡結構示意圖
其中 Layer 1表示全連接第一層,這裏一共有 L 層輸出層(output layer)
如上圖,即選擇 最大的對於神經網絡的層次L、偏差 b 確定,一般是根據經驗來確定的





1.3.4 應用示例
- 手寫數字識別
- 訓練識別圖片中的數字2



1.4 goodness of function
訓練集與對應的標籤
訓練的最終目標如下圖
損失函數(訓練好的模型應該使得損失函數值達到最小)




1.5 pick the best function
- 如何找到參數 使得損失函數 最小化?

1.5.2 梯度下降法(Gradient Descent)
初始化權重
計算損失函數對權重的梯度
添加學習率係數 (即梯度下降的步長)
下降到梯度接近於0即可停止
梯度下降示例
但是,梯度下降並不能保證全局最優









1.5.2.1 梯度下降法的示例解釋
- 假如對於遊戲中的地圖


1.5.2.2 反向傳播(Backpropagation)計算梯度
- 利用反向傳播來高效的計算梯度

1.6 網絡的深度層次是不是越大越好?
深度對錯誤率的影響(Thin型網絡)
Fat 型網絡(即深度小,單層的參數足夠多)
“Thin” 與 “Fat” 型網絡哪一種好?




神經網絡與邏輯電路的類比
深度就相當於將目標模塊兒化






1.7 深度學習框架 Keras
keras
keras 文檔及示例


1.7.1 應用示例(手寫字體識別)
- 手寫字體識別






2、神經網絡的訓練方法
訓練流程圖
不要總歸咎於過擬合,也可能是其他原因
調參過程



2.1 選擇合適的損失函數
- 選擇合適的損失函數


- 精確度(accuracy)對比


- 常見的損失函數

2.2 Mini-batch 小批量的更新參數

- epoch 與 batch
- epoch
當一個完整的數據集 通過了神經網絡一次並且返回了一次,這個過程稱爲一個 epoch - batch
當一個 epoch 對於計算機而言太龐大的時候,就需要把它分成 個小塊( 個子集 ),一個小塊 就是一個batch,一個batch通過神經網絡一次就是一個epoch,那麼全部數據 要通過神經網絡一次,那就需要迭代 次才能使得這 個 batch 全部通過神經網絡一次,也就是需要經過 個 epoch
- 例子
比如對於一個有 2000 個訓練樣本的數據集。將 2000 個樣本分成大小爲 500 的 batch,那麼完成一個 epoch 需要 4 個 iteration。
- epoch


- 爲什麼不真正的進行最小化損失函數?





2.3 新的激活函數






ReLU
改進的ReLU
ReLU是Maxout的一種特殊情況,Max網絡中的激活函數可以是任何分段線性凸函數








2.4 自適應學習率(Adaptive learning rate)

一定要注意學習率的設置,如果過大,容易導致損失函數向增大的方向發展,如果過小,則會訓練的比較慢
在訓練剛開始的時候,使用較大的學習率,當進行epchs一段時間之後,將學習率逐漸調小







2.6 Momentum(動量)

在平穩的位置、鞍點、局部極小的位置很難找到最優的網絡參數
利用物理中的動量來優化梯度




2.7 Early Stopping

- 過擬合的原因





2.8 權重衰退(weight decay)
- 我們的大腦可以篩出無用的神經元,同樣的,對機器學習也這樣做



2.9 Dropout(清理掉無用的神經元)
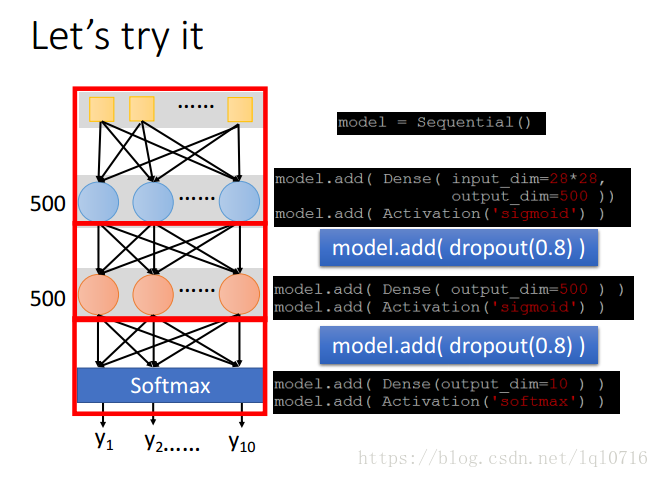
每次在更新參數之前,神經元有 的概率會被拋棄
去掉無用的神經元之後,會產生一個新的神經網絡,利用新的神經網絡繼續訓練
參數的調整




- dropout在訓練集與測試集直接的關係

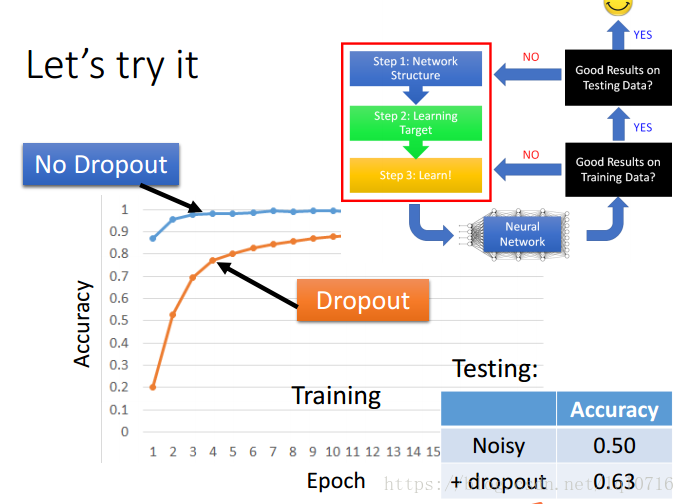


2.10 網絡結構(network structure)
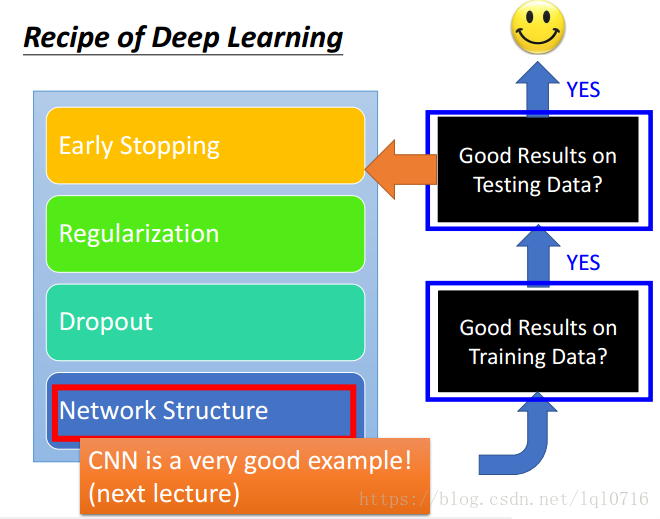- 文檔分類示例






3、改進的神經網絡
3.1 CNN (卷積神經網絡,Convolutional Neural network)
爲何要用CNN,全連接網絡過於龐大
相似的區域可以共享參數
縮放圖片可以減少參數量
CNN也可分爲如下三步
CNN流程圖








3.1.1 CNN卷積

濾波器移動的步長爲1
濾波器移動的步長爲2
卷積後,會出現相似的區域
對濾波器2也做同樣的操作
邊界填充0
對彩色圖像在三個通道分別做同樣的濾波操作






3.1.2 CNN pooling (池化)

- max poolling


- 卷積池化之後生成一個新的圖像


3.1.3 flatten
- 矩陣向量化,作爲訓練數據傳入網絡進行訓練




- 共享權重




3.1.4 goodness of function

- 可以用全連接網絡來訓練圍棋,但是使用CNN效果會更好




3.2 RNN(循環神經網絡,Recurrent Neural Network)





3.2.1 雙向(Bidirectional)RNN

3.3 LSTM(Long Short-term Memory )網絡








4、其他網絡簡介
- 監督學習(supervised learning)
Ultra deep network, attention model 強化學習(reinforcement learning)
無監督學習(unsupervised learning)





參考資料
- deep learning tutorial (李宏毅)