離散特徵的編碼分爲兩種情況:
1、離散特徵的取值之間沒有大小的意義,比如color:[red,blue],那麼就使用one-hot編碼
2、離散特徵的取值有大小的意義,比如size:[X,XL,XXL],那麼就使用數值的映射{X:1,XL:2,XXL:3}
使用pandas可以很方便的對離散型特徵進行one-hot編碼 >
import pandas as pd
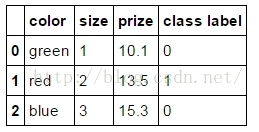
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
size_mapping = {
'XL': 3,
'L': 2,
'M': 1}
df['size'] = df['size'].map(size_mapping)
class_mapping = {label:idx for idx,label in enumerate(set(df['class label']))}
df['class label'] = df['class label'].map(class_mapping)說明:對於有大小意義的離散特徵,直接使用映射就可以了,{'XL':3,'L':2,'M':1}
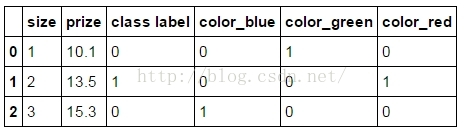
Using the get_dummies will create a new column for every unique string in a certain column:使用get_dummies進行one-hot編碼 .
`pd.get_dummies(df)`