




題記:在RAC數據庫的故障當中,節點重啓的現象很常見,在這種問題的處理當中,有一定的規律性。爲了更好的說明這個問題的處理過程,保證出現該類問題的時候,能夠有序的進行處理,特編寫此文檔。
問題現象描述
此問題的現象比較明顯,也就是數據庫自動重啓,或者是節點自動重啓,客戶端在數據庫重啓期間無法連接數據庫,導致業務斷連的現象。這種情況如果出現在業務高峯期間,將會對業務造成較大的影響,所有連接到重啓節點的用戶將斷開,系統壓力全部轉移到健康節點,如果另外一個節點無法支撐較大壓力的時候,那麼業務將全部中斷,因此,需要對此類問題進行重視,並理解此類問題的一個處理思路!
問題處理思路
遇到此類問題的發生,需要一個明確的思路,特別是當故障發生比較緊急時候,需要快速的定位故障原因,快速的解決問題。
(1)首先需要進行問題定位
通過命令檢查操作系統的啓動時間:Uptime
通過命令檢查數據庫啓動的時間:
Select start_time from v$instance;
檢查後臺日誌,看有沒有實例重啓的日誌;
診斷節點重啓問題是經常蒐集的信息。
如果上述條件滿足,那麼可以確定和本文檔相符,可繼續往下處理。
(2)接下來我們討論如何診斷節點重啓問題。
-->由ocssd導致的節點重啓。
如果在ocssd.log中出現以下錯誤,則表示節點重啓是由於丟失網絡心跳。接下來需要查看和網絡相關的信息,如操作系統日誌,OSW報表(traceroute的輸出),以確定網絡層面(cluster interconnect)是否存在問題,並確定最終的原因。

注意:如果在主節點的ocssd.log中出現以上信息的時間點要晚於節點的重啓時間,則說明節點重啓的原因不是丟失網絡心跳。
如果ocssd.log中出現以下錯誤,則表示節點重啓是由於丟失磁盤心跳。接下來需要查看操作系統日誌,OSWatcher報告(iostat的輸出),以確定i/o層面是否存在問題,並確定最終的原因。
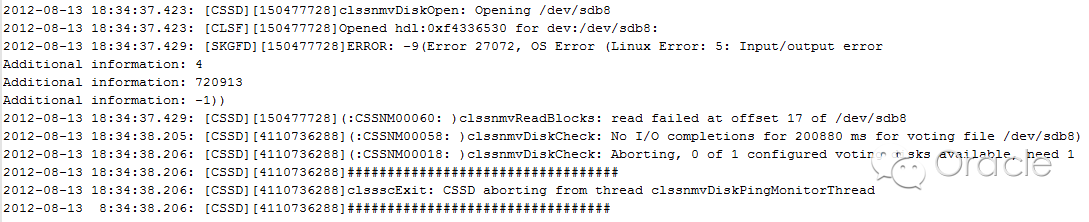
-->由oclsomon導致的節點重啓。
如果在oclsomon.log 中出現錯誤,則表示節點重啓是由於ocssd進程掛起,由於ocssd進程擁有實時(RT)優先級,很可能此時操作系統存在資源(如cpu)競爭,接下來需要察看操作系統日誌,OSW報表(vmstat,top的輸出),以確定最終的原因。
-->由oprocd導致的節點重啓。
如果在oprocd日誌中出現以下信息,則表明節點重啓是由oprocd進程導致。
Dec 21 16:15:30.369857 | LASTGASP | AlarmHandler: timeout(2312msec) exceeds interval(1000 msec)+margin(500 msec). Rebooting NOW.
由於oprocd進程通過查看系統時間以確定操作系統是否掛起,正確的配置ntp(或其他時間同步軟件),調整diagwait=13 可以避免節點重啓,另外,如果需要大幅度修改系統時間,建議首先停止CRS,在修改完成之後再重新啓動。當然,我們也不排除操作系統掛起導致oprocd重啓節點,所以,也需要查看OSWatcher報告(vmstat,top的輸出),以確定最終的原因。
-->由安裝問題導致的節點重啓。
Oracle數據庫集羣的安裝,官方文檔都已經詳盡的說明了如何配置數據庫,如何配置集羣,如何配置主機,如何配置網絡,需要哪些補丁。這些必需的條件如果在安裝的過程中沒有正確配置,也許在某一天的節點重啓中,無法準確確定問題的起因的時候,它就是罪魁禍首。
相關理論知識介紹
首先我們對能夠導致節點重啓的CRS進程進行介紹:
1、ocssd : 它的主要功能是節點監控(Node Monitoring)和組管理(GroupManagement),它是CRS的核心進程之一。節點監控是指監控集羣中節點的健康,監控的方法是通過網絡心跳(network heartbeat)和磁盤心跳(disk heartbeat)實現的,如果集羣中的節點連續丟失磁盤心跳或網絡心跳,該節點就會被從集羣中驅逐,也就是節點重啓。組管理導致的節點重啓,我們稱之爲node kill escalation(只有在11gR1以及以上版本適用),我們會在後面的文章進行詳細介紹。重啓需要在指定的時間(reboot time,一般爲3秒)內完成。
網絡心跳:ocssd.bin進程每秒鐘向集羣中的各個節點通過私網發送網絡心跳信息,以確認各個節點是否正常。如果某個節點連續丟失網絡心跳達到閥值,misscount(默認爲30秒,如果存在其他集羣管理軟件則爲600秒),集羣會通過表決盤進行投票,使丟失網絡心跳的節點被主節點驅逐出集羣,即節點重啓。如果集羣只包含2個節點,則會出現腦裂,結果是節點號小的節點存活下來,即使是節點號小的節點存在網絡問題。
磁盤心跳:ocssd.bin進程每秒鐘都會向所有表決盤(Voting File)註冊本節點的狀態信息,這個過程叫做磁盤心跳。如果某個節點連續丟失磁盤心跳達到閥值,disk timeou(一般爲200秒),則該節點會自動重啓以保證集羣的一致性。另外,CRS只要求[N/2]+1個表決盤可用即可,其中N爲表決盤數量,一般爲奇數。
2、oclsomon:這個進程負責監控ocssd是否掛起,如果發現ocssd.bin存在性能問題,則重啓該節點。
3、oprocd:這個進程只在Linux和Unix系統,並且第三方集羣管理軟件未安裝的情況下才會出現。如果它發現節點掛起,則重啓該節點。
注意:以上的所有進程都是由腳本init.cssd產生的。
故障處理案例分析
經過數據庫故障磨鍊的兄弟都知道,數據庫是一個綜合體,它的每一次故障都涉及到方方面面,比如網絡,系統,存儲,應用等等。如果把數據庫作爲一個獨立體處理,也許在故障處理的過程中,就失去了擴展的思維,把自己禁錮在某個點,而無法突破。只有把數據庫看作一個整體,你纔有那種衆裏尋他千百度,驀然回首,卻在燈火闌珊處的感覺!
這個時候,時間定格在2012年7月7日,這時候,突然電話鈴響,緊急報障,某數據庫節點一發生重啓,故障就是命令,事不宜遲,登錄數據庫查看相關信息。
信息也比較明顯:
[cssd(3539304)]CRS-1611:nodecs_02 (0) at 75% heartbeat fatal, eviction in 0.000 seconds
也就是心跳超時,導致節點重啓。既然是心跳超時,那麼有兩種原因:一種原因是心跳磁盤無法連接,另一種是是心跳網絡無法連接。首先去查證心跳磁盤有沒有問題:
$ crsctl query css votedisk
0. 0 /dev/rvotedisk1
1. 0 /dev/rvotedisk2
2. 0 /dev/rvotedisk3
located 3 votedisk(s).
從這裏可以看出,心跳磁盤正常訪問,沒有異常。那就是網絡了,由於沒有部署相關的網絡監控軟件,此時無法確定網絡什麼時候出了異常,斷鏈情況如何,於是部署OSW軟件,並且在後臺部署長ping命令:
On Node1:
traceroute -s 192.168.65.234-r 192.168.65.235 1472
ping -s 1500 -c 2 -I192.168.65.234 192.168.65.234
ping -s 1500 -c 2 -I 192.168.65.234192.168.65.235
On Node2:
#traceroute -s 192.168.65.235-r 192.168.65.234 1472
ping -s 1500 -c 2 -I192.168.65.235 192.168.65.235
ping -s 1500 -c 2 -I192.168.65.235 192.168.65.234)
時間又在飛逝,系統不知道是不是知道我們布好了天羅地網,也不重啓了,大家都以爲相安無事,也漸漸淡忘,唯有我們數據庫最後的保護者,還是一直在關注着,因爲我們知道,這是我們的責任,這是DBA的一種執着的責任,對客戶的負責,對數據庫的負責。
終於這天來到了,2012年8月1日,這傢伙終於不老實了,再次發生重啓。我們有條不紊的進入數據庫,按部就班的搬出我們的網,看看捕到了什麼大魚。首先,還是檢查日誌,和上次重啓一樣,是發生腦裂,剔除節點;然後檢查系統層面,沒有任何報錯,排除硬件原因引起的重啓;最後用我們部署的腳本,找到了相關的蛛絲馬跡:
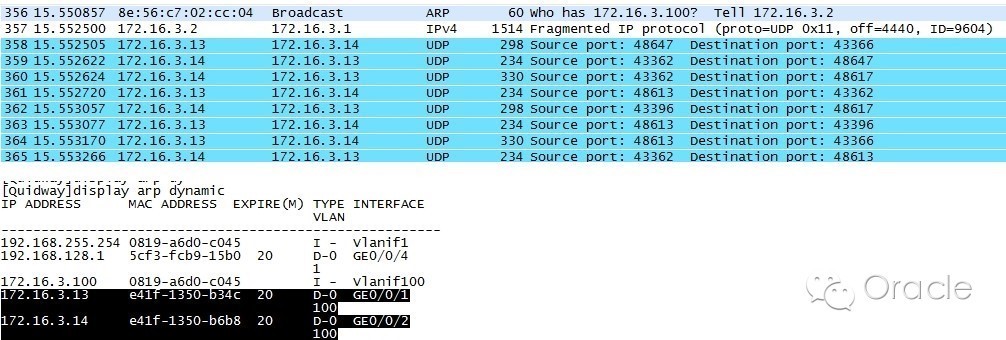
從這裏我們可以看到,交換機的信息出現混亂,從末數據庫的主機的端口接收到了其它IP的包信息。
查看OSW信息:
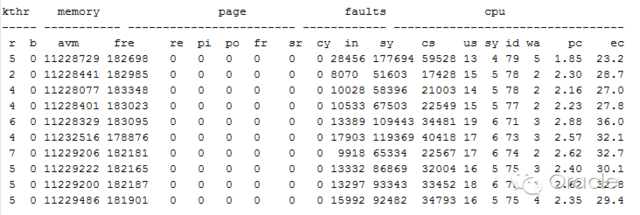
發現在故障期間,主機資源都算比較充足,因此可以排除由於主機負載引起的腦裂重啓。
那會不會是系統或者是DRM配置的問題呢,因爲在我們接觸的案例中,有這種問題,於是進行相關整改:
通過關閉DRM設置,目前DRM是打開的;
oraclebug,Bug 5190596 LMON dumps LMS0 too often during DRM leading to IPC sendtimout
aix6.1沒有打補丁,Block Lost or IPC Send Timeout PossibleWithout Fix of APAR IZ97457
整改完成後,數據庫再次穩定,這個時候,時間已經到達2012年8月14日,很不幸的消息,從14日開始,連續發生多次重啓,越來越頻繁的重啓,牽動着每一位參與此故障處理的同事們的心,就像是自己的孩子,一次又一次被人家欺負,而我們又只能遠遠看着。
時間來到8月20日,這段時間也經歷了一個插曲,兩個節點的操作系統版本竟然不一致,於是矛頭也曾經指向了它,但是進行操作系統內核升級後,節點還是多次出現重啓。終於,經過這麼長時間的排查和摸索,最終將問題定位在網絡上。有了大家一致認定的方向,剩下的就是排查了,首先指向的就是交換機,因爲此交換機是多部主機共用,而且是同一個vlan,這在實際運用中,是比較大的隱患。
後續網絡的同事發現原交換機配置錯誤,同一個IP段劃分了2個VLAN,VLAN1用於某數據庫系統,VLAN100用於某應用系統的心跳,導致數據包異常。(其實這個不是原因,當時網絡同事想改了後,再換回來,想不通過換交換機的方式,但是我們堅持要換,所以才查出是交換機的問題,如果當時沒換,改完之後還是有問題,估計又得折騰了,而且是折騰我們自己,遇到網絡問題的時候,能最小化問題,就最小化問題)。從後面處理的過程就可以看出,後來重新換回交換機後,先後通過調整心跳交換機配置、停止IBM的DHCP server、恢復交換機出廠配置操作,問題依然沒有解決,而且後續的日誌也更有欺騙性:
2012-09-0701:34:08.928
[cssd(3539304)]CRS-1605:CSSDvoting file is online: /dev/rvotedisk1. Details in/u01/oracle/product/10.2/crs/log/cs_01/cssd/ocssd.log.
2012-09-0701:34:08.931
[cssd(3539304)]CRS-1605:CSSDvoting file is online: /dev/rvotedisk2. Details in/u01/oracle/product/10.2/crs/log/cs_01/cssd/ocssd.log.
更換交換機後,節點再沒有重啓,至此,耗時60天的主機重啓問題,終於得到圓滿的解決。
回顧整個故障的處理過程,走過了不少的彎路,從主機,存儲,網絡,數據庫
各個層面進行了多層次的分析,一步一步的走近答案。在這個過程中,有着永不放棄精神,有着責任心,最終抽絲剝繭的找到了問題的最終答案。
後記
作爲一個合格的DBA,必須擁有豐富的知識,冷靜的頭腦和解決問題的思路;
DBA這個職業並不像是圈外人士想象的就是錢多事少的職業;
DBA應該是這種狀態,當你維護的數據庫健康穩定的運作,當最終用戶由衷的讚歎:這個查詢真快的時候,我們會心的一笑;
作爲一個DBA老兵,我們應該有那種心裏的感覺,當處理完每一次故障的時候,驀然回首的時候,它卻在燈火闌珊處……
關於MCELOG的一點補充:
1.MCE(Machine Check Exception)是用來報告主機硬件相關問題的一種日誌機制.
2.MCE(Machine Check Exception)的日誌文件是/var/log/mcelog
3.該mcelog不一定在任何一臺Linux主機上都存在.只有發生硬件報錯了,纔會有 /var/log/mcelog.
4.在/var/log/messages文件中,也可能有mce的一點痕跡.搜索關鍵字是mce
比如:
kernel: mce: [Hardware Error]: Machine check events logged
比如:
Jun 28 18:42:11 <hostname> mcelog: failed to prefill DIMM database from DMI data
-----根據工程經驗:如上一行不代表硬件有問題
參考資料:
Oracle Linux: Hardware Error: Machine check Events Logged (文檔 ID 2048885.1)