




Boyer-Moore高質量實現代碼詳解與算法詳解
鑑於我見到對算法本身分析非常透徹的文章以及實現的非常精巧的文章,所以就轉載了,本文的貢獻在於將兩者結合起來,方便大家瞭解代碼實現!
本文轉自http://www.cnblogs.com/xubenben/p/3359364.html,感謝作者的總結,本人也對其進行部分修改
C語言代碼實現轉自:
http://www-igm.univ-mlv.fr/~lecroq/string/node14.html
另外,網站http://www.cs.utexas.edu/users/moore/best-ideas/string-searching/fstrpos-example.html有個關於BM算法的詳細例子,看看挺好的。
BM算法的論文在這兒http://www.cs.utexas.edu/users/moore/publications/fstrpos.pdf
BM算法
後綴匹配,是指模式串的比較從右到左,模式串的移動也是從左到右的匹配過程,經典的BM算法其實是對後綴蠻力匹配算法的改進。所以還是先從最簡單的後綴蠻力匹配算法開始。下面直接給出僞代碼,注意這一行代碼:j++;BM算法所做的唯一的事情就是改進了這行代碼,即模式串不是每次移動一步,而是根據已經匹配的後綴信息,從而移動更多的距離。
j = 0;
while (j <= strlen(T) - strlen(P)) {
for (i = strlen(P) - 1; i >= 0 && P[i] ==T[i + j]; --i)
if (i < 0)
match;
else
j++;
}
爲了實現更快移動模式串,BM算法定義了兩個規則,好後綴規則和壞字符規則,如下圖可以清晰的看出他們的含義。利用好後綴和壞字符可以大大加快模式串的移動距離,不是簡單的++j,而是j+=max (shift(好後綴), shift(壞字符))

先來看如何根據壞字符來移動模式串,shift(壞字符)分爲兩種情況:
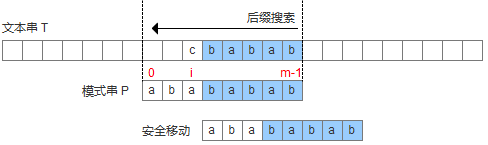
壞字符沒出現在模式串中,這時可以把模式串移動到壞字符的下一個字符,繼續比較,如下圖:
壞字符出現在模式串中,這時可以把模式串第一個出現的壞字符和母串的壞字符對齊,當然,這樣可能造成模式串倒退移動,如下圖:
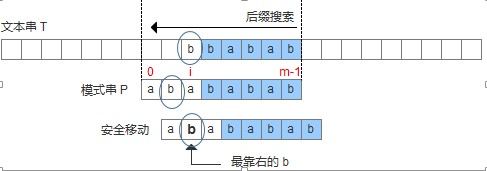
此處配的圖是不準確的,因爲顯然加粗的那個b並不是”最靠右的”b。而且也與下面給出的代碼衝突!我看了論文,論文的意思是最右邊的。當然了,儘管一時大意圖配錯了,論述還是沒有問題的,我們可以把圖改正一下,把圈圈中的b改爲字母f就好了。接下來的圖就不再更改了,大家心裏有數就好。
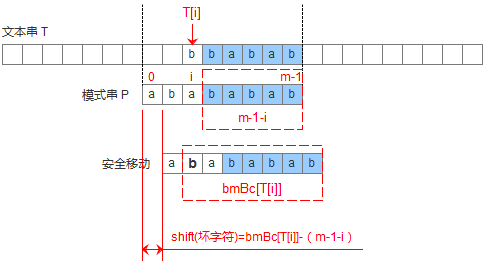
爲了用代碼來描述上述的兩種情況,設計一個數組bmBc['k'],表示壞字符‘k’在模式串中出現的位置距離模式串末尾的最大長度,那麼當遇到壞字符的時候,模式串可以移動距離爲: shift(壞字符) = bmBc[T[i]]-(m-1-i)。如下圖:
數組bmBc的創建非常簡單,直接貼出代碼如下:
void preBmBc(char *x, int m, int bmBc[]) {//
int i;
for (i = 0; i < ASIZE; ++i)
bmBc[i] = m;
for (i = 0; i < m - 1; ++i)
bmBc[x[i]] = (m - 1) - i;//距離模式串尾部的距離。
}代碼分析:
ASIZE是指字符種類個數,爲了方便起見,就直接把ASCII表中的256個字符全表示了,哈哈,這樣就不會漏掉哪個字符了。
第一個for循環處理上述的第一種情況,這種情況比較容易理解就不多提了。
第二個for循環,bmBc[x[i]]中x[i]表示模式串中的第i個字符。
bmBc[x[i]] = m - i - 1;也就是計算x[i]這個字符到串尾部的距離。
爲什麼第二個for循環中,i從小到大的順序計算呢?哈哈,技巧就在這兒了,原因在於就可以在同一字符多次出現的時候以最靠右的那個字符到尾部距離爲最終的距離。當然了,如果沒在模式串中出現的字符,其距離就是m了。
再來看如何根據好後綴規則移動模式串,shift(好後綴)分爲三種情況:
模式串中有子串匹配上好後綴,此時移動模式串,讓該子串和好後綴對齊即可,如果超過一個子串匹配上好後綴,則選擇最靠左邊的子串對齊。
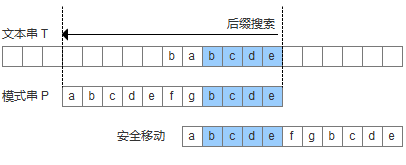
模式串中沒有子串匹配上後後綴,此時需要尋找模式串的一個最長前綴,並讓該前綴等於好後綴的後綴,尋找到該前綴後,讓該前綴和好後綴對齊即可。
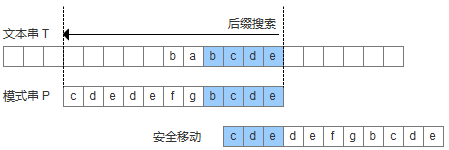
模式串中沒有子串匹配上後後綴,並且在模式串中找不到最長前綴,讓該前綴等於好後綴的後綴。此時,直接移動模式到好後綴的下一個字符。
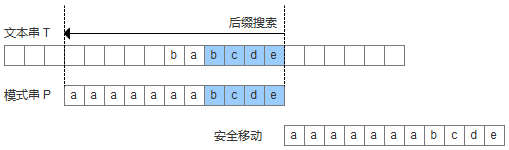
爲了實現好後綴規則,需要定義一個數組suffix[],其中suffix[i] = s 表示以i爲邊界,與模式串後綴匹配的最大長度,如下圖所示,用公式可以描述:滿足P[i-s, i] == P[m-s, m]的最大長度s。

構建suffix數組的代碼如下:
void suffixes(char *x, int m, int *suff) //suff數組中記錄了,模式串中i位置前suff[i]的部分能夠和後綴最大的匹配如下圖
{ //m爲模式串的長度
suff[m-1]=m; //suff[m-1]本身就是m
for (i=m-2;i>=0;--i){//開始從尾巴處開始計算
q=i;//最終計算的q爲模式串中能和最後的後綴匹配的起始位置。如下圖q=1及p[1]=b
while(q>=0&&x[q]==x[m-1-i+q]) //只要q大於0,這裏-i+q其實就是字符串匹配的長的負值
--q; //只要一個匹配後,就將值減1去看前一個字符是否匹配。
suff[i]=i-q;
}
}註解:這一部分代碼乏善可陳,都是常規代碼,這裏就不多說了。
有了suffix數組,就可以定義bmGs[]數組,bmGs[i] 表示遇到好後綴時,模式串應該移動的距離,其中i表示好後綴前面一個字符的位置(也就是壞字符的位置),構建bmGs數組分爲三種情況,分別對應上述的移動模式串的三種情況
模式串中有子串匹配上好後綴
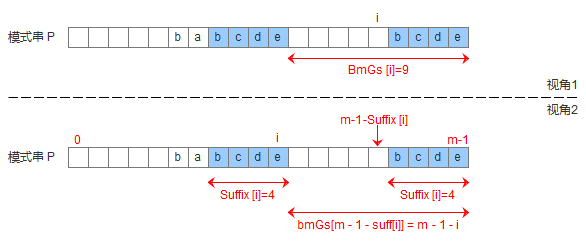
模式串中沒有子串匹配上好後綴,但找到一個最大前綴
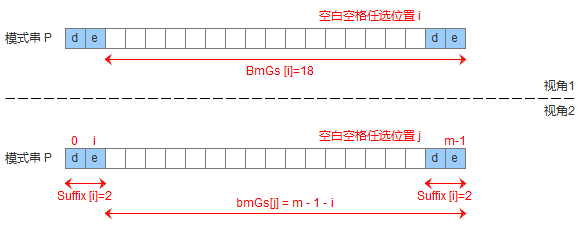
模式串中沒有子串匹配上好後綴,但找不到一個最大前綴

構建bmGs數組的代碼如下:
void preBmGs(char *x, int m, int bmGs[]) {//bmGs[i] 表示遇到好後綴時,模式串應該移動的距離
int i, j, suff[XSIZE];
suffixes(x, m, suff);
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)//這裏很巧妙,可以看看後面介紹,大意就是匹配到情況2了,前綴匹配了。
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)//這裏設置這個條件就是隻允許修改一次,因爲這個i從大變小,防止出現情況一 後又出現了情況二,而改變bmGs的數組值。
bmGs[j] = m - 1 - i;
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}註解:
這一部分代碼挺有講究,寫的很巧妙,這裏談談我的理解。講解代碼時候是分爲三種情況來說明的,其實第二種和第三種可以合併,因爲第三種情況相當於與好後綴匹配的最長前綴長度爲0。
由於我們的目的是獲得精確的bmGs[i],故而若一個字符同時符合上述三種情況中的幾種,那麼我們選取最小的bmGs[i]。比如當模式傳中既有子串可以匹配上好後串,又有前綴可以匹配好後串的後串,那麼此時我們應該按照前者來移動模式串,也就是bmGs[i]較小的那種情況。故而每次修改bmGs[i]都應該使其變小,記住這一點,很重要!
而在這三種情況中第三種情況獲得的bmGs[i]值大於第二種大於第一種。故而寫代碼的時候我們先計算第三種情況,再計算第二種情況,再計算第一種情況。爲什麼呢,因爲對於同一個位置的多次修改只會使得bmGs[i]越來越小。
代碼4-5行對應了第三種情況,7-11行對於第二種情況,12-13對應第三種情況。
第三種情況比較簡單直接賦值m,這裏就不多提了。
第二種情況有點意思,咱們細細的來品味一下。
1. 爲什麼從後往前,也就是i從大到小?
原因在於如果i,j(i>j)位置同時滿足第二種情況,那麼m-1-i<m-1-j,而第十行代碼保證了每個位置最多隻能被修改一次,故而應該賦值爲m-1-i,這也說明了爲什麼要 從後往前計算。
2. 第8行代碼的意思是找到了合適的位置,爲什麼這麼說呢?
因爲根據suff的定義,我們知道
x[i+1-suff[i]…i]==x[m-1-siff[i]…m-1],而suff[i]==i+1,我們知道x[i+1-suff[i]…i]=x[0,i],也就是前綴,滿足第二種情況。
3. 第9-11行就是在對滿足第二種情況下的賦值了。第十行確保了每個位置最多隻能被修改一次。
第12-13行就是處理第一種情況了。爲什麼順序從前到後呢,也就是i從小到大?
原因在於如果suff[i]==suff[j],i<j,那麼m-1-i>m-1-j,我們應該取後者作爲bmGs[m - 1 - suff[i]]的值。
再來重寫一遍BM算法:
void BM(char *x, int m, char *y, int n) {
int i, j, bmGs[XSIZE], bmBc[ASIZE];
/* 初始化這兩個數組 */
preBmGs(x, m, bmGs);
preBmBc(x, m, bmBc);
/* Searching */
j = 0;
while (j <= n - m) {
for (i = m - 1; i >= 0 && x[i] == y[i + j]; --i);
if (i < 0) {
OUTPUT(j);
j += bmGs[0];
}
else
j += MAX(bmGs[i], bmBc[y[i + j]] - m + 1 + i);//這裏j的變化依據壞字符和好後綴所給出的可以移動的最大值 去移動。
}
}