




今天介紹一下lxml,lxml是在Python語言中處理XML和HTML的功能最豐富、使用最簡單的庫(官方文檔是這麼寫)。[官方pdf文檔]網盤地址:https://pan.baidu.com/s/1o887fkA密碼:ed9k
1 安裝
pip方式安裝
pip install lxmlpycharm安裝(略,見前文)
2 Xpath術語
2.1 節點
在 XPath 中,有七種類型的節點:元素、屬性、文本、命名空間、處理指令、註釋以及文檔(根)節點。XML 文檔是被作爲節點樹來對待的。樹的根被稱爲文檔節點或者根節點。
請看下面這個 XML 文檔:
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>上面的XML文檔中的節點例子:
<bookstore> (根節點)
<author>J K. Rowling</author> (元素節點)
lang="en" (屬性節點) 2.2 節點關係
父(Parent)
每個元素以及屬性都有一個父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>子(Children)
元素節點可有零個、一個或多個子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>同胞(Sibling)
擁有相同的父的節點
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>先輩(Ancestor)
某節點的父、父的父,等等。
在下面的例子中,title 元素的先輩是 book 元素和 bookstore 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>後代(Descendant)
某個節點的子,子的子,等等。
在下面的例子中,bookstore 的後代是 book、title、author、year 以及 price 元素:
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>2.3 選取節點
XPath 使用路徑表達式在 XML 文檔中選取節點。節點是通過沿着路徑或者 step 來選取的。
下面列出了最有用的路徑表達式:
| 表達式 | 描述 |
|---|---|
| nodename | 選取此節點的所有子節點 |
| / | 從根節點選取 |
| // | 從匹配選擇的當前節點選擇文檔中的節點,而不考慮它們的位置。 |
| . | 選取當前節點 |
| .. | 選取當前節點的父節點 |
| @ | 選取屬性 |
實例
在下面的表格中,我們已列出了一些路徑表達式以及表達式的結果:
| 路徑表達式 | 結果 |
|---|---|
| bookstore | 選取 bookstore 元素的所有子節點 |
| /bookstore | 選取根元素 bookstore。註釋:假如路徑起始於正斜槓( / ),則此路徑始終代表到某元素的絕對路徑! |
| bookstore/book | 選取屬於 bookstore 的子元素的所有 book 元素 |
| //book | 選取所有 book 子元素,而不管它們在文檔中的位置。 |
| bookstore//book | 選擇屬於 bookstore 元素的後代的所有 book 元素,而不管它們位於 bookstore 之下的什麼位置。 |
| //@lang | 選取名爲 lang 的所有屬性。 |
謂語(Predicates)
謂語用來查找某個特定的節點或者包含某個指定的值的節點。
謂語被嵌在方括號中。
實例
在下面的表格中,我們列出了帶有謂語的一些路徑表達式,以及表達式的結果:
| 路徑表達式 | 結果 |
|---|---|
| /bookstore/book[1] | 選取屬於 bookstore 子元素的第一個 book 元素。 |
| /bookstore/book[last()] | 選取屬於 bookstore 子元素的最後一個 book 元素。 |
| /bookstore/book[last()-1] | 選取屬於 bookstore 子元素的倒數第二個 book 元素。 |
| /bookstore/book[position()<3] | 選取最前面的兩個屬於 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 選取所有擁有名爲 lang 的屬性的 title 元素。 |
| //title[@lang='eng'] | 選取所有 title 元素,且這些元素擁有值爲 eng 的 lang 屬性。 |
| /bookstore/book[price>35.00] | 選取 bookstore 元素的所有 book 元素,且其中的 price 元素的值須大於 35.00。 |
| /bookstore/book[price>35.00]/title | 選取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值須大於 35.00。 |
選取未知節點
XPath 通配符可用來選取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素節點 |
| @* | 匹配任何屬性節點 |
| node() | 匹配任何類型的節點 |
實例
在下面的表格中,我們列出了一些路徑表達式,以及這些表達式的結果:
| 路徑表達式 | 結果 |
|---|---|
| /bookstore/* | 選取 bookstore 元素的所有子元素 |
| //* | 選取文檔中的所有元素 |
| //title[@*] | 選取所有帶有屬性的 title 元素 |
選取若干路徑
通過在路徑表達式中使用“|”運算符,您可以選取若干個路徑。
2.4 XPath 運算符
下面列出了可用在 XPath 表達式中的運算符: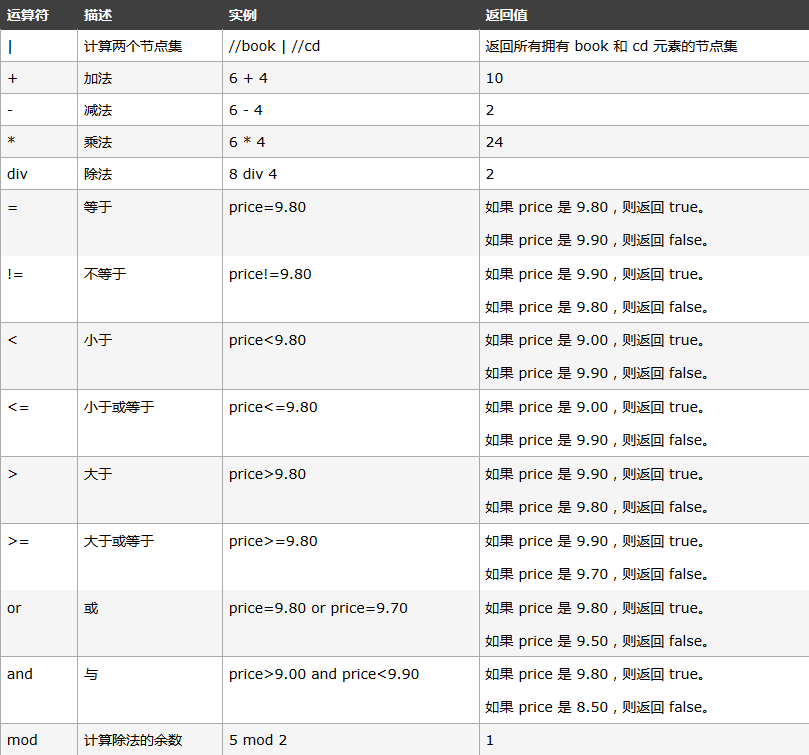
2.5 XPath 實例
# -*- coding: utf-8 -*-
from lxml import etree
text = """
<div class="wrapper">
<i class="iconfont icon-back" id="back"></i>
<a href="/" id="channel">新浪社會</a>
<ul id="nav">
<li><a href="http://domestic.firefox.sina.com/" title="國內">國內</a></li>
<li><a href="http://world.firefox.sina.com/" title="國際">國際</a></li>
<li><a href="http://mil.firefox.sina.com/" title="軍事">軍事</a></li>
<li><a href="http://photo.firefox.sina.com/" title="圖片">圖片</a></li>
<li><a href="http://society.firefox.sina.com/" title="社會">社會</a></li>
<li><a href="http://ent.firefox.sina.com/" title="娛樂">娛樂</a></li>
<li><a href="http://tech.firefox.sina.com/" title="科技">科技</a></li>
<li><a href="http://sports.firefox.sina.com/" title="體育">體育</a></li>
<li><a href="http://finance.firefox.sina.com/" title="財經">財經</a></li>
<li><a href="http://auto.firefox.sina.com/" title="汽車">汽車</a></li>
</ul>
<i class="iconfont icon-liebiao" id="menu"></i>
</div>
"""
# 創建html對象
html = etree.HTML(text)
# 獲取所有a標籤的href內容
results = html.xpath('//a/@href')
print(results)
# 獲取所有id爲channel的a標籤的href內容
results2 = html.xpath('//a[@id="channel"]/@href')
print(results2)
# 獲取所有li標籤下的a標籤的文本內容
results3 = html.xpath('//li/a/text()')
print(results3)
運行結果如下:
['/', 'http://domestic.firefox.sina.com/', 'http://world.firefox.sina.com/', 'http://mil.firefox.sina.com/', 'http://photo.firefox.sina.com/', 'http://society.firefox.sina.com/', 'http://ent.firefox.sina.com/', 'http://tech.firefox.sina.com/', 'http://sports.firefox.sina.com/', 'http://finance.firefox.sina.com/', 'http://auto.firefox.sina.com/']
['/']
['新浪社會']
['國內', '國際', '軍事', '圖片', '社會', '娛樂', '科技', '體育', '財經', '汽車']
具體的應用還需要自己多練習,我這裏只是簡單舉例子。好的lxml部分就結束了。