




Scrapy是一個應用程序框架,用於抓取web站點和提取結構化數據,這些數據可以用於廣泛的應用,如數據挖掘、信息處理。儘管Scrapy最初是爲web抓取而設計的,但它也可以使用api(比如Amazon Associates的web服務)或作爲一個通用的web爬蟲程序來提取數據。
1 環境安裝
最初Scrapy是不支持python3的,現在已經支持了,所以我們主要還是使用python3來實現。
1.1Ubuntu 14.04 或以上版本安裝
主要注意相關依賴包其它linux版本基本相似(會玩linux,這個都是小菜一碟,不多講解)
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
sudo apt-get install python3 python3-dev
pip install scrapy1.2 windows上安裝
windows上安裝稍微複雜一點,首先要安裝Anaconda,Anaconda下載地址:
百度網盤下載 密碼:3kjd 官網下載地址
Anaconda安裝很簡單,就是下一步,下一步即可,安裝完後一定要記得配置環境變量,不然也會出錯,配置步驟如下: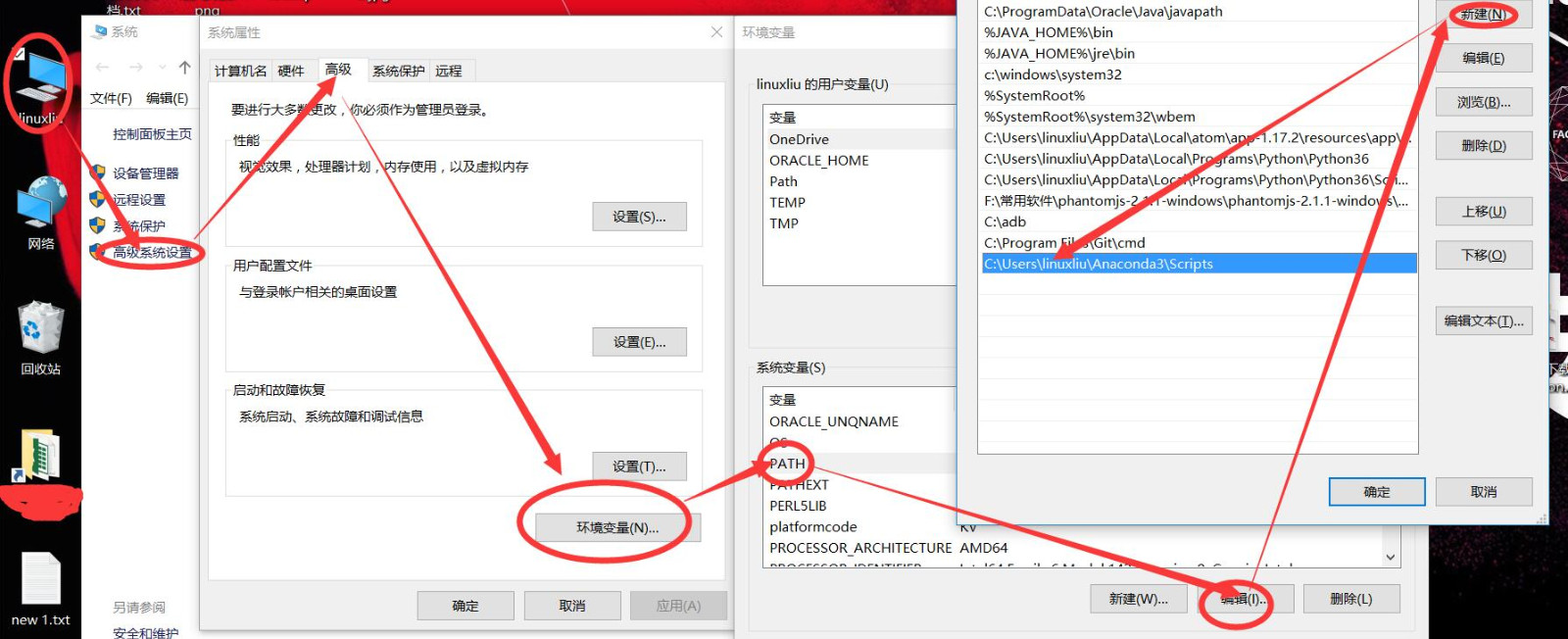
按照箭頭方向配置即可,注意Anaconda安裝的路徑要與你的安裝路徑對應。配置完成後直接cmd,後運行命令:
conda install scrapy如下圖: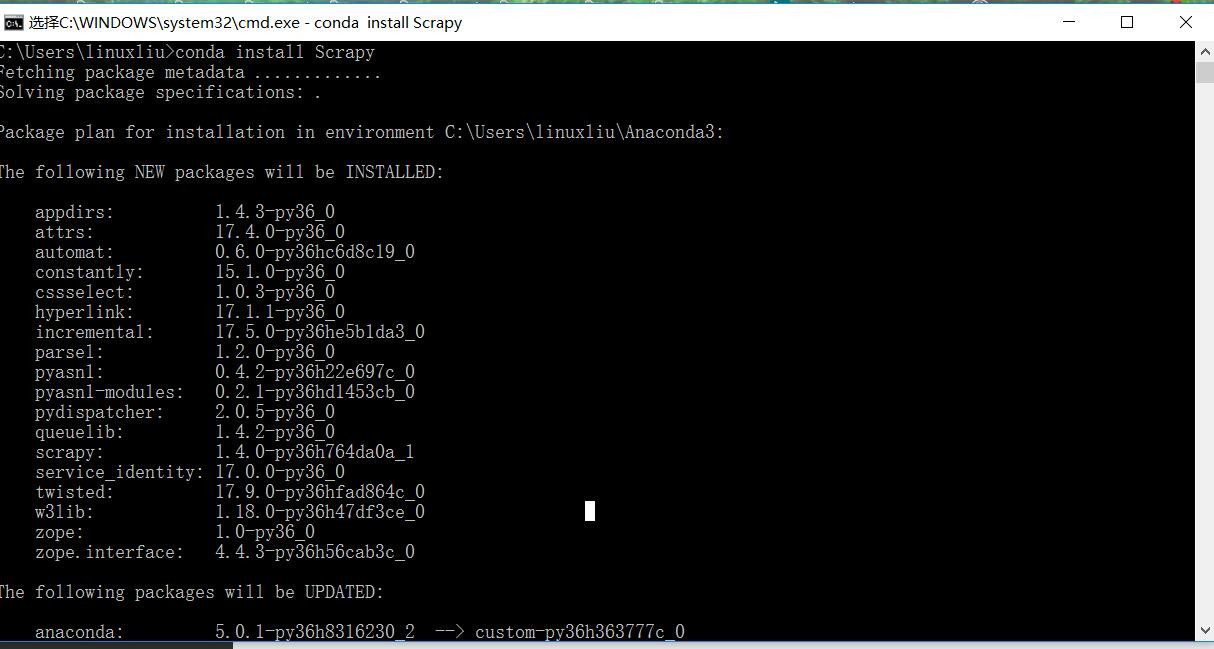
選擇Y回車
Scrapy就安裝完成了。
2 Scrapy使用
2.1 創建一個項目
在開始爬取之前,您必須創建一個新的Scrapy項目。 進入你打算存儲代碼的目錄中,運行下列命令:
scrapy startproject tutorial如圖:
創建完成後的目錄結構如下: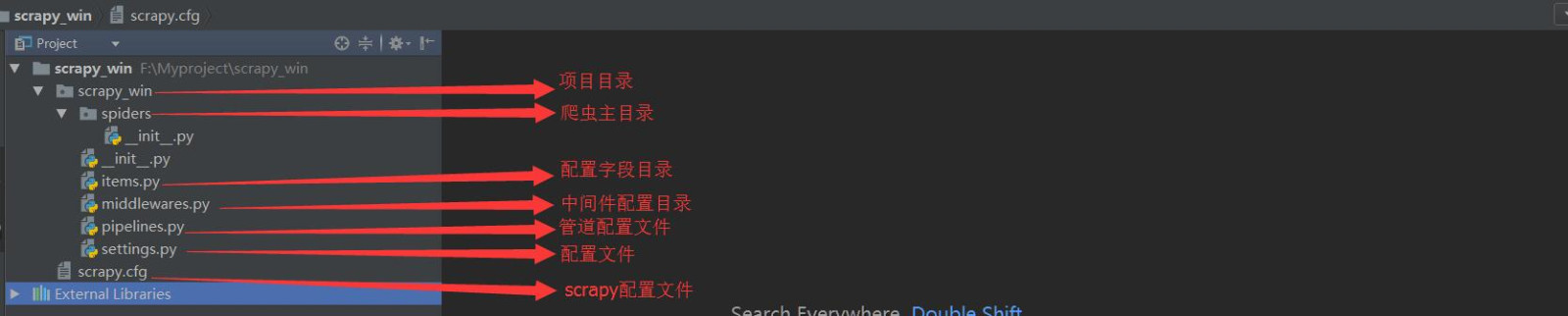
2.2 pycharm中調試scrapy代碼
如果在pycharm中調試scrapy,需要安裝scrapy,在安裝scrapy之前還有幾個依賴文件也要安裝,如下:
twisted報錯
這些包都可以用pycharm插件工具安裝,但其中安裝twisted時候會出現報錯,報錯內容大概如下:
building 'twisted.test.raiser' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-toolstwisted報錯解決辦法如下:
下載twisted對應版本的whl文件(如我的Twisted‑17.5.0‑cp36‑cp36m‑win_amd64.whl)下載地址上文已經給出,cp後面是python版本,amd64代表64位,運行命令,注意Twisted文件的路徑:
pip install Twisted-17.5.0-cp36-cp36m-win_amd64.whl解決上面報錯後在pip install scrapy就OK了。
pycharm無法直接調試scrapy
pycharm是無法直接調試scrapy的,需要我們在項目中做一些配置,配置如下圖: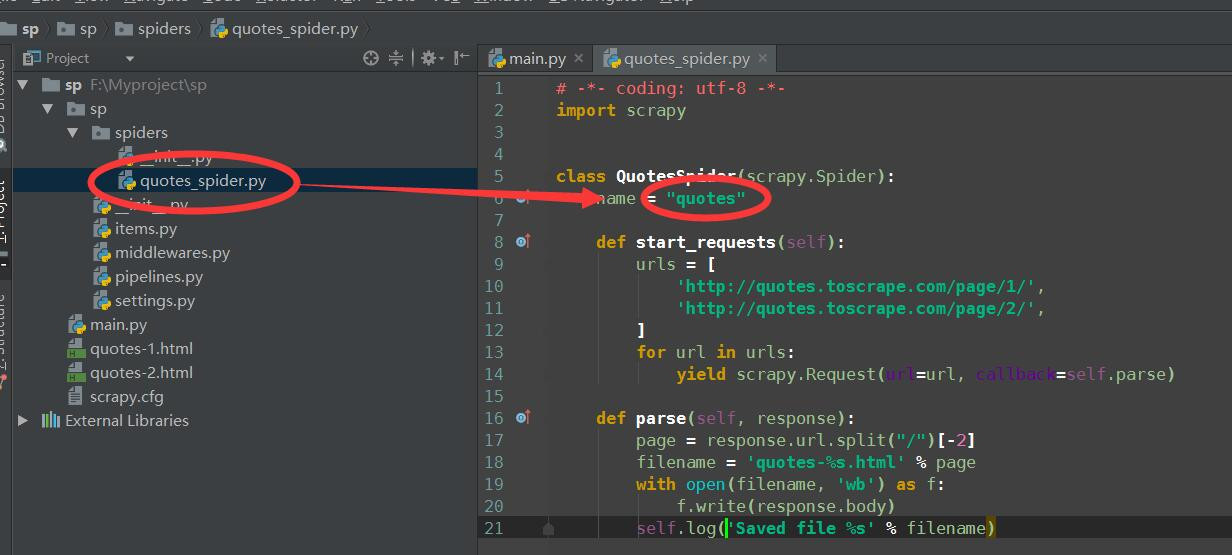
圖一
圖一中quotes_spider.py名稱是你自己定義的,類中的name = "quotes"名稱也是自定義的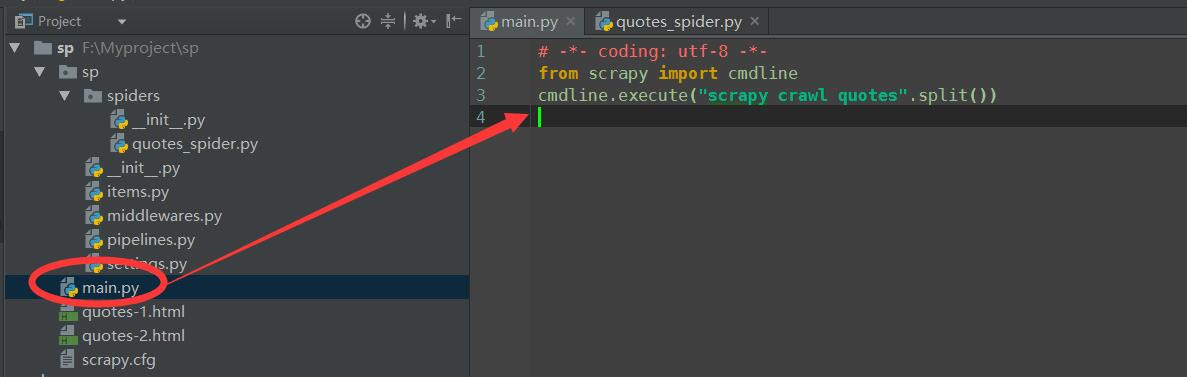
圖二
然後在scrapy.cfg的同級目錄下創建一個main.py文件,內容如上圖,這裏要注意cmdline.execute("scrapy crawl quotes".split())中的quotes要與圖一中的name=“quotes”是對應的。每次執行main.py就可以了。
quotes_spider.py代碼如下:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)如上代碼,我們的爬蟲子類scrapy.Spider並定義了一些屬性和方法:
name:標識爬蟲。它必須在一個項目中是唯一的,不能爲不同的爬蟲設置相同的名稱。
start_requests():必須返回一個可重複的請求(您可以返回一個請求列表,或者編寫一個生成器函數),這將使爬蟲開始爬行。後續請求將依次從這些初始請求中生成。
parse():將調用一個方法來處理每個請求所下載的響應。響應參數是保存頁面內容的TextResponse的一個實例,並且有進一步的幫助方法來處理它。parse()方法通常解析響應,提取解析的數據,並找到新的url來跟蹤和創建新的請求。
win32api報錯
按照上面配置完成後,你會發現提示no module name win32api錯誤,這是因爲沒有安裝win32的模塊造成的
win32api報錯解決辦法
安裝win32模塊,安裝有兩種方式:
1.pycharm安裝工具直接安裝
2.下載win32包用pip install 包名 方式安裝我下載的包 更多版本包
我這邊pycharm直接安裝是失敗的,所以我用的第二種安裝方式
pip install pywin32-222-cp36-cp36m-win_amd64.whl 安裝完之後問題解決,運行main.py後結果如下: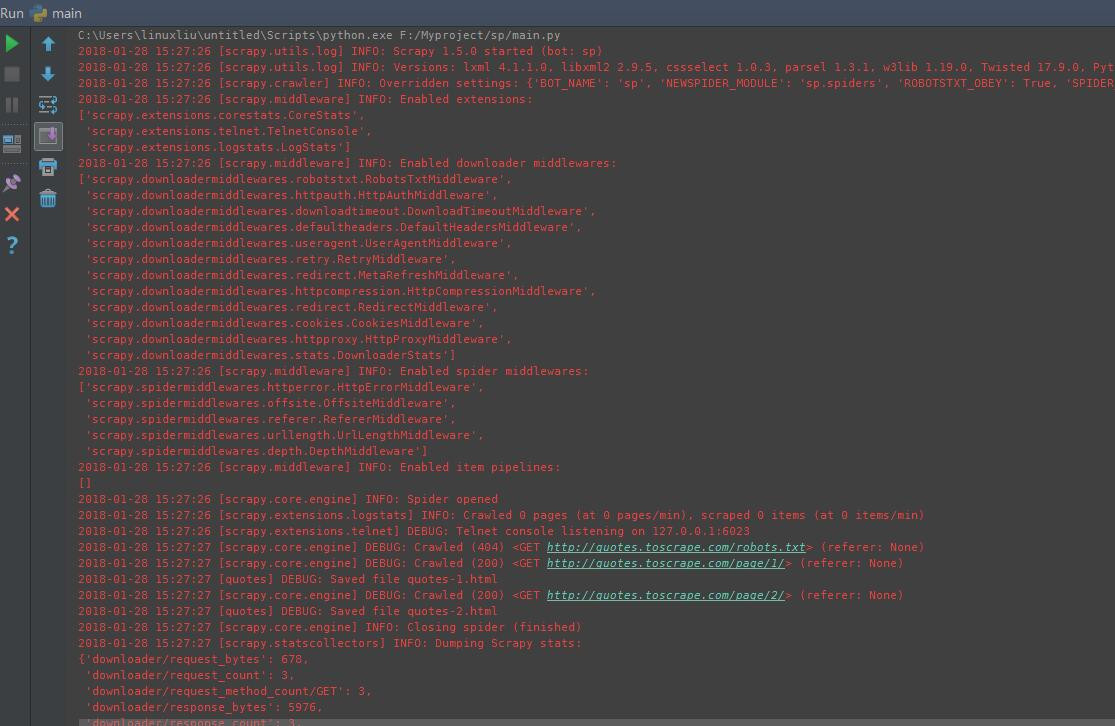
3 開始scrapy
3.1 scrapy流程及總體架構
執行完main.py後,檢查當前目錄中的文件,你應該注意到已經創建了兩個新文件:quotes-1.html和quotes-2.html,並且帶有相應的url的內容。那通過scrapy是如何工作的呢?接下來我們講一下scrapy的工作流程及總體架構。下圖描述了scrapy的架構及它的組件是如何交互的: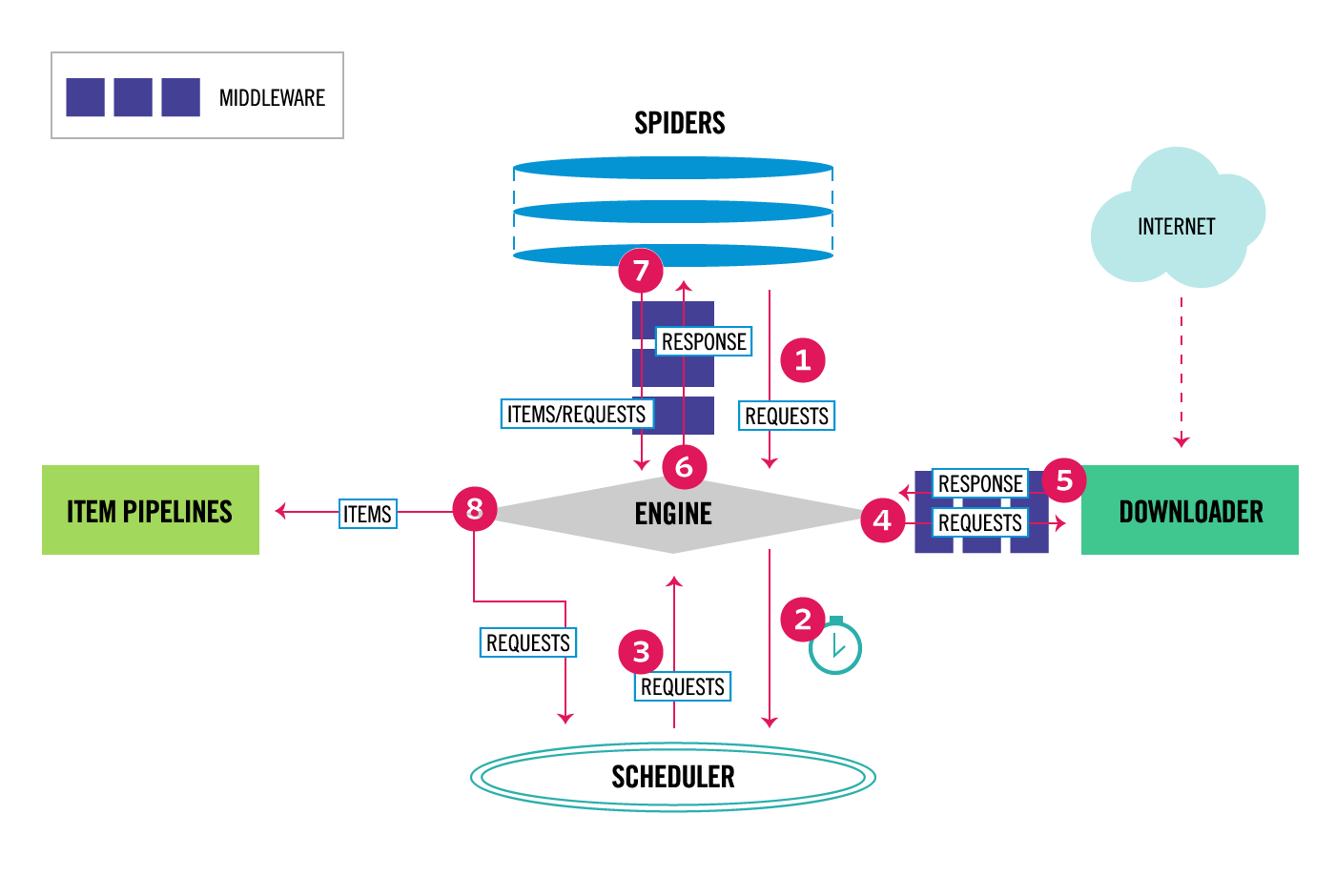
從上圖可以看出scrapy中的數據流由執行引擎控制,流程如下:
- 1.引擎(Engine)得到最初初始的請求,通過spiders去爬取;
- 2.引擎(Engine)在調度器(Scheduler)中調度請求,並尋找下一個請求去爬取;
- 3.調度程序(Scheduler)將下一個請求返回給引擎(Engine);
- 4.引擎(Engine)將請求發送給下載器(Downloader),通過下載器(Downloader)中間件(請參閱proce***equest());
- 5.一旦頁面完成下載後,下載器(Downloader)會生成一個響應(使用該頁面)並將其通過Downloader中間件發送到引擎;
- 6.引擎(Engine)接收來自下載器(Downloader)的響應,並將其發送給spiders進行處理,通過spiders中間件;
- 7.spiders處理響應並返回提取的items 和新請求返回到引擎,通過爬行器spider中間件;
- 8.引擎(Engine)將處理過的項目發送到項目管道(Item Pipelines),然後將處理過的請求發送到調度程序(Scheduler),並請求下一個可能要爬取的請求;
- 9.這個過程重複(從步驟1)直到不再有來自調度程序(Scheduler)的請求。
3.2 scrapy各組件功能
Scrapy引擎(Engine)
引擎負責控制系統的所有組件之間的數據流,當某些動作發生時觸發事件
調度程序(Scheduler)
調度程序接收來自引擎的請求,並在引擎請求時對它們進行排隊,以便在稍後(也對引擎)請求時提供它們
下載器(Downloader)
下載器負責獲取web頁面,並將它們提供給引擎,而引擎又將它們提供給spiders
Spiders
Spiders是類,它定義了一個特定的站點(或一組站點)如何被抓取,包括如何執行爬取(也就是跟蹤鏈接)以及如何從它們的頁面中提取結構化數據(例如抓取項目)。換句話說,Spiders是定義爲特定站點爬行和解析頁面的定製行爲(或者,在某些情況下,是一組站點)的定製行爲。
Item Pipeline
Item Pipeline負責處理由spiders提取出來的item,典型的處理有清理、 驗證及持久化(例如存取到數據庫中)。
下載器中間件(Downloader middlewares)
Downloader中間件是一種特定的鉤子,它位於引擎和Downloader之間,當請求從引擎傳遞到Downloader時,以及從Downloader傳遞到引擎的響應。
Spider middlewares
Spider middlewares是位於引擎和spiders之間的特定鉤子,能夠處理spiders輸入(響應)和輸出(items和requests)。
事件驅動網絡
scrapy是用Twisted編寫的,它是一種流行的、用於Python的事件驅動的網絡框架。因此,它是使用非阻塞(又稱爲異步)的併發性來實現的。
scrapy入門,這一篇就結束了,歡迎批評指正~!