




From:http://science.dataguru.cn/article-10491-1.html
第一層、瞭解SVM
支持向量機,因其英文名爲support vector machine,故一般簡稱SVM,通俗來講,它是一種二類分類模型,其基本模型定義爲特徵空間上的間隔最大的線性分類器,其學習策略便是間隔最大化,最終可轉化爲一個凸二次規劃問題的求解。
1.1、分類標準的起源:Logistic迴歸
理解SVM,咱們必須先弄清楚一個概念:線性分類器。
給定一些數據點,它們分別屬於兩個不同的類,現在要找到一個線性分類器把這些數據分成兩類。如果用x表示數據點,用y表示類別(y可以取1或者-1,分別代表兩個不同的類),一個線性分類器的學習目標便是要在n維的數據空間中找到一個超平面(hyper plane),這個超平面的方程可以表示爲( wT中的T代表轉置):

可能有讀者對類別取1或-1有疑問,事實上,這個1或-1的分類標準起源於logistic迴歸。
Logistic迴歸目的是從特徵學習出一個0/1分類模型,而這個模型是將特性的線性組合作爲自變量,由於自變量的取值範圍是負無窮到正無窮。因此,使用logistic函數(或稱作sigmoid函數)將自變量映射到(0,1)上,映射後的值被認爲是屬於y=1的概率。
假設函數

其中x是n維特徵向量,函數g就是logistic函數。

可以看到,將無窮映射到了(0,1)。
而假設函數就是特徵屬於y=1的概率。

1.2、線性分類的一個例子
下面舉個簡單的例子,如下圖所示,現在有一個二維平面,平面上有兩種不同的數據,分別用圈和叉表示。由於這些數據是線性可分的,所以可以用一條直線將這兩類數據分開,這條直線就相當於一個超平面,超平面一邊的數據點所對應的y全是 -1 ,另一邊所對應的y全是1。



換言之,在進行分類的時候,遇到一個新的數據點x,將x代入f(x) 中,如果f(x)小於0則將x的類別賦爲-1,如果f(x)大於0則將x的類別賦爲1。
接下來的問題是,如何確定這個超平面呢?從直觀上而言,這個超平面應該是最適合分開兩類數據的直線。而判定“最適合”的標準就是這條直線離直線兩邊的數據的間隔最大。所以,得尋找有着最大間隔的超平面。
1.3、函數間隔Functional margin與幾何間隔Geometrical margin
在超平面w*x+b=0確定的情況下,|w*x+b|能夠表示點x到距離超平面的遠近,而通過觀察w*x+b的符號與類標記y的符號是否一致可判斷分類是否正確,所以,可以用(y*(w*x+b))的正負性來判定或表示分類的正確性。於此,我們便引出了函數間隔(functional margin)的概念。

但這樣定義的函數間隔有問題,即如果成比例的改變w和b(如將它們改成2w和2b),則函數間隔的值f(x)卻變成了原來的2倍(雖然此時超平面沒有改變),所以只有函數間隔還遠遠不夠。
事實上,我們可以對法向量w加些約束條件,從而引出真正定義點到超平面的距離--幾何間隔(geometrical margin)的概念。


1.4、最大間隔分類器Maximum Margin Classifier的定義
對一個數據點進行分類,當超平面離數據點的“間隔”越大,分類的確信度(confidence)也越大。所以,爲了使得分類的確信度儘量高,需要讓所選擇的超平面能夠最大化這個“間隔”值。這個間隔就是下圖中的Gap的一半。



OK,到此爲止,算是瞭解到了SVM的第一層,對於那些只關心怎麼用SVM的朋友便已足夠,不必再更進一層深究其更深的原理。
第二層、深入SVM
2.1、從線性可分到線性不可分
2.1.1、從原始問題到對偶問題的求解

因爲現在的目標函數是二次的,約束條件是線性的,所以它是一個凸二次規劃問題。這個問題可以用現成的QP (Quadratic Programming) 優化包進行求解。一言以蔽之:在一定的約束條件下,目標最優,損失最小。
此外,由於這個問題的特殊結構,還可以通過拉格朗日對偶性(Lagrange Duality)變換到對偶變量 (dual variable) 的優化問題,即通過求解與原問題等價的對偶問題(dual problem)得到原始問題的最優解,這就是線性可分條件下支持向量機的對偶算法,這樣做的優點在於:一者對偶問題往往更容易求解;二者可以自然的引入核函數,進而推廣到非線性分類問題。


勘誤:經讀者qq_28543029指出,這裏的條件不應該是KKT條件,要讓兩者等價需滿足strong duality (強對偶),而後有學者在強對偶下提出了KKT條件,且KKT條件的成立要滿足constraint qualifications,而constraint qualifications之一就是Slater條件。所謂Slater 條件,即指:凸優化問題,如果存在一個點x,使得所有等式約束都成立,並且所有不等式約束都嚴格成立(即取嚴格不等號,而非等號),則滿足Slater 條件。對於此處,Slater 條件成立,所以d*≤p*可以取等號。
一般地,一個最優化數學模型能夠表示成下列標準形式:

其中,f(x)是需要最小化的函數,h(x)是等式約束,g(x)是不等式約束,p和q分別爲等式約束和不等式約束的數量。

2.1.3、對偶問題求解的3個步驟

提醒:有讀者可能會問上述推導過程如何而來?說實話,其具體推導過程是比較複雜的,如下圖所示:

最後,得到:

如 jerrylead所說:“倒數第4步”推導到“倒數第3步”使用了線性代數的轉置運算,由於ai和yi都是實數,因此轉置後與自身一樣。“倒數第3步”推導到“倒數第2步”使用了(a+b+c+…)(a+b+c+…)=aa+ab+ac+ba+bb+bc+…的乘法運算法則。最後一步是上一步的順序調整。

(3)在求得L(w, b, a) 關於 w 和 b 最小化,以及對的極大之後,最後一步則可以利用SMO算法求解對偶問題中的拉格朗日乘子。
上述式子要解決的是在參數上求最大值W的問題,至於和都是已知數。要了解這個SMO算法是如何推導的,請跳到下文第3.5節、SMO算法。
到目前爲止,我們的 SVM 還比較弱,只能處理線性的情況,下面我們將引入核函數,進而推廣到非線性分類問題。
2.1.5、線性不可分的情況


從1.5節到上述所有這些東西,便得到了一個maximum margin hyper plane classifier,這就是所謂的支持向量機(Support Vector Machine)。當然,到目前爲止,我們的 SVM 還比較弱,只能處理線性的情況,不過,在得到了對偶dual 形式之後,通過 Kernel 推廣到非線性的情況就變成了一件非常容易的事情了(相信,你還記得本節開頭所說的:“通過求解對偶問題得到最優解,這就是線性可分條件下支持向量機的對偶算法,這樣做的優點在於:一者對偶問題往往更容易求解;二者可以自然的引入核函數,進而推廣到非線性分類問題”)。
2.2、核函數Kernel
2.2.1、特徵空間的隱式映射:核函數
事實上,大部分時候數據並不是線性可分的,這個時候滿足這樣條件的超平面就根本不存在。在上文中,我們已經瞭解到了SVM處理線性可分的情況,那對於非線性的數據SVM咋處理呢?對於非線性的情況,SVM 的處理方法是選擇一個核函數 κ(,) ,通過將數據映射到高維空間,來解決在原始空間中線性不可分的問題。
具體來說,在線性不可分的情況下,支持向量機首先在低維空間中完成計算,然後通過核函數將輸入空間映射到高維特徵空間,最終在高維特徵空間中構造出最優分離超平面,從而把平面上本身不好分的非線性數據分開。如圖7-7所示,一堆數據在二維空間無法劃分,從而映射到三維空間裏劃分:

而在我們遇到核函數之前,如果用原始的方法,那麼在用線性學習器學習一個非線性關係,需要選擇一個非線性特徵集,並且將數據寫成新的表達形式,這等價於應用一個固定的非線性映射,將數據映射到特徵空間,在特徵空間中使用線性學習器,因此,考慮的假設集是這種類型的函數:

而由於對偶形式就是線性學習器的一個重要性質,這意味着假設可以表達爲訓練點的線性組合,因此決策規則可以用測試點和訓練點的內積來表示:
如果有一種方式可以在特徵空間中直接計算內積〈φ(xi · φ(x)〉,就像在原始輸入點的函數中一樣,就有可能將兩個步驟融合到一起建立一個非線性的學習器,這樣直接計算法的方法稱爲核函數方法:
核是一個函數K,對所有x,z(-X,滿足,這裏φ是從X到內積特徵空間F的映射。
2.2.2、核函數:如何處理非線性數據
來看個核函數的例子。如下圖所示的兩類數據,分別分佈爲兩個圓圈的形狀,這樣的數據本身就是線性不可分的,此時咱們該如何把這兩類數據分開呢(下文將會有一個相應的三維空間圖)?








2.2.3、幾個核函數
通常人們會從一些常用的核函數中選擇(根據問題和數據的不同,選擇不同的參數,實際上就是得到了不同的核函數),例如:
多項式核,顯然剛纔我們舉的例子是這裏多項式核的一個特例(R = 1,d = 2)。雖然比較麻煩,而且沒有


2.2.4、核函數的本質
上面說了這麼一大堆,讀者可能還是沒明白核函數到底是個什麼東西?我再簡要概括下,即以下三點:
實際中,我們會經常遇到線性不可分的樣例,此時,我們的常用做法是把樣例特徵映射到高維空間中去(如上文2.2節最開始的那幅圖所示,映射到高維空間後,相關特徵便被分開了,也就達到了分類的目的);
但進一步,如果凡是遇到線性不可分的樣例,一律映射到高維空間,那麼這個維度大小是會高到可怕的(如上文中19維乃至無窮維的例子)。那咋辦呢?
此時,核函數就隆重登場了,核函數的價值在於它雖然也是將特徵進行從低維到高維的轉換,但核函數絕就絕在它事先在低維上進行計算,而將實質上的分類效果表現在了高維上,也就如上文所說的避免了直接在高維空間中的複雜計算。
最後引用這裏的一個例子舉例說明下核函數解決非線性問題的直觀效果。
假設現在你是一個農場主,圈養了一批羊羣,但爲預防狼羣襲擊羊羣,你需要搭建一個籬笆來把羊羣圍起來。但是籬笆應該建在哪裏呢?你很可能需要依據牛羣和狼羣的位置建立一個“分類器”,比較下圖這幾種不同的分類器,我們可以看到SVM完成了一個很完美的解決方案。

這個例子從側面簡單說明了SVM使用非線性分類器的優勢,而邏輯模式以及決策樹模式都是使用了直線方法。
OK,不再做過多介紹了,對核函數有進一步興趣的,還可以看看此文。
2.3、使用鬆弛變量處理 outliers 方法

例如可能並不是因爲數據本身是非線性結構的,而只是因爲數據有噪音。對於這種偏離正常位置很遠的數據點,我們稱之爲 outlier ,在我們原來的 SVM 模型裏,outlier 的存在有可能造成很大的影響,因爲超平面本身就是隻有少數幾個 support vector 組成的,如果這些 support vector 裏又存在 outlier 的話,其影響就很大了。例如下圖:
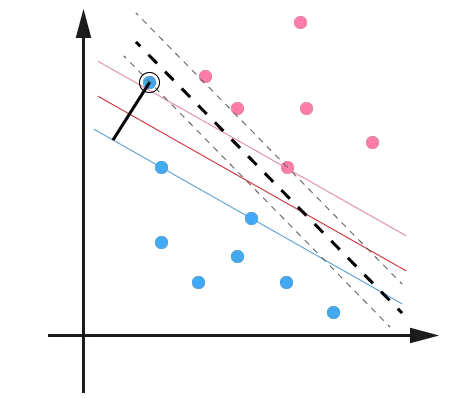
用黑圈圈起來的那個藍點是一個 outlier ,它偏離了自己原本所應該在的那個半空間,如果直接忽略掉它的話,原來的分隔超平面還是挺好的,但是由於這個 outlier 的出現,導致分隔超平面不得不被擠歪了,變成途中黑色虛線所示(這只是一個示意圖,並沒有嚴格計算精確座標),同時 margin 也相應變小了。當然,更嚴重的情況是,如果這個 outlier 再往右上移動一些距離的話,我們將無法構造出能將數據分開的超平面來。
爲了處理這種情況,SVM 允許數據點在一定程度上偏離一下超平面。例如上圖中,黑色實線所對應的距離,就是該 outlier 偏離的距離,如果把它移動回來,就剛好落在原來的 超平面 藍色間隔邊界上,而不會使得超平面發生變形了。
插播下一位讀者@Copper_PKU的理解:“換言之,在有鬆弛的情況下outline點也屬於支持向量SV,同時,對於不同的支持向量,拉格朗日參數的值也不同,如此篇論文《Large Scale Machine Learning》中的下圖所示:

對於遠離分類平面的點值爲0;對於邊緣上的點值在[0, 1/L]之間,其中,L爲訓練數據集個數,即數據集大小;對於outline數據和內部的數據值爲1/L。更多請參看本文文末參考條目第51條。”



把前後的結果對比一下(錯誤修正:圖中的Dual formulation中的Minimize應爲maxmize):


OK,理解到這第二層,已經能滿足絕大部分人一窺SVM原理的好奇心,然對於那些想在證明層面理解SVM的則還很不夠,但進入第三層理解境界之前,你必須要有比較好的數理基礎和邏輯證明能力,不然你會跟我一樣,吃不少苦頭的。
第三層、證明SVM
說實話,凡是涉及到要證明的東西.理論,便一般不是怎麼好惹的東西。絕大部分時候,看懂一個東西不難,但證明一個東西則需要點數學功底,進一步,證明一個東西也不是特別難,難的是從零開始發明創造這個東西的時候,則顯艱難(因爲任何時代,大部分人的研究所得都不過是基於前人的研究成果,前人所做的是開創性工作,而這往往是最艱難最有價值的,他們被稱爲真正的先驅。牛頓也曾說過,他不過是站在巨人的肩上。你,我則更是如此)。
正如陳希孺院士在他的著作《數理統計學簡史》的第4章、最小二乘法中所講:在科研上諸多觀念的革新和突破是有着很多的不易的,或許某個定理在某個時期由某個人點破了,現在的我們看來一切都是理所當然,但在一切沒有發現之前,可能許許多多的頂級學者畢其功於一役,耗盡一生,努力了幾十年最終也是無功而返。
話休絮煩,要證明一個東西先要弄清楚它的根基在哪,即構成它的基礎是哪些理論。OK,以下內容基本是上文中未講到的一些定理的證明,包括其背後的邏輯、來源背景等東西,還是讀書筆記。
本部分導述
3.1節線性學習器中,主要闡述感知機算法;
3.2節非線性學習器中,主要闡述mercer定理;
3.3節、損失函數;
3.4節、最小二乘法;
3.5節、SMO算法;
3.6節、簡略談談SVM的應用;
3.1、線性學習器
3.1.1、感知機算法
這個感知機算法是1956年提出的,年代久遠,依然影響着當今,當然,可以肯定的是,此算法亦非最優,後續會有更詳盡闡述。不過,有一點,你必須清楚,這個算法是爲了幹嘛的:不斷的訓練試錯以期尋找一個合適的超平面(是的,就這麼簡單)。

下面,舉個例子。如下圖所示,憑我們的直覺可以看出,圖中的紅線是最優超平面,藍線則是根據感知機算法在不斷的訓練中,最終,若藍線能通過不斷的訓練移動到紅線位置上,則代表訓練成功。

既然需要通過不斷的訓練以讓藍線最終成爲最優分類超平面,那麼,到底需要訓練多少次呢?Novikoff定理告訴我們當間隔是正的時候感知機算法會在有限次數的迭代中收斂,也就是說Novikoff定理證明了感知機算法的收斂性,即能得到一個界,不至於無窮循環下去。

然後後續怎麼推導出最大分類間隔請回到本文第一、二部分,此處不重複板書。
同時有一點得注意:感知機算法雖然可以通過簡單迭代對線性可分數據生成正確分類的超平面,但不是最優效果,那怎樣才能得到最優效果呢,就是上文中第一部分所講的尋找最大分類間隔超平面。此外,Novikoff定理的證明請見這裏。
3.2、非線性學習器
3.2.1、Mercer定理

3.3、損失函數
在本文1.0節有這麼一句話“支持向量機(SVM)是90年代中期發展起來的基於統計學習理論的一種機器學習方法,通過尋求結構化風險最小來提高學習機泛化能力,實現經驗風險和置信範圍的最小化,從而達到在統計樣本量較少的情況下,亦能獲得良好統計規律的目的。”但初次看到的讀者可能並不瞭解什麼是結構化風險,什麼又是經驗風險。要了解這兩個所謂的“風險”,還得又從監督學習說起。
監督學習實際上就是一個經驗風險或者結構風險函數的最優化問題。風險函數度量平均意義下模型預測的好壞,模型每一次預測的好壞用損失函數來度量。它從假設空間F中選擇模型f作爲決策函數,對於給定的輸入X,由f(X)給出相應的輸出Y,這個輸出的預測值f(X)與真實值Y可能一致也可能不一致,用一個損失函數來度量預測錯誤的程度。損失函數記爲L(Y, f(X))。
常用的損失函數有以下幾種(基本引用自《統計學習方法》):


如此,SVM有第二種理解,即最優化+損失最小,或如@夏粉_百度所說“可從損失函數和優化算法角度看SVM,boosting,LR等算法,可能會有不同收穫”。
OK,關於更多統計學習方法的問題,請參看此文。
關於損失函數,如下文讀者評論中所述:可以看看張潼的這篇《Statistical behavior and consistency of classification methods based on convex risk minimization》。各種算法中常用的損失函數基本都具有fisher一致性,優化這些損失函數得到的分類器可以看作是後驗概率的“代理”。此外,張潼還有另外一篇論文《Statistical analysis of some multi-category large margin classification methods》,在多分類情況下margin loss的分析,這兩篇對Boosting和SVM使用的損失函數分析的很透徹。
3.4、最小二乘法
3.4.1、什麼是最小二乘法?
既然本節開始之前提到了最小二乘法,那麼下面引用《正態分佈的前世今生》裏的內容稍微簡單闡述下。
我們口頭中經常說:一般來說,平均來說。如平均來說,不吸菸的健康優於吸菸者,之所以要加“平均”二字,是因爲凡事皆有例外,總存在某個特別的人他吸菸但由於經常鍛鍊所以他的健康狀況可能會優於他身邊不吸菸的朋友。而最小二乘法的一個最簡單的例子便是算術平均。
最小二乘法(又稱最小平方法)是一種數學優化技術。它通過最小化誤差的平方和尋找數據的最佳函數匹配。利用最小二乘法可以簡便地求得未知的數據,並使得這些求得的數據與實際數據之間誤差的平方和爲最小。用函數表示爲:

勒讓德在論文中對最小二乘法的優良性做了幾點說明:
最小二乘使得誤差平方和最小,並在各個方程的誤差之間建立了一種平衡,從而防止某一個極端誤差取得支配地位
計算中只要求偏導後求解線性方程組,計算過程明確便捷
最小二乘可以導出算術平均值作爲估計值

由於算術平均是一個歷經考驗的方法,而以上的推理說明,算術平均是最小二乘的一個特例,所以從另一個角度說明了最小二乘方法的優良性,使我們對最小二乘法更加有信心。
最小二乘法發表之後很快得到了大家的認可接受,並迅速的在數據分析實踐中被廣泛使用。不過歷史上又有人把最小二乘法的發明歸功於高斯,這又是怎麼一回事呢。高斯在1809年也發表了最小二乘法,並且聲稱自己已經使用這個方法多年。高斯發明了小行星定位的數學方法,並在數據分析中使用最小二乘方法進行計算,準確的預測了穀神星的位置。
說了這麼多,貌似跟本文的主題SVM沒啥關係呀,別急,請讓我繼續闡述。本質上說,最小二乘法即是一種參數估計方法,說到參數估計,咱們得從一元線性模型說起。
3.4.2、最小二乘法的解法
什麼是一元線性模型呢? 請允許我引用這裏的內容,先來梳理下幾個基本概念:
監督學習中,如果預測的變量是離散的,我們稱其爲分類(如決策樹,支持向量機等),如果預測的變量是連續的,我們稱其爲迴歸。
迴歸分析中,如果只包括一個自變量和一個因變量,且二者的關係可用一條直線近似表示,這種迴歸分析稱爲一元線性迴歸分析。
如果迴歸分析中包括兩個或兩個以上的自變量,且因變量和自變量之間是線性關係,則稱爲多元線性迴歸分析。
對於二維空間線性是一條直線;對於三維空間線性是一個平面,對於多維空間線性是一個超平面...
對於一元線性迴歸模型, 假設從總體中獲取了n組觀察值(X1,Y1),(X2,Y2), …,(Xn,Yn)。對於平面中的這n個點,可以使用無數條曲線來擬合。要求樣本回歸函數儘可能好地擬合這組值。綜合起來看,這條直線處於樣本數據的中心位置最合理。
選擇最佳擬合曲線的標準可以確定爲:使總的擬合誤差(即總殘差)達到最小。有以下三個標準可以選擇:
用“殘差和最小”確定直線位置是一個途徑。但很快發現計算“殘差和”存在相互抵消的問題。
用“殘差絕對值和最小”確定直線位置也是一個途徑。但絕對值的計算比較麻煩。
最小二乘法的原則是以“殘差平方和最小”確定直線位置。用最小二乘法除了計算比較方便外,得到的估計量還具有優良特性。這種方法對異常值非常敏感。
最常用的是普通最小二乘法( Ordinary Least Square,OLS):所選擇的迴歸模型應該使所有觀察值的殘差平方和達到最小,即採用平方損失函數。
我們定義樣本回歸模型爲:

根據數學知識我們知道,函數的極值點爲偏導爲0的點。
解得:

這就是最小二乘法的解法,就是求得平方損失函數的極值點。自此,你看到求解最小二乘法與求解SVM問題何等相似,尤其是定義損失函數,而後通過偏導求得極值。
OK,更多請參看陳希孺院士的《數理統計學簡史》的第4章、最小二乘法。
3.5、SMO算法
在上文中,我們提到了求解對偶問題的序列最小最優化SMO算法,但並未提到其具體解法。首先看下最後懸而未決的問題:

等價於求解:

1998年,Microsoft Research的John C. Platt在論文《Sequential Minimal Optimization:A Fast Algorithm for Training Support Vector Machines》中提出針對上述問題的解法:SMO算法,它很快便成爲最快的二次規劃優化算法,特別是在針對線性SVM和數據稀疏時性能更優。
接下來,咱們便參考John C. Platt的這篇文章來看看SMO的解法是怎樣的。
3.5.1、SMO算法的推導











那麼在每次迭代中,如何更新乘子呢?引用這裏的兩張PPT說明下:


知道了如何更新乘子,那麼選取哪些乘子進行更新呢?具體選擇方法有以下兩個步驟:

綜上,SMO算法的基本思想是將Vapnik在1982年提出的Chunking方法推到極致,SMO算法每次迭代只選出兩個分量ai和aj進行調整,其它分量則保持固定不變,在得到解ai和aj之後,再用ai和aj改進其它分量。與通常的分解算法比較,儘管它可能需要更多的迭代次數,但每次迭代的計算量比較小,所以該算法表現出較好的快速收斂性,且不需要存儲核矩陣,也沒有矩陣運算。
3.5.3、SMO算法的實現
行文至此,我相信,SVM理解到了一定程度後,是的確能在腦海裏從頭至尾推導出相關公式的,最初分類函數,最大化分類間隔,max1/||w||,min1/2||w||^2,凸二次規劃,拉格朗日函數,轉化爲對偶問題,SMO算法,都爲尋找一個最優解,一個最優分類平面。一步步梳理下來,爲什麼這樣那樣,太多東西可以追究,最後實現。如下圖所示:

至於下文中將闡述的核函數則爲是爲了更好的處理非線性可分的情況,而鬆弛變量則是爲了糾正或約束少量“不安分”或脫離集體不好歸類的因子。
臺灣的林智仁教授寫了一個封裝SVM算法的libsvm庫,大家可以看看,此外這裏還有一份libsvm的註釋文檔。
除了在這篇論文《fast training of support vector machines using sequential minimal optimization》中platt給出了SMO算法的邏輯代碼之外,這裏也有一份SMO的實現代碼,大家可以看下。
3.6、SVM的應用
或許我們已經聽到過,SVM在很多諸如文本分類,圖像分類,生物序列分析和生物數據挖掘,手寫字符識別等領域有很多的應用,但或許你並沒強烈的意識到,SVM可以成功應用的領域遠遠超出現在已經在開發應用了的領域。
3.6.1、文本分類
一個文本分類系統不僅是一個自然語言處理系統,也是一個典型的模式識別系統,系統的輸入是需要進行分類處理的文本,系統的輸出則是與文本關聯的類別。由於篇幅所限,其它更具體內容本文將不再詳述。
OK,本節雖取標題爲證明SVM,但聰明的讀者們想必早已看出,其實本部分並無多少證明部分(特此致歉),怎麼辦呢?可以參閱《支持向量機導論》一書,此書精簡而有趣。本節完。