




背景:
這幾天想看灌籃高手的動漫,但是發現愛奇藝,搜狐等視頻網站只有灌籃高手標清的,2013年的重製高清版都下架不能看,好像因爲版權問題無法播放了,於是百度上搜索,在m.dm530.net/show/4154.html 上還有灌籃高手的重製高清版在線觀看,但是在線觀看不知是瀏覽器問題還是什麼,無法快進和後退,反正就各種問題,於是就想用Python把該網站的視頻直接下載到本地,這樣關鍵的問題就是要找到視頻的真實URL。
思路:
首先是想辦法先獲取第一集視頻的URL,於是使用谷歌瀏覽器打開第一集的播放地址m.dm530.net/v/4154-0-0.html ,按F12,打開Chrome DevTools,選擇network選項,去查看網絡請求的數據包,看視頻鏈接會不會出現在那裏,按文件大小進行排序後,發現有個60M的文件,如下圖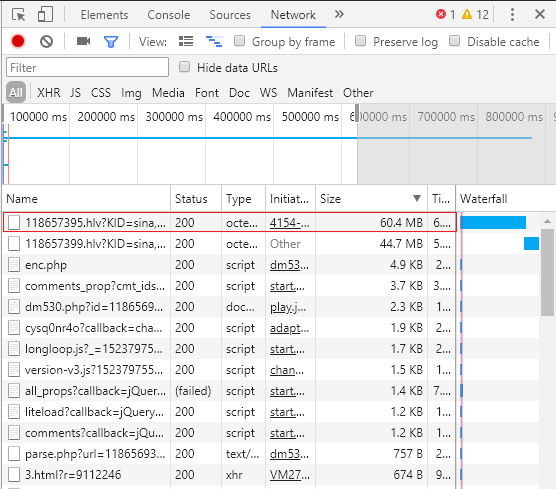
這文件很有可能就是視頻鏈接了,把鏈接複製下來
http://edge.ivideo.sina.com.cn/118657395.hlv?KID=sina,viask&Expires=1525104000&ssig=qqeUdXnlpO 發現是新浪的網址,然後去百度了hlv格式,查到了這也是新浪視頻的文件格式。這應該就是所要找的視頻鏈接,下載測試發現是能正常播放的,不過是要支持flv文件格式的播放器才行。而且下載的視頻也只有6分鐘,應該是新浪把視頻分段了。獲取了不同的視頻URL,進行比較,發現URL中 文件名稱(也就是118657395.hlv)和ssig參數會變化,域名和KID=sina,viask&Expires=1525104000這兩個參數是沒有變化的。於是只要找到文件名和ssig參數的數據就可以獲取到拼接成視頻URL了。
於是繼續在chrome瀏覽器在查看網絡請求的數據包,發現了有個XML文件,其中包含着一集視頻的所有URL地址和視頻信息。不過這獲取這XML的鏈接是有時間限制的,一會後就不能訪問了。鏈接和截圖如下所示:
https://player.s1905.com/ipsign/parse.php?url=118656937_sina&sign=98062c84b16523141973ac1e&ran=1525008246&ipsign=83753ccabbae12d1f05053a3a18ec96b1d6962fb802e7585d7101af33f76b43acd270e87&ip=自身IP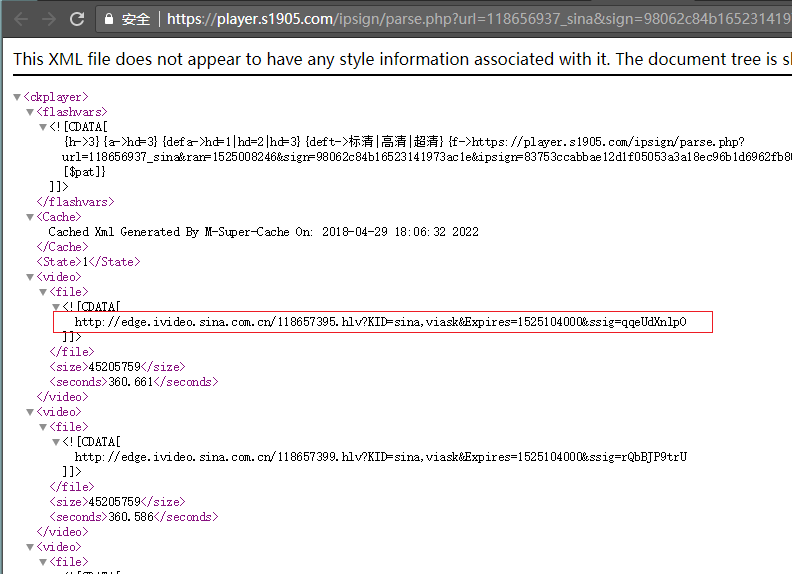
於是思考這XML鏈接是怎麼獲取的,繼續查看請求的數據包,沒發現什麼有用的信息了。。。。於是我直接查看網頁的源代碼,看看源代碼是通過什麼方式獲取該鏈接的,看到播放頁面處就只有下面的js代碼。
<script type="text/javascript" src="/playdata/58/4154.js?6195.856"></script><script>var param=getHtmlParas('.html');viewplay(param[0],param[1])</script>看來網站是通過這js代碼獲取XML鏈接的。於是繼續查看網站的js文件,看到很多加密的js文件,本來就對js不熟了,更別說混淆加密後的js了,更無從入手了。
於是繼續去Chrome DevTools中各種選項看看有沒有什麼信息遺漏的,突然看到Chrome DevTools的elements選項的HTML代碼中還有個iframe標籤,之前直接查看源代碼中是沒有顯示着iframe標籤的。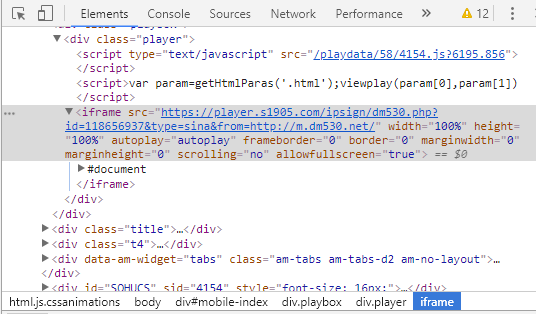
這應該是HTML的一些特性吧,我也不太瞭解,查看iframe標籤的代碼,終於發現關鍵信息了,如下圖: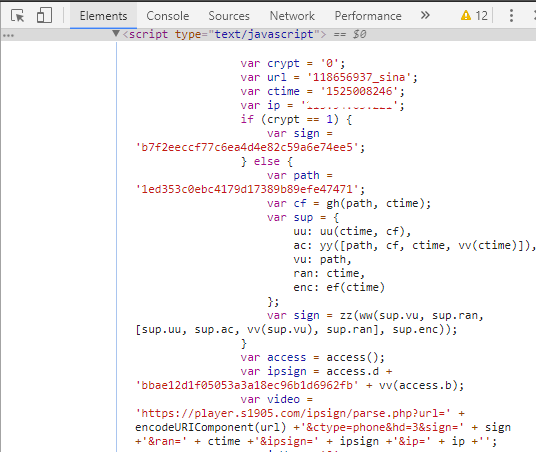
裏面js代碼的變量就是XML鏈接的各種參數
XML網址:https://player.s1905.com/ipsign/parse.php?url=118656937_sina&sign=98062c84b16523141973ac1e&ran=1525008246&ipsign=83753ccabbae12d1f05053a3a18ec96b1d6962fb802e7585d7101af33f76b43acd270e87&ip=自身IP也就是隻要獲取到iframe標籤的這些JS變量值,我們就可以獲取到獲取視頻地址的XML,從上圖中可以看到,url、ran和ip參數都已經給出來了,剩下需要獲取的就是隻有ipsign和sign這兩個參數的值了。
可是ipsign和sign這兩個變量使用的JS函數,在混淆加密的JS文件中,根本就看不出來邏輯,如下圖:
手動分析JS代碼看來是行不通的了,於是我百度下看到了些思路,還可以模擬瀏覽器運行,從而獲取JS變量值的。
查到Python可以通過selenium庫模擬真實瀏覽器去渲染JavaScript的。
代碼實現:
具體實現方式就是Python使用selenium去運行chrome瀏覽器(要下載chrome瀏覽器對應的chromedriver),返回JS變量值。因爲video變量的值比所需要的XML的網址只是多了兩個參數,所以就直接獲取video變量的值再截取成XML網址,獲取XML後,再使用正則表達式匹配視頻URL。
XML網址:https://player.s1905.com/ipsign/parse.php?url=118656937_sina&sign=98062c84b16523141973ac1e&ran=1525008246&ipsign=83753ccabbae12d1f05053a3a18ec96b1d6962fb802e7585d7101af33f76b43acd270e87&ip=自身IP
video變量:var video = 'https://player.s1905.com/ipsign/parse.php?url=' + encodeURIComponent(url) +'&ctype=phone&hd=3&sign=' + sign +'&ran=' + ctime +'&ipsign=' + ipsign +'&ip=' + ip +'';具體代碼:
# _*_ coding: utf-8 _*_
import threading
import os
import re
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import requests
import time
def getvideo(url,filename):
#設置瀏覽器選項
chrome_options = Options()
chrome_options.add_argument("--headless") #啓動Chrome 瀏覽器的***面形態
#對應的chromedriver的放置目錄,因爲我的chromedriver放進python安裝目錄的Scripts,所以可以不填
driver = webdriver.Chrome(chrome_options=chrome_options)
#瀏覽器瀏覽網址
driver.get(url)
try:
driver.switch_to.frame(0)#切換到iframe
url1 = driver.execute_script("return video") #獲取video變量值
except:
f=open('realurl.txt','a')
f.write('\n'+filename+'\n')
f.write('異常\n')
f.close()
vu=url1.replace('&ctype=phone','')#截取成XML網址,hd=3這參數是沒影響的,所以留着
driver.close() #關閉瀏覽器
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Charset': 'UTF-8,*;q=0.5',
'Accept-Encoding': 'gzip,deflate,sdch',
'Accept-Language': 'en-US,en;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0',
}
text=requests.get(vu,headers=headers)
pattern=re.compile('http://[\w|/|\.|&|?|=|,|%|:]+')#匹配視頻URL的正則表達式
url=pattern.findall(text.text)#獲取一集中所有視頻URL
#把URL寫進文本
f=open('realurl.txt','a')
f.write('\n'+filename+'\n')
f.write('\n'.join(url))
f.close()
if __name__=='__main__':
f=open('dm530.txt','r')
for line in f:
v=line.strip().split('\t')
url=v[0]
filename=v[1]
t=threading.Thread(target=getvideo,args=(url,filename))
t.start()
t.join() #t線程退出後再執行下一步
time.sleep(4)
f.close()
print('end')dm530文件通過網頁源代碼製作而成的,如下圖所示:
最後獲取出來的結果realurl.txt(因爲有些集數該網站也無法播放,所以也無法獲取到),如下圖: