




引言
InfluxDB是一款Go語言寫的時序數據庫。時序數據庫主要用於存儲基於時間序列的指標數據,例如一個Web頁面的PV、UV等指標,將其定期採集,並打上時間戳,就是一份基於時間序列的指標。時序數據庫通常用來配合前端頁面來展示一段時間的指標曲線。
爲什麼需要時序數據庫
時序數據庫較傳統的關係型數據庫以及NoSQL究竟有什麼優勢,下面會結合相關模型的特性進行分析
LSM Tree
LSM tree是基於Google的BigTable架構,數據以K-V方式存儲。
寫數據首先會插入到內存中的樹。當內存中的樹中的數據超過一定閾值時,會進行合併操作。合併操作會從左至右遍歷內存中的樹的葉子節點與磁盤中的樹的葉子節點進行合併,當被合併的數據量達到磁盤的存儲頁的大小時,會將合併後的數據持久化到磁盤,同時更新父親節點對葉子節點的指針。
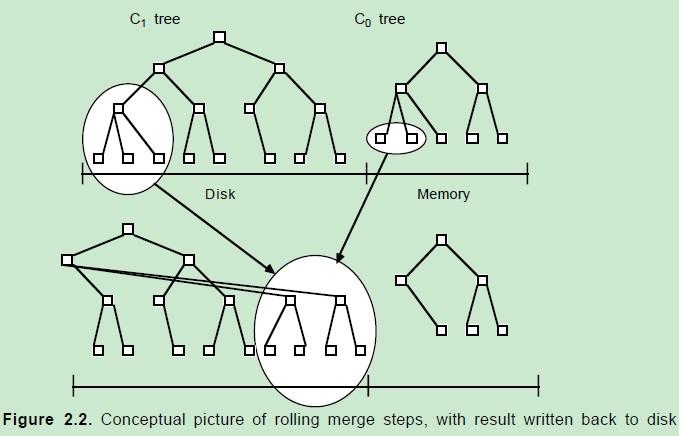
這種機制保證了寫入的效率,因爲數據會在合併後順序寫入磁盤頁。但會推遲磁盤迴寫,因此爲保障讀數據的一致性,會先在內存中查詢,如果內存中沒有,則到磁盤上查詢。
刪除數據時,在內存(C0)中查找,如果沒有,則在內存中新建一個索引,將鍵值設置刪除標記(創建墓碑),這樣後續的滾動合併操作時,再有查詢操作,就會被直接返回該鍵值不存在。 數據會在之後的Compaction當中從數據文件中刪除。
Compaction
當日志文件超過一定大小的閾值是 (默認爲 1MB):
建立一個新的memtable和日誌文件,以後的操作都是用新的memtable和日誌文件
後臺進行如下操作:
將舊的 memtable寫到SSTable中(過程爲先轉爲immtable_table,然後遍歷寫入)
廢棄舊的 memtable
刪除舊的 memtable和日誌文件
將新的SSTable加到level 0中.
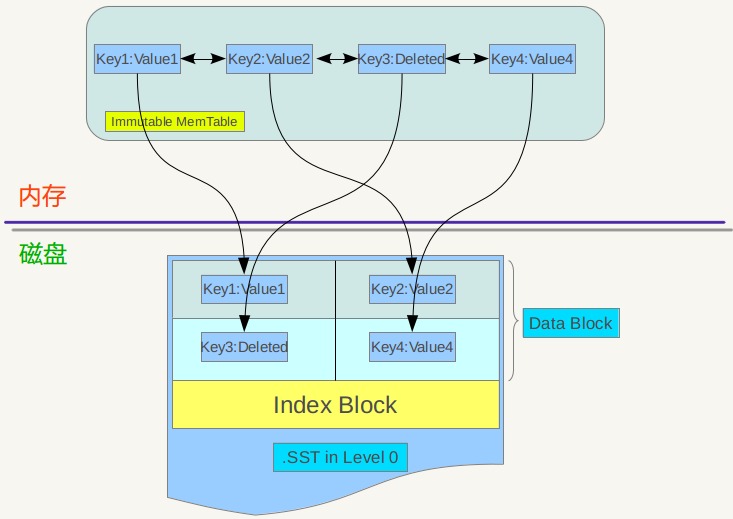
對於時序數據而言,LSM tree的讀寫效率很高。但是熱備份以及數據批量清理的效率不高。
B+ Tree
B+ Tree,很多關係型數據庫像 Berkerly DB , sqlite , mysql 數據庫都使用了B+樹算法處理索引。B+ Tree的特點是數據按照索引有序排放,犧牲一定寫入性能,保證了讀取效率。但數據量很大時(GB),查詢效率就會很低。因爲數據量越大,樹分叉就越多,遍歷時的開銷就越大。
TSM
influxdb在v0.9.5版本引入TSM引擎,該引擎修改自LSM
預寫日誌
當前日誌文件達到2MB大小後封閉,並開始寫新的日誌文件
寫數據時,日誌文件落盤(fsync)且數據索引加入內存表後返回成功。這樣的設計保證了數據的一致性。同時對寫盤的吞吐性能提出要求,建議批量提交數據(influxdb提供了批量提交的API)。日誌遵循TLV格式,並採用較精簡的數據結構,來減少寫操作的開銷。
數據文件
文件結構
對照LevelDB的結構,增加了min和max time, 基於一段時間範圍的數據提取會非常簡單
Data Block結構
Compressd block當中會存儲metric值,數據壓縮算法後面會進行詳述
Index Block結構

讀取數據
首先會根據查詢請求的時間範圍,在數據文件中進行二進制搜索,找到符合範圍的文件。之後在內存中的映射表根據查詢指標項HASH獲取ID,並通過索引找到數據塊的起始地址。之後根據數據塊及其下一數據塊的timestamp我們可以推算出需要取出多少個數據塊,最後將數據塊中的數據解壓,得到結果
更新數據
如果多個更新在同一個時間範圍內,預寫日誌會緩存起來一起更新。
刪除數據
兩階段式處理,第一階段,預寫日誌會將其持久化在日誌中,並通知索引維護內存中的墓碑. 此時查詢數據,就會返回不存在。第二階段,預寫日誌寫索引文件,會優先處理刪除,之後再處理刪除操作之後的其他插入(包括刪除的序列以及其他序列),並清除內存中的墓碑。
數據壓縮
數據壓縮的目的是爲了減少存儲空間以及降低寫磁盤的開銷
總結
influxdb的數據存儲結構實現了數據基於系列以及時間戳2個維度的有序存取。並通過壓縮數據來降低I/O開銷。在取一個系列在一定時間範圍內的數據這個場景下,能夠提高處理速度。 由於數據按時間進行歸併,對Retention操作而言,可以以數據文件爲單位進行操作,效率會比較高。