




下面介紹如何在Windows8.1上搭建hadoop2.7.2的本地模式開發環境,爲後期做mapreduce的開發做準備。
在搭建開發環境之前,首先選擇開發工具,就是大家都很熟悉的Eclipse(本人這次使用的是eclipse4.4.2版本),Eclipse提供了hadoop的插件,我們通過這個插件,就可以在eclipse中編寫mapreduce。但是,這個插件可能會隨着hadoop的版本升級或者eclipse的版本升級,而需要相應的去進行編譯。所以,在我們開發之前,學會編譯這個eclipse的hadoop插件至關重要,編譯eclipse插件使用ant工具,ant工具不在本次的介紹範圍內。
1、首先通過sourcetree獲取hadoop2x-eclipse-plugin插件。
1.1、插件地址在github上:https://github.com/winghc/hadoop2x-eclipse-plugin.git上下載
1.2、將下載的插件hadoop2x-eclipse-plugin-master.zip在本地磁盤進行解壓,解壓之後的目錄結構如下:

1.3、接着修改F:\Hadoop\eclipsechajian\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin目錄下的build.xml文件

由於網站上都是基於hadoop2.6版本進行的編譯,2.7.2版本對於build.xml需要修改如下:
找到<target name="jar" depends="compile" unless="skip.contrib">標籤,在這個element下有一堆<copy file=....>的sub-element,將其中這段<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}.jar" todir="${build.dir}/lib" verbose="true"/>更改爲
<copy file="${hadoop.home}/share/hadoop/common/lib/htrace-core-${htrace.version}-incubating.jar" todir="${build.dir}/lib" verbose="true"/>
並添加兩個新的element:
<copy file="${hadoop.home}/share/hadoop/common/lib/servlet-api-${servlet-api.version}.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.home}/share/hadoop/common/lib/commons-io-${commons-io.version}.jar" todir="${build.dir}/lib" verbose="true"/>

以上這些jar包在編譯hadoop2.7.2 eclipse插件的時候需要用到,如果不添加就會報錯,所以,我們在ant編譯之前先添加進來。
1.4、然後再找到<jar arfile="${build.dir}/hadoop-${name}-${hadoop.version}.jar" manifest="${root}/META-INF/MANIFEST.MF">標籤,把剛剛copy的包,在ant構建的時候寫到mainfest.mf文件的Bundle-ClassPath中:
lib/servlet-api-${servlet-api.version}.jar,
lib/commons-io-${commons-io.version}.jar,
並將lib/htrace-core-${htrace.version}.jar替換爲lib/htrace-core-${htrace.version}-incubating.jar

1.5、再修改\hadoop2x-eclipse-plugin\src\ivy\libraries.properties文件,這個文件配置了ant構建需要用到各個jar包的版本,以及構建hadoop的版本,由於下載的這個插件是編譯hadoop2.6.0的,所以我們需要修改以下配置,更改下列屬性和其值使其對應hadoop2.7.2和當前環境的jar包版本:
hadoop.version=2.7.2
apacheant.version=1.9.7
commons-collections.version=3.2.2
commons-httpclient.version=3.1
commons-logging.version=1.1.3
commons-io.version=2.4
slf4j-api.version=1.7.10
slf4j-log4j12.version=1.7.10
其實在ant構建的時候,會選擇本地hadoop2.7.2目錄中的jar包版本(\hadoop-2.7.2\share\hadoop\common),所以只要將版本號改成對應的版本號即可如下圖:


1.6、最後修改\hadoop2x-eclipse-plugin\ivy\libraries.properties文件,文件的的版本如上圖版本修改一樣,但是還有一個版本需要修改的就是
htrace.version的版本要改成3.1.0,htrace.version=3.1.0
1.7、然後cd到F:\Hadoop\eclipsechajian\hadoop2x-eclipse-plugin-master\src\contrib\eclipse-plugin目錄
執行以下命令:
ant jar -Dversion=2.7.2 -Declipse.home=D:\eclipse_hadoop -Dhadoop.home=F:\Hadoop\hadoop-2.7.2
解釋下這個命令:-Dversion是指這個插件的版本,Declipse.home是指eclipse的安裝目錄,-Dhadoop.home指本地文件中hadoop-2.7.2的安裝目錄。
命令執行成功之後就可以在\hadoop2x-eclipse-plugin\build\contrib\eclipse-plugin目錄下面找到
hadoop-eclipse-plugin-2.7.2.jar 包,這個包就是編譯好的eclipse hadoop2.7.2插件,把這個插件放到eclipse安裝目錄的plugins目錄下,我們就可以進入eclipse然後找到一個叫mapreduce的視圖,就可以開始嘗試編寫mapreduce程序了。
1.8、下載eclipse並配置JDK
去http://www.eclipse.org/downloads/ 下載你需要的版本,我們這裏下載的是win64位版。直接解壓到目錄中。進行簡單設置,根據你的開發需要,選擇jdk的版本


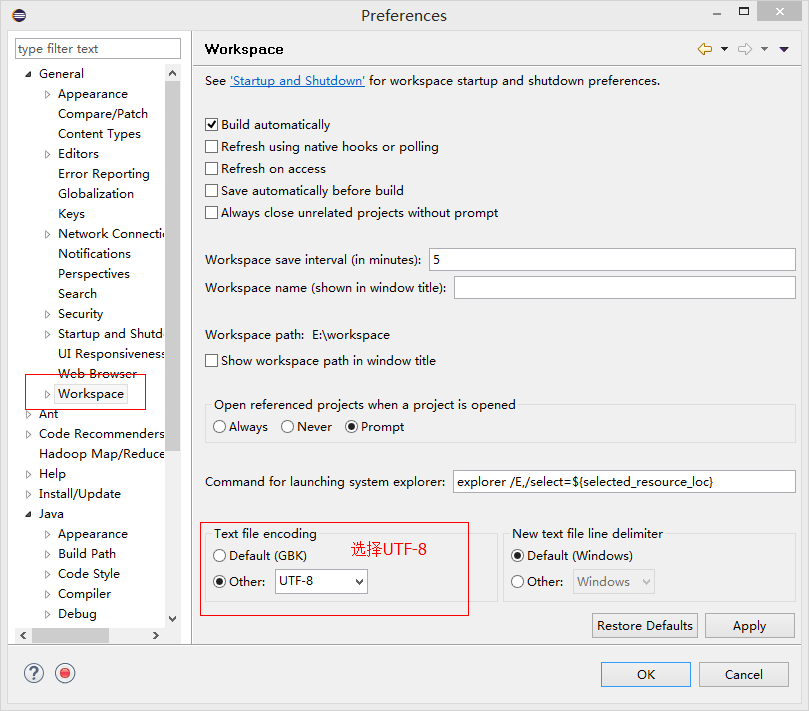
1.9、設置hadoop插件
在eclipse菜單中選擇,window - preferences,打開設置菜單

至此Eclipse開發環境搭建完成,下面將搭建hadoop的運行環境,hadoop項目是需要將程序提交到hadoop運行環境上面運行的。
2、Eclipse插件編譯好之後,就需要安裝Hadoop2.7.2
hadoop環境搭建相對麻煩,需要安裝虛擬機或者着cygwin什麼的,但是通過查官方資料和摸索,在window上搭建了本地模式,可以不需要虛擬機和cygwin依賴,而且官網明確指出cygwin已經不支持hadoop2.x。
Windows下搭建Hadoop本地模式運行環境參考:http://wiki.apache.org/hadoop/Hadoop2OnWindows
下面配置windows環境:
2.1、Java JDK :我採用的是1.8的,配置JAVA_HOME,如果默認安裝,會安裝在C:\Program Files\Java\jdk1.8.0_51。此目錄存在空格,啓動hadoop時將報錯,JAVA_HOME is incorrect ...此時需要將環境變量JAVA_HOME值修改爲:C:\Progra~1\Java\jdk1.8.0_51,Program Files可以有Progra~代替。
2.2、Hadoop 環境變量: 新建HADOOP_HOME,指向hadoop解壓目錄,如:F:\Hadoop\hadoop-2.7.2。然後在path環境變量中增加:%HADOOP_HOME%\bin;。
2.3、Hadoop 依賴庫:winutils相關,hadoop在windows上運行需要winutils支持和hadoop.dll等文件,下載地址:http://download.csdn.net/detail/fly_leopard/9503059
注意hadoop.dll等文件不要與hadoop衝突。爲了不出現依賴性錯誤可以將hadoop.dll放到c:/windows/System32下一份,然後重啓計算機。
2.4、hadoop環境測試:
起一個cmd窗口,切換到hadoop-2.7.2\bin下,執行hadoop version命令,顯示如下:

2.5、hadoop基本文件配置:hadoop配置文件位於:hadoop-2.7.2\etc\hadoop下
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:19000</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/Hadoop/hadoop-2.7.2/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/Hadoop/hadoop-2.7.2/data/dfs/datanode</value>
</property>
</configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.job.user.name</name>
<value>%USERNAME%</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.apps.stagingDir</name>
<value>/user/%USERNAME%/staging</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>local</value>
</property>
</configuration>
其中%USERNAME%爲你計算機執行hadoop的用戶名。
yarn-site.xml:
<configuration>
<property>
<name>yarn.server.resourcemanager.address</name>
<value>0.0.0.0:8020</value>
</property>
<property>
<name>yarn.server.resourcemanager.application.expiry.interval</name>
<value>60000</value>
</property>
<property>
<name>yarn.server.nodemanager.address</name>
<value>0.0.0.0:45454</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.server.nodemanager.remote-app-log-dir</name>
<value>/app-logs</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/dep/logs/userlogs</value>
</property>
<property>
<name>yarn.server.mapreduce-appmanager.attempt-listener.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.server.mapreduce-appmanager.client-service.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>-1</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>%HADOOP_CONF_DIR%,%HADOOP_HOME%/share/hadoop/common/*,%HADOOP_HOME%/share/hadoop/common/lib/*,%HADOOP_HOME%/share/hadoop/hdfs/*,%HADOOP_HOME%/share/hadoop/hdfs/lib/*,%HADOOP_HOME%/share/hadoop/mapreduce/*,%HADOOP_HOME%/share/hadoop/mapreduce/lib/*,%HADOOP_HOME%/share/hadoop/yarn/*,%HADOOP_HOME%/share/hadoop/yarn/lib/*</value>
</property>
</configuration>
其中:%HADOOP_CONF_DIR%爲hadoop的安裝路徑;yarn.nodemanager.log-dirs配置項的路徑是在你hadoop安裝路徑的跟目錄創建,例如我的hadoop是在F盤,所以該配置項的目錄就在F盤創建。
2.6、格式化系統文件:
hadoop-2.7.2/bin下執行 hdfs namenode -format
待執行完畢即可,不要重複format容易出現異常。
2.7、格式化完成後到hadoop-2.7.2/sbin下執行 start-dfs.cmd啓動hadoop
訪問:http://localhost:50070

2.8、在hadoop-2.7.2/sbin下執行start-yarn.cmd啓動yarn,訪問http://localhost:8088可查看 資源、節點管理

至此表示hadoop2.7.2運行環境搭建完成。
3、結合Eclipse創建MR項目並使用本地系統進行hadoop本地模式開發
我在者使用Eclipse開發使用的是本地文件系統,沒有使用HDFS,HDFS在完全分佈式下介紹的多,在這就不用介紹,另外使用Eclipse開發並不是很多文章介紹一定要配置DFS Locations(這個不影響開發),這個是用來查看集羣上的HDFS文件系統的(我目前是這樣理解),反正我使用這個連接本地windows8.1上啓動的hadoop(本地模式),一直沒練成功過,報下面的錯誤:
java.lang.NoClassDefFoundError: org/apache/htrace/SamplerBuilder
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:635)
at org.apache.hadoop.hdfs.DFSClient.<init>(DFSClient.java:619)
at org.apache.hadoop.hdfs.DistributedFileSystem.initialize(DistributedFileSystem.java:149)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2653)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:92)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2687)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2669)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:371)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:170)
at org.apache.hadoop.eclipse.server.HadoopServer.getDFS(HadoopServer.java:478)
at org.apache.hadoop.eclipse.dfs.DFSPath.getDFS(DFSPath.java:146)
at org.apache.hadoop.eclipse.dfs.DFSFolder.loadDFSFolderChildren(DFSFolder.java:61)
at org.apache.hadoop.eclipse.dfs.DFSFolder$1.run(DFSFolder.java:178)
at org.eclipse.core.internal.jobs.Worker.run(Worker.java:54)
這個問題目前已解決,是因爲缺少相應的插件jar包;需要將下面3個插件放入到$eclipse_home\plugins\目錄下。

好了,下面進入使用Eclipse開發hadoop的介紹
3.1、上面環境搭建完成之後,下面開始講如何進行開發,我們使用hadoop的wordcount來做測試。
創建mr項目
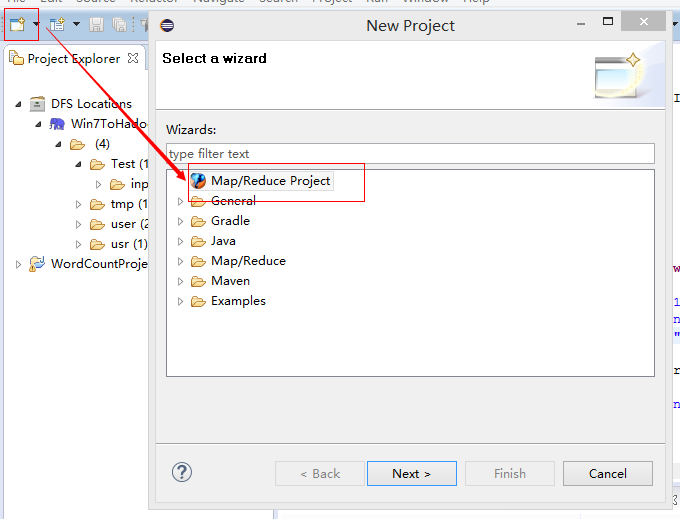
設置項目名稱
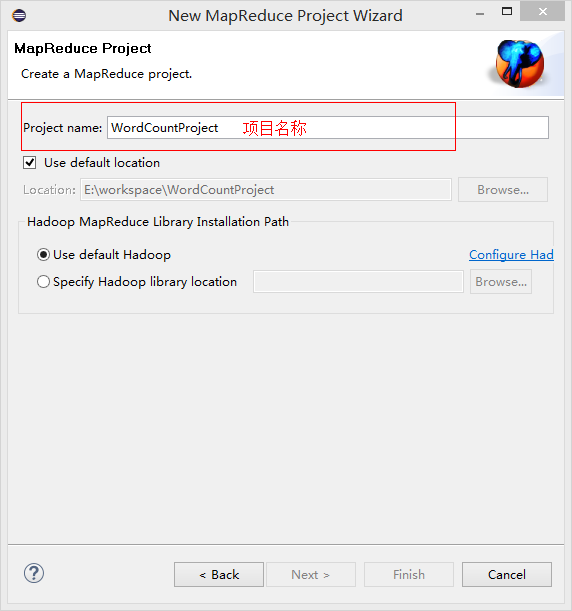
創建類

設置類屬性

創建完成後,將hadoop-2.7.2-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples目錄下的WordCount.java文件內容,copy到剛創建的文件中。
3.2接下來創建配置環境
在項目中創建一個名爲resources的Source Floder,然後將F:\Hadoop\hadoop-2.7.2\etc\hadoop下的配置文件全部copy到該目錄下。
3.3、運行WordCount程序
以上完成後,即完成開發環境配置,接下來試試運行是否成功。


上圖中紅圈標註的是重點,配置的是wordcount的輸入輸出路徑,因爲本地模式我使用的是本地文件系統而不是HDFS,所以該地方是使用的file:///而不是hdfs://(需要特別注意)。
然後點擊Run按鈕,hadoop就可運行了。
當出現下面情況,則表示運行成功:
16/09/15 22:18:37 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
16/09/15 22:18:39 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
16/09/15 22:18:39 INFO input.FileInputFormat: Total input paths to process : 2
16/09/15 22:18:40 INFO mapreduce.JobSubmitter: number of splits:2
16/09/15 22:18:41 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1473949101198_0001
16/09/15 22:18:41 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
16/09/15 22:18:41 INFO impl.YarnClientImpl: Submitted application application_1473949101198_0001
16/09/15 22:18:41 INFO mapreduce.Job: The url to track the job: http://Lenovo-PC:8088/proxy/application_1473949101198_0001/
16/09/15 22:18:41 INFO mapreduce.Job: Running job: job_1473949101198_0001
16/09/15 22:18:53 INFO mapreduce.Job: Job job_1473949101198_0001 running in uber mode : false
16/09/15 22:18:53 INFO mapreduce.Job: map 0% reduce 0%
16/09/15 22:19:03 INFO mapreduce.Job: map 100% reduce 0%
16/09/15 22:19:10 INFO mapreduce.Job: map 100% reduce 100%
16/09/15 22:19:11 INFO mapreduce.Job: Job job_1473949101198_0001 completed successfully
16/09/15 22:19:12 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=119
FILE: Number of bytes written=359444
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=194
HDFS: Number of bytes written=0
HDFS: Number of read operations=2
HDFS: Number of large read operations=0
HDFS: Number of write operations=0
Job Counters
Killed map tasks=1
Launched map tasks=2
Launched reduce tasks=1
Rack-local map tasks=2
Total time spent by all maps in occupied slots (ms)=12156
Total time spent by all reduces in occupied slots (ms)=4734
Total time spent by all map tasks (ms)=12156
Total time spent by all reduce tasks (ms)=4734
Total vcore-milliseconds taken by all map tasks=12156
Total vcore-milliseconds taken by all reduce tasks=4734
Total megabyte-milliseconds taken by all map tasks=12447744
Total megabyte-milliseconds taken by all reduce tasks=4847616
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=78
Map output materialized bytes=81
Input split bytes=194
Combine input records=8
Combine output records=6
Reduce input groups=4
Reduce shuffle bytes=81
Reduce input records=6
Reduce output records=4
Spilled Records=12
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=187
CPU time spent (ms)=1733
Physical memory (bytes) snapshot=630702080
Virtual memory (bytes) snapshot=834060288
Total committed heap usage (bytes)=484966400
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=44
File Output Format Counters
Bytes Written=43
然後在輸出路徑(運行中配置的輸出路徑)中查看運行結果:

運行當中可能出現如下問題:
1)、問題1:
16/09/15 22:12:08 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Exception in thread "main" java.net.ConnectException: Call From Lenovo-PC/192.168.1.105 to 0.0.0.0:9000 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:732)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy12.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:771)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy13.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:2108)
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1305)
at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1301)
at org.apache.hadoop.fs.FileSystem.exists(FileSystem.java:1424)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:144)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1657)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)
Caused by: java.net.ConnectException: Connection refused: no further information
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:614)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:712)
at org.apache.hadoop.ipc.Client$Connection.access$2900(Client.java:375)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1528)
at org.apache.hadoop.ipc.Client.call(Client.java:1451)
... 27 more
出現上述問題是由於項目中的core-site.xml中和本地安裝的hadoop配置文件core-site.xml中的端口不一致,請修改成一致。
2)、問題2:
16/09/15 22:14:45 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
16/09/15 22:14:48 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
16/09/15 22:14:50 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
16/09/15 22:14:52 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
16/09/15 22:14:54 INFO ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
如果出現上述問題表示yarn沒有啓動,請啓動yarn。
3)、問題3:
16/09/15 22:16:00 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
16/09/15 22:16:02 WARN mapreduce.JobResourceUploader: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
16/09/15 22:16:02 INFO input.FileInputFormat: Total input paths to process : 2
16/09/15 22:16:03 INFO mapreduce.JobSubmitter: number of splits:2
16/09/15 22:16:03 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1473948945298_0001
16/09/15 22:16:04 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
16/09/15 22:16:04 INFO impl.YarnClientImpl: Submitted application application_1473948945298_0001
16/09/15 22:16:04 INFO mapreduce.Job: The url to track the job: http://Lenovo-PC:8088/proxy/application_1473948945298_0001/
16/09/15 22:16:04 INFO mapreduce.Job: Running job: job_1473948945298_0001
16/09/15 22:16:08 INFO mapreduce.Job: Job job_1473948945298_0001 running in uber mode : false
16/09/15 22:16:08 INFO mapreduce.Job: map 0% reduce 0%
16/09/15 22:16:08 INFO mapreduce.Job: Job job_1473948945298_0001 failed with state FAILED due to: Application application_1473948945298_0001 failed 2 times due to AM Container for appattempt_1473948945298_0001_000002 exited with exitCode: -1000
For more detailed output, check application tracking page:http://Lenovo-PC:8088/cluster/app/application_1473948945298_0001Then, click on links to logs of each attempt.
Diagnostics: Could not find any valid local directory for nmPrivate/container_1473948945298_0001_02_000001.tokens
Failing this attempt. Failing the application.
16/09/15 22:16:08 INFO mapreduce.Job: Counters: 0
如果出現上述問題,表示你沒有使用管理員權限啓動hadoop,請使用管理員權限啓動hadoop。