




presto
Presto是Facebook開發的分佈式大數據SQL查詢引擎,專門進行快速數據分析。
特點:
可以將多個數據源的數據進行合併,可以跨越整個組織進行分析。
直接從HDFS讀取數據,在使用前不需要大量的ETL操作。
查詢原理:
完全基於內存的並行計算
流水線
本地化計算
動態編譯執行計劃
小心使用內存和數據結構
類BlinkDB的近似查詢
GC控制
架構圖:
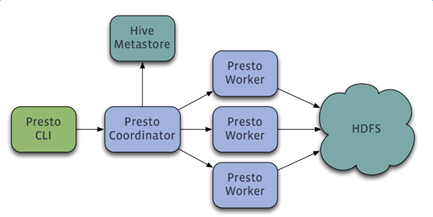
Presto實現原理和美團的使用實踐 http://tech.meituan.com/presto.html
Presto官網 http://prestodb-china.com/
l druid
Druid是廣告分析公司Metamarkets開發的一個用於大數據實時查詢和分析的分佈式實時處理系統,主要用於廣告分析,互聯網廣告系統監控、度量和網絡監控。
特點:
快速的交互式查詢——Druid的低延遲數據攝取架構允許事件在它們創建後毫秒內可被查詢到。
高可用性——Druid的數據在系統更新時依然可用,規模的擴大和縮小都不會造成數據丟失;
可擴展——Druid已實現每天能夠處理數十億事件和TB級數據。
爲分析而設計——Druid是爲OLAP工作流的探索性分析而構建,它支持各種過濾、聚合和查詢。
應用場景:
需要實時查詢分析時;
具有大量數據時,如每天數億事件的新增、每天數10T數據的增加;
需要一個高可用、高容錯、高性能數據庫時。
需要交互式聚合和快速探究大量數據時
架構圖:

Druid官網 http://druid.io/druid.html
Druid:一個用於大數據實時處理的開源分佈式系統
http://www.infoq.com/cn/news/2015/04/druid-data/
Druid創始人Eric Tschetter詳解開源實時大數據分析系統Druid》
http://www.csdn.net/article/2014-10-30/2822381
l apache kylin
Apache Kylin最初由eBay開發並貢獻至開源社區的分佈式分析引擎,提供
Hadoop之上的SQL查詢接口及多維分析(OLAP)能力以支持超大規模數據。
特點:
用戶爲百億以上數據集定義數據模型並構建立方體
亞秒級的查詢速度,同時支持高併發
爲Hadoop提供標準SQL支持大部分查詢功能
提供與BI工具,如Tableau的整合能力
友好的web界面以管理,監控和使用立方體
項目及立方體級別的訪問控制安全
架構圖:
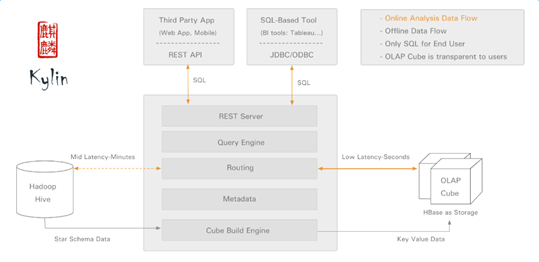
kylin官網 http://kylin.apache.org/cn/
l 系統對比
性能對比:
Presto,Kylin1.3,Kylin1.5和Druid
典型的五個查詢場景:一個事實表的過濾和聚合;五張表全關聯之後的查詢;兩個Count Dstinct指標和兩個Sum指標;後面兩個查詢包含8~10個的維度過濾。
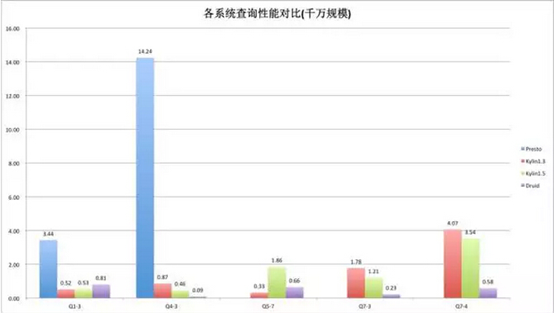
圖-千萬規模的級別
總結:可以看到不管Presto跟Kylin還是Druid相比差的都比較多,差一個數量級。從後面的兩個查詢上可以看到,在千萬規模的級別,和Druid還是有比較大的差距。這主要和它們的實現模式相關,因爲Druid會把所有的數據預處理完以後都加載到內存裏,在做一些小數據量聚合的時候,可以達到非常快的速度;但是Kylin要到HBase上讀,相對來說它的性能要差一些,但也完全能滿足需求。
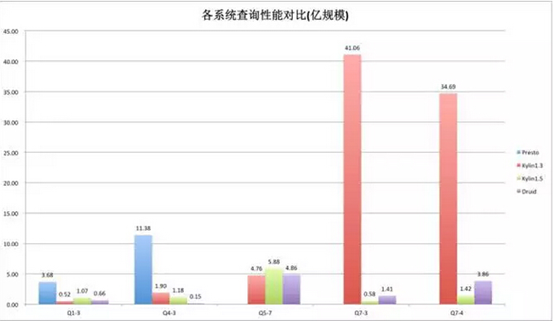
圖-億規模的級別
總結:在億級的規模上情況又有了變化,還是看後面兩個查詢,Kylin1.3基本上是一個線性的增長,這個數據已經變得比較難看了,這是由於Kylin1.3在掃描HBase的時候是串行方式,但是Kylin1.5反而會有更好的表現,這是因爲Kylin1.5引入了HBase並行Scan,大大降低了掃描的時間。Kylin1.5的數據會shard到不同的region上,在千萬量級上數據量還比較小,沒有明顯的體現,但是上億以後,隨着數據量上升,region也變多了,反而能把併發度提上去。所以在這裏可以看到Kylin1.5表現會更好。這裏也可以看出,在數據量成數量級上升後,Kylin表現的更加穩定,在不同規模數據集上依然可以保持不錯的查詢性能。而Druid隨着數據量的增長性能損失也成倍增長。
系統的易用性:
Druid一個集羣的角色是非常多的,如果要把這個系統用起來的話,可能光搭這個環境,起這些服務都要很長的時間。這個對於我們做平臺來講,實際上是一個比較痛的事。不管是在部署,還是加監控的時候,成本都是相對比較高的。另外一個查詢接口方面,我們最熟悉或者最標準,最好用的當然是標準SQL的接口。ES、Druid這些系統原來都不支持SQL,當然現在也有一些插件,但是在功能的完備性和數據的效率上都不如原生的支持。
數據成本:
在查詢成本上,Presto是最好的,因爲幾乎不需要做什麼特殊的處理,基本上Hive能讀的數據Presto也都能讀,所以這個成本非常低。Druid和Kylin的成本相對較高,因爲都需要提前的預計算,尤其是Kylin如果維度數特別多,而且不做特別優化的話,數據存儲會比較耗資源。
Kylin優勢:
第一,性能非常穩定。因爲Kylin依賴的所有服務,比如Hive、HBase都是非常成熟的,Kylin本身的邏輯並不複雜,所以穩定性有一個很好的保證。
第二,易用。首先是外圍的服務,不管是Hive還是HBase,只要大家用Hadoop系統的話基本都有了,不需要額外工作。在部署運維和使用成本上來講,都是比較低的。其次,有一個公共的Web頁面來做模型的配置。相比之下Druid現在還是基於配置文件來做。這裏就有一個問題,配置文件一般都是平臺方或者管理員來管理的,沒辦法把這個配置系統開放出去,這樣在溝通成本和響應效率上都不夠理想。
第三,活躍開放的社區和熱心的核心開發者團隊,社區裏討論非常開放,大家可以提自己的意見及patch,修復bug以及提交新的功能等。核心團隊都是中國人,這是Apache所有項目裏唯一中國人爲主的頂級項目,社區非常活躍和熱心,有非常多的中國工程師。