标 题: Reversing.Microsoft.Visual.C++.Part.CN
翻 译: buddhaluo
时 间: 2006-12-17 21:55
链 接: http://bbs.pediy.com/showthread.php?threadid=36539
详细信息:
Reversing MS VC++ Part II: Classes, Methods and RTTI
摘要
MS VC++ 是Win32平台上最广泛使用的编译器,因此熟悉它的内部工作机制对于Win32逆向爱好者非常重要。能够理解编译器生成的附加(glue)代码有助于快速理解程序员写的实际代码。同样也有助于恢复程序的高级结构。
在Part II中,我将讲到MSVC是如何实现C++的,包括类的布局,虚函数,RTTI。假设你已经熟悉C++基本知识和汇编语言。
基本的类布局
为了解释下面的内容,让我们看看这个简单例子:
class A
{
int a1;
public:
virtual int A_virt1();
virtual int A_virt2();
static void A_static1();
void A_simple1();
};
class B
{
int b1;
int b2;
public:
virtual int B_virt1();
virtual int B_virt2();
};
class C: public A, public B
{
int c1;
public:
virtual int A_virt2();
virtual int B_virt2();
};
多数情形下,MSVC的类按如下格局分布:
Ÿ 指向虚函数表的指针(_vtable_或_vftable_),不过它只在类包括虚函数,以及不能从基类复用合适的函数表时才会被添加。
Ÿ 基类。
Ÿ 函数成员。
虚函数表由虚函数的地址组成,表中函数地址的顺序和它们第一次出现的顺序(即在类定义的顺序)一致。若有重载的函数,则替换掉基类函数的地址。
因此,上面三个类的布局看起来象这样:
class A size(8):
+---
0 | {vfptr}
4 | a1
+---
A's vftable:
0 | &A::A_virt1
4 | &A::A_virt2
class B size(12):
+---
0 | {vfptr}
4 | b1
8 | b2
+---
B's vftable:
0 | &B::B_virt1
4 | &B::B_virt2
class C size(24):
+---
| +--- (base class A)
0 | | {vfptr}
4 | | a1
| +---
| +--- (base class B)
8 | | {vfptr}
12 | | b1
16 | | b2
| +---
20 | c1
+---
C's vftable for A:
0 | &A::A_virt1
4 | &C::A_virt2
C's vftable for B:
0 | &B::B_virt1
4 | &C::B_virt2
上面的图表是由VC8编译器使用一个未公开的参数生成。为了看到这样的类布局,使用编译参数 –d1 reportSingleClassLayout,可以输出单个类的布局。-d1 reportAllClassLayout可以输出全部类的布局(包括内部的CRT类)。这些内容都被输出到stdout(标准输出)。
正如你看到的,C有两个虚函数表vftables,因为它从两个都有虚函数的类继承。C::A_virt2的地址替换了A::A_virt2在类C虚函数表的地址,类似的,C::B_virt2替换了B::B_virt2。
调用惯例和类方法
MSVC中所有的类方法都默认使用_thiscall_调用惯例。类实例的地址(_this_指针)作为隐含参数传到ecx寄存器。在函数体中,编译器通常立刻用其它寄存器(如esi或ed),或栈中变量来指代。以后对类成员的引用都通过这个寄存器或栈变量。然而,在实现COM类时,则使用_stdcall_调用习惯。下文是对各种类型的类方法的一个概述。
1) 静态方法
调用静态方法不需要类的实例,所以它们和普通函数一样的工作原理。没有_this_指针传入。因此也就不可能可靠的分辨静态方法和简单的普通函数。例如:
A::A_static1();
call A::A_static1
2) 简单方法
简单方法需要一个类实例,_this_指针隐式的作为第一个参数传入,通常使用_thiscall_调用惯例,例如通过_ecx_寄存器。当基类对象没有分配在派生类对象的开始处,在调用函数前,_this_指针需要被调整到指向基类子对象的实际开始位置。例如:
;pC->A_simple1(1);
;esi = pC
push 1
mov ecx, esi
call A::A_simple1
;pC->B_simple1(2,3);
;esi = pC
lea edi, [esi+8] ;adjust this
push 3
push 2
mov ecx, edi
call B::B_simple1
正如你看到的,在调用B的方法前,_this_指针被调整到指向B的子对象。
3) 虚方法(虚函数)
为了调用虚函数,编译器首先需要从_vftable_取得函数地址,然后就像调用简单方法一样(例如,传入_this_指针作为隐含参数)。例如:
;pC->A_virt2()
;esi = pC
mov eax, [esi] ;fetch virtual table pointer
mov ecx, esi
call [eax+4] ;call second virtual method
;pC->B_virt1()
;edi = pC
lea edi, [esi+8] ;adjust this pointer
mov eax, [edi] ;fetch virtual table pointer
mov ecx, edi
call [eax] ;call first virtual method
4) 构造函数和析构函数
构造函数和析构函数类似于简单方法,它们取得隐式的_this_指针(例如,在_thiscall_调用惯例下通过ecx寄存器)。虽然形式上构造函数没有返回值,但它在eax中返回_this_指针。
RTTI实现
RTTI(Run-Time Type Identification)运行时类型识别是由编译器生成的特殊信息,用于支持像dynamic_cast<>和typeid()这样的C++运算符,以及C++异常。基于这个本质,RTTI只为多态类生成,例如带虚函数的类。
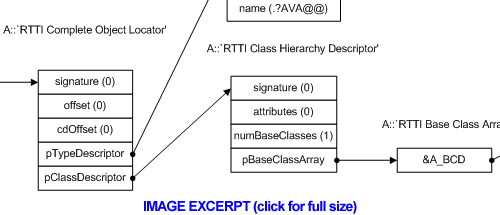
MSVC编译器在vftable前设置了一个指针,指向叫做“Complete Object Locator”(完整对象定位器)的结构。这样称呼是因为它允许编译器从特定的vftable指针(因为一个类可能有若干vftable)找到完整对象的位置。COL就像如下定义:
struct RTTICompleteObjectLocator
{
DWORD signature; //always zero ?
DWORD offset; //offset of this vtable in the complete class
DWORD cdOffset; //constructor displacement offset
struct TypeDescriptor* pTypeDescriptor; //TypeDescriptor of the complete class
struct RTTIClassHierarchyDescriptor* pClassDescriptor; //describes inheritance hierarchy
};
类层次描述符描述了类的继承层次。对于一个类,所有COL共享一个。
struct RTTIClassHierarchyDescriptor
{
DWORD signature; //always zero?
DWORD attributes; //bit 0 set = multiple inheritance, bit 1 set = virtual inheritance
DWORD numBaseClasses; //number of classes in pBaseClassArray
struct RTTIBaseClassArray* pBaseClassArray;
};
基类数组描述了所有基类,幷包含在执行_dynamic_cast_过程中编译器是否允许强制转换派生类到这些基类的信息。基类描述符中每一项都包含如下结构:
struct RTTIBaseClassDescriptor
{
struct TypeDescriptor* pTypeDescriptor; //type descriptor of the class
DWORD numContainedBases; //number of nested classes following in the Base Class Array
struct PMD where; //pointer-to-member displacement info
DWORD attributes; //flags, usually 0
};
struct PMD
{
int mdisp; //member displacement
int pdisp; //vbtable displacement
int vdisp; //displacement inside vbtable
};
PMD描述了一个基类如何放置在完整类中。在简单的继承体系中,它位于从整个对象起始位置的一个固定偏移处,这个偏移量就是_mdisp_。如果是一个虚基类,那需要从vbtable中取得一个额外的偏移量加上。从派生类到基类调整_this_指针的伪码如下:
//char* pThis; struct PMD pmd;
pThis+=pmd.mdisp;
if (pmd.pdisp!=-1)
{
char *vbtable = pThis+pmd.pdisp;
pThis += *(int*)(vbtable+pmd.vdisp);
}
例如,我们的三个类的RTTI层次关系是:
![]()
RTTI hierarchy for our example classes
提取信息
1) RTTI
如果存在,RTTI对于逆向工作来说是无价的信息。从RTTI,有可能恢复类的名字,继承层次,有时候也能恢复部分的类布局。我的RTTI扫描器脚本可以显示大多数此类信息。(参考附录I)
2) 静态和全局初始化例程(initializer)
全局和静态对象需要在main主程序开始前初始化。MSVC通过生成初始化例程函数(funclet)来实现,并把这些函数地址放入一个表中,当_cinit初始化CRT时,会调用它们。这个表通常位于.data段的开始。一个典型的初始化例程如下:
_init_gA1:
mov ecx, offset _gA1
call A::A()
push offset _term_gA1
call _atexit
pop ecx
retn
_term_gA1:
mov ecx, offset _gA1
call A::~A()
retn
从这个表我们可以找到:
· 全局/静态对象的地址
· 它们的构造函数
· 它们的析构函数
还可以参考MSVC _#pragma_directive_init_seg_[5]。
3) Unwind Funclets
若在函数中创建了自动类型的对象,VC++编译器会自动生成异常处理代码以确保在异常发生时会删除这些对象。请参看Part I以了解对C++异常实现的细节。一个典型的unwind funclet在栈上销毁一个对象的过程是:
unwind_1tobase: ; state 1 -> -1
lea ecx, [ebp+a1]
jmp A::~A()
通过在函数体中寻找相反的状态变化,或者是在第一次访问相同的栈中变量时,我们也可以找到构造函数。
lea ecx, [ebp+a1]
call A::A()
mov [ebp+__$EHRec$.state], 1
对于由new创建的对象,unwind funclet确保了万一构造失败也能删除分配的内存:
unwind_0tobase: ; state 0 -> -1
mov eax, [ebp+pA1]
push eax
call operator delete(void *)
pop ecx
retn
在函数体中:
;A* pA1 = new A();
push
call operator new(uint)
add esp, 4
mov [ebp+pA1], eax
test eax, eax
mov [ebp+__$EHRec$.state], 0; state 0: memory allocated but object is not yet constructed
jz short @@new_failed
mov ecx, eax
call A::A()
mov esi, eax
jmp short @@constructed_ok
@@new_failed:
xor esi, esi
@@constructed_ok:
mov [esp+14h+__$EHRec$.state], -1
;state -1: either object was constructed successfully or memory allocation failed
;in both cases further memory management is done by the programmer
另一种类型的unwind funclets用于构造函数和析构函数中。它确保了万一发生异常时删除类成员。这时候,funclets要使用保存在一个栈变量的_this_指针,
unwind_2to1:
mov ecx, [ebp+_this] ; state 2 -> 1
add ecx, 4Ch
jmp B1::~B1
这是funclet析构类型B1位于偏移4Ch处一个类成员的代码。从这里我们可以找到:
· 栈变量代表了C++对象或者指向用new分配的对象的指针
· 它们的构造函数
· 它们的析构函数
· 由new创建的对象的大小
4) 构造/析构函数的递归调用
规则很简单:构造函数调用其他的构造函数(其他基类和成员变量的构造函数),析构函数调用其它的析构函数。一个典型的构造函数按下列顺序执行:
· 调用基类构造函数
· 调用复杂的类成员的构造函数
· 若类有虚函数,初始化vfptr
· 执行当前的构造函数代码(即由程序员写得构造代码)
典型的析构函数几乎按照反序执行:
· 若有虚函数,初始化vfptr
· 执行当前的析构函数代码
· 调用复杂类成员的析构函数
· 调用基类的析构函数
MSVC生成的析构函数另一个独特的特征是它们的_state_变量通常初始化为最大值,每次析构一个子对象就减一,这样使得识别它们更容易。要注意简单的构造/析构函数经常被MSVC内联(inline)。那就是为什么你经常看到vftable指针在同一个函数中被不同指针重复的调用。
5) 数组的构造和析构
MSVC使用一个辅助函数来构造和析构数组。思考下面的代码:
A* pA = new A[n];
delete [] pA
翻译成下面的伪码:
array = new char(sizeof(A)*n+sizeof(int))
if (array)
{
*(int*)array=n; //store array size in the beginning
'eh vector constructor iterator'(array+sizeof(int),sizeof(A),count,&A::A,&A::~A);
}
pA = array;
'eh vector destructor iterator'(pA,sizeof(A),count,&A::~A);
如果A有一个vftable,当删除数组时,相应的会以调用一个删除析构函数的向量来替代:
;pA->'vector deleting destructor'(3);
mov ecx, pA
push 3 ; flags: 0x2=deleting an array, 0x1=free the memory
call A::'vector deleting destructor'
若A的析构函数是虚函数,则按照调虚函数的方式调用:
mov ecx, pA
push 3
mov eax, [ecx] ;fetch vtable pointer
call [eax] ;call deleting destructor
因此,从向量构造/析构函数叠代子调用我们可以知道:
· 对象数组的地址
· 它们的构造函数
· 它们的析构函数
· 类的大小
6) 删除析构函数
当类有虚析构函数时,编译器生成一个辅助函数来删除它。其目的是当析构一个类时确保_delete_操作符被调用。删除析构函数的伪码如下:
virtual void * A::'scalar deleting destructor'(uint flags)
{
this->~A();
if (flags&1) A::operator delete(this);
};
这个函数的地址被放入vftable替换析构函数地址。通过这种方式,如果另外一个类覆盖了这个虚析构函数,那么它的_delete_将被调用。然而实际代码中_delete_几乎不会被覆盖,所以你通常只看到调用默认的delete()。有时候,编译器也生成一个删除析构函数向量,就像下面一样:
virtual void * A::'vector deleting destructor'(uint flags)
{
if (flags&2) //destructing a vector
{
array = ((int*)this)-1; //array size is stored just before the this pointer
count = array[0];
'eh vector destructor iterator'(this,sizeof(A),count,A::~A);
if (flags&1) A::operator delete(array);
}
else {
this->~A();
if (flags&1) A::operator delete(this);
}
};
我跳过了有虚基类的类的大部分实现细节,因为它们使得事情更复杂了,而且在现实生活中很少用到。请参考Jan Gray写的文章[1]。它已经很详尽了,只是用匈牙利命名法有点头痛。文章[2]描述了一个MSVC实现虚继承的实现。更多细节还可以看MS专利[3]。