




|
那麼,有什麼方法可以不用比較就能排出順序呢?藉助Hash表的思想,多數人都能想出這樣一種排序算法來。 我們假設給出的數字都在一定範圍中,那麼我們就可以開一個範圍相同的數組,記錄這個數字是否出現過。由於數字有可能有重複,因此Hash表的概念需要擴展,我們需要把數組類型改成整型,用來表示每個數出現的次數。 看這樣一個例子,假如我們要對數列3 1 4 1 5 9 2 6 5 3 5 9進行排序。由於給定數字每一個都小於10,因此我們開一個0到9的整型數組T[i],記錄每一個數出現了幾次。讀到一個數字x,就把對應的T[x]加一。 A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9 +---+---+---+---+---+---+---+---+---+---+ 數字 i: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | +---+---+---+---+---+---+---+---+---+---+ 出現次數T[i]: | 0 | 2 | 1 | 2 | 1 | 3 | 1 | 0 | 0 | 2 | +---+---+---+---+---+---+---+---+---+---+ 最後,我們用一個指針從前往後掃描一遍,按照次序輸出0到9,每個數出現了幾次就輸出幾個。假如給定的數是n個大小不超過m的自然數,顯然這個算法的複雜度是O(m+n)的。 我曾經以爲,這就是線性時間排序了。後來我發現我錯了。再後來,我發現我曾犯的錯誤是一個普遍的錯誤。很多人都以爲上面的這個算法就是傳說中的計數排序。 問題出在哪裏了?爲什麼它不是線性時間的排序算法?原因是,這個算法根本不是排序算法,它根本沒有對原數據進行排序。 問題一:爲什麼說上述算法沒有對數據進行排序? STOP! You should think for a while. 我們班有很多MM。和身高相差太遠的MM在一起肯定很彆扭,接個吻都要彎腰才行(小貓矮 死了)。爲此,我希望給我們班的MM的身高排序。我們班MM的身高,再離譜也沒有超過2米的,這很適合用我們剛纔的算法。我們在黑板上畫一個100到 200的數組,MM依次自曝身高,我負責畫“正”字統計人數。統計出來了,從小到大依次爲141, 143, 143, 147, 152, 153, …。這算哪門子排序?就一排數字對我有什麼用,我要知道的是哪個MM有多高。我們僅僅把元素的屬性值從小到大列了出來,但我們沒有對元素本身進行排序。也 就是說,我們需要知道輸出結果的每個數值對應原數據的哪一個元素。下文提到的“排序算法的穩定性”也和屬性值與實際元素的區別有關。 問題二:怎樣將線性時間排序後的輸出結果還原爲原數據中的元素? STOP! You should think for a while. 同樣藉助Hash表的思想,我們立即想到了類似於開散列的方法。我們用鏈表把屬性值相同的元素串起來,掛在對應的T[i]上。每次讀到一個數,在增加T [i]的同時我們把這個元素放進T[i]延伸出去的鏈表裏。這樣,輸出結果時我們可以方便地獲得原數據中的所有屬性值爲i的元素。 A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9 +---+---+---+---+---+---+---+---+---+---+ 數字 i: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | +---+---+---+---+---+---+---+---+---+---+ 出現次數T[i]: | 0 | 2 | 1 | 2 | 1 | 3 | 1 | 0 | 0 | 2 | +---+o--+-o-+-o-+-o-+-o-+--o+---+---+-o-+ | | | | | | | +--+ +-+ | | +-+ +---+ | | | A[1] | | | A[6] A[2] A[7] | A[3] A[5] A[8] | | | | A[12] A[4] A[10] A[9] | A[11] 形象地說,我們在地上擺10個桶,每個桶編一個號,然後把數據分門別類放在自己所屬的桶裏。這種排序算法叫做桶式排序(Bucket Sort)。本文最後你將看到桶式排序的另一個用途。 鏈表寫起來比較麻煩,一般我們不使用它。我們有更簡單的方法。 問題三:同樣是輸出元素本身,你能想出不用鏈表的其它算法麼? STOP! You should think for a while. A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9 +---+---+---+---+---+---+---+---+---+---+ 數字 i: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | +---+---+---+---+---+---+---+---+---+---+ 出現次數T[i]: | 0 | 2 | 1 | 2 | 1 | 3 | 1 | 0 | 0 | 2 | +---+---+---+---+---+---+---+---+---+---+ 修改後的T[i]: | 0 | 2 | 3 | 5 | 6 | 9 | 10| 10| 10| 12| +---+---+---+---+---+---+---+---+---+---+ 所有數都讀入後,我們修改T[i]數組的值,使得T[i]表示數字i可能的排名的最大值。比如,1最差排名第二,3最遠可以排到第五。T數組的最後一個數應該等於輸入數據的數字個數。修改T數組的操作可以用一次線性的掃描累加完成。 我們還需要準備一個輸出數組。然後,我們從後往前掃描A數組,依照T數組的指示依次把原數據的元素直接放到輸出數組中,同時T[i]的值減一。之所以從後 往前掃描A數組,是因爲這樣輸出結果纔是穩定的。我們說一個排序算法是穩定的(Stable),當算法滿足這樣的性質:屬性值相同的元素,排序後前後位置 不變,本來在前面的現在仍然在前面。不要覺得排序算法是否具有穩定性似乎關係不大,排序的穩定性在下文的某個問題中將變得非常重要。你可以倒回去看看前面 說的七種排序算法哪些是穩定的。 例子中,A數組最後一個數9所對應的T[9]=12,我們直接把9放在待輸出序列中的第12個位置,然後T[9]變成11(這樣下一次再出現9時就應該放在第11位)。 A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 9 <-- T[i]= 0, 2, 3, 5, 6, 9, 10, 10, 10, 11 Ans = _ _ _ _ _ _ _ _ _ _ _ 9 接下來的幾步如下: A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5 <-- T[i]= 0, 2, 3, 5, 6, 8, 10, 10, 10, 11 Ans = _ _ _ _ _ _ _ _ 5 _ _ 9 A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5, 3 <-- T[i]= 0, 2, 3, 4, 6, 8, 10, 10, 10, 11 Ans = _ _ _ _ 3 _ _ _ 5 _ _ 9 A[]= 3, 1, 4, 1, 5, 9, 2, 6, 5 <-- T[i]= 0, 2, 3, 4, 6, 7, 10, 10, 10, 11 Ans = _ _ _ _ 3 _ _ 5 5 _ _ 9 這種算法叫做計數排序(Counting Sort)。正確性和複雜度都是顯然的。 問題四:給定數的數據範圍大了該怎麼辦? STOP! You should think for a while. 前面的算法只有在數據的範圍不大時纔可行,如果給定的數在長整範圍內的話,這個算法是不可行的,因爲你開不下這麼大的數組。Radix排序(Radix Sort)解決了這個難題。 昨天我沒事翻了一下初中(9班)時的同學錄,回憶了一下過去。我把比較感興趣的MM的生日列在下面(絕對真實)。如果列表中的哪個MM有幸看到了這篇日誌(幾乎不可能),左邊的Support欄有我的電子聯繫方式,我想知道你們怎麼樣了。排名不分先後。
這就是我的數據了。現在,我要給這些數排序。假如我的電腦只能開出0..99的數組,那計數排序算法最多對兩位數進行排序。我就把 每個八位數兩位兩位地分成四段(圖1),分別進行四次計數排序。地球人都知道月份相同時應該看哪一日,因此我們看月份的大小時應該事先保證日已經有序。換 句話說,我們先對“最不重要”的部分進行排序。我們先對所有數的最後兩位進行一次計數排序(圖2)。注意觀察1月26號的MM和4月26號的MM,本次排 序中它們的屬性值相同,由於計數排序是穩定的,因此4月份那個排完後依然在1月份那個的前頭。接下來我們對百位和千位進行排序(圖3)。你可以看到兩個 26日的MM在這一次排序中分出了大小,而月份相同的MM依然保持日數有序(因爲計數排序是穩定的)。最後我們對年份排序(圖4),完成整個算法。大家都 是跨世紀的好兒童,因此沒有圖5了。 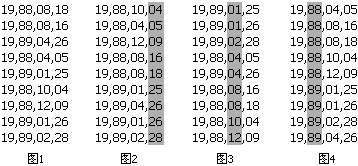 這種算法顯然是正確的。它的複雜度一般寫成O(d*(n+m)),其中n表示n個數,m是我開的數組大小(本例中m=100),d是一個常數因子(本例中d=4)。我們認爲它也是線性的。 問題五:這樣的排序方法還有什麼致命的缺陷? STOP! You should think for a while. 即使數據有30位,我們也可以用d=5或6的Radix算法進行排序。但,要是給定的數據有無窮多位怎麼辦?有人說,這可能麼。這是可能的,比如給定的數據是小數(更準確地說,實數)。基於比較的排序可以區分355/113和π哪個大,但你不知道Radix排序需要精確到哪一位。這下慘了,實數的出現把貌似高科技的線性時間排序打回了農業時代。這時,桶排序再度出山,挽救了線性時間排序悲慘的命運。 問題六:如何對實數進行線性時間排序? STOP! You should think for a while. 我們把問題簡化一下,給出的所有數都是0到1之間的小數。如果不是,也可以把所有數同時除以一個大整數從而轉化爲這種形式。我們依然設立若干個桶,比如, 以小數點後面一位數爲依據對所有數進行劃分。我們仍然用鏈表把同一類的數串在一起,不同的是,每一個鏈表都是有序的。也就是說,每一次讀到一個新的數都要 進行一次插入排序。看我們的例子: A[]= 0.12345, 0.111, 0.618, 0.9, 0.99999 +---+---+---+---+---+---+---+---+---+---+ 十分位: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | +---+-o-+---+---+---+---+-o-+---+---+-o-+ | | | A[2]=0.111 A[3]=0.618 A[4]=0.9 | | A[1]=0.12345 A[5]=0.99999 假如再下一個讀入的數是0.122222,這個數需要插入到十分位爲1的那個鏈表裏適當的位置。我們需要遍歷該鏈表直到找到第一個比0.122222大的 數,在例子中則應該插入到鏈表中A[2]和A[1]之間。最後,我們按順序遍歷所有鏈表,依次輸出每個鏈表中的每個數。 這個算法顯然是正確的,但複雜度顯然不是線性。事實上,這種算法最壞情況下是O(n^2)的,因爲當所有數的十分位都相同時算法就是一個插入排序。和原來一樣,我們下面要計算算法的平均時間複雜度,我們希望這種算法的平均複雜度是線性的。 這次算平均複雜度我們用最笨的辦法。我們將算出所有可能出現的情況的總時間複雜度,除以總的情況數,得到平均的複雜度是多少。 每個數都可能屬於10個桶中的一個,n個數總的情況有10^n種。這個值是我們龐大的算式的分母部分。如果一個桶裏有K個元素,那麼只與這個桶有關的操作 有O(K^2)次,它就是一次插入排序的操作次數。下面計算,在10^n種情況中,K0=1有多少種情況。K0=1表示,n個數中只有一個數在0號桶,其 餘n-1個數的十分位就只能在1到9中選擇。那麼K0=1的情況有C(n,1)*9^(n-1),而每個K0=1的情況在0號桶中將產生1^2的複雜度。 類似地,Ki=p的情況數爲C(n,p)*9^(n-p),複雜度總計爲C(n,p)*9^(n-p)*p^2。枚舉所有K的下標和p值,累加起來,這個 算式大家應該能寫出來了,但是這個……怎麼算啊。別怕,我們是搞計算機的,拿出點和MO不一樣的東西來。於是,Mathematica 5.0隆重登場,我做數學作業全靠它。它將幫我們化簡這個複雜的式子。 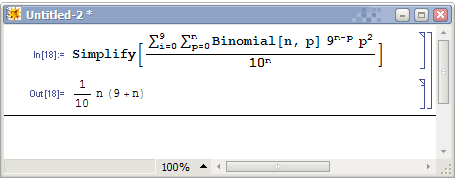 我們遺憾地發現,雖然常數因子很小(只有0.1),但算法的平均複雜度仍然是平方的。等一下,1/10的那個10是我們桶的個數嗎?那麼我們爲什麼不把桶的個數弄大點?我們乾脆用m來表示桶的個數,重新計算一次: 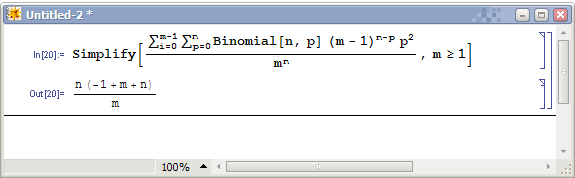 化簡出來,操作次數爲O(n+n^2/m)。發現了麼,如果m=Θ(n)的話,平均複雜度就變成了O(n)。也就是說,當桶的個數等於輸入數據的個數時,算法是平均線性的。 我們將在Hash表開散列的介紹中重新提到這個結論。 且慢,還有一個問題。10個桶以十分位的數字歸類,那麼n個桶用什麼方法來分類呢?注意,分類的方法需要滿足,一,一個數分到每個桶裏的概率相同(這樣才 有我們上面的結論);二,所有桶裏容納元素的範圍必須是連續的。根據這兩個條件,我們有辦法把所有數恰好分爲n類。我們的輸入數據不是都在0到1之間麼? 只需要看這些數乘以n的整數部分是多少就行了,讀到一個數後乘以n取整得幾就插入到幾號桶裏。這本質上相當於把區間[0,1)平均分成n份。 問題七:有沒有複雜度低於線性的排序算法 STOP! You should think for a while. 我們從O(n^2)走向O(nlogn),又從O(nlogn)走向線性,每一次我們都討論了複雜度下限的問題,根據討論的結果提出了更優的算法。這次總 算不行了,不可能有比線性還快的算法了,因爲——你讀入、輸出數據至少就需要線性的時間。排序算法之旅在線性時間複雜度這一站終止了,所有十種排序算法到 這裏介紹完畢了。 |
常用排序算法3
發表評論
所有評論
還沒有人評論,想成為第一個評論的人麼? 請在上方評論欄輸入並且點擊發布.