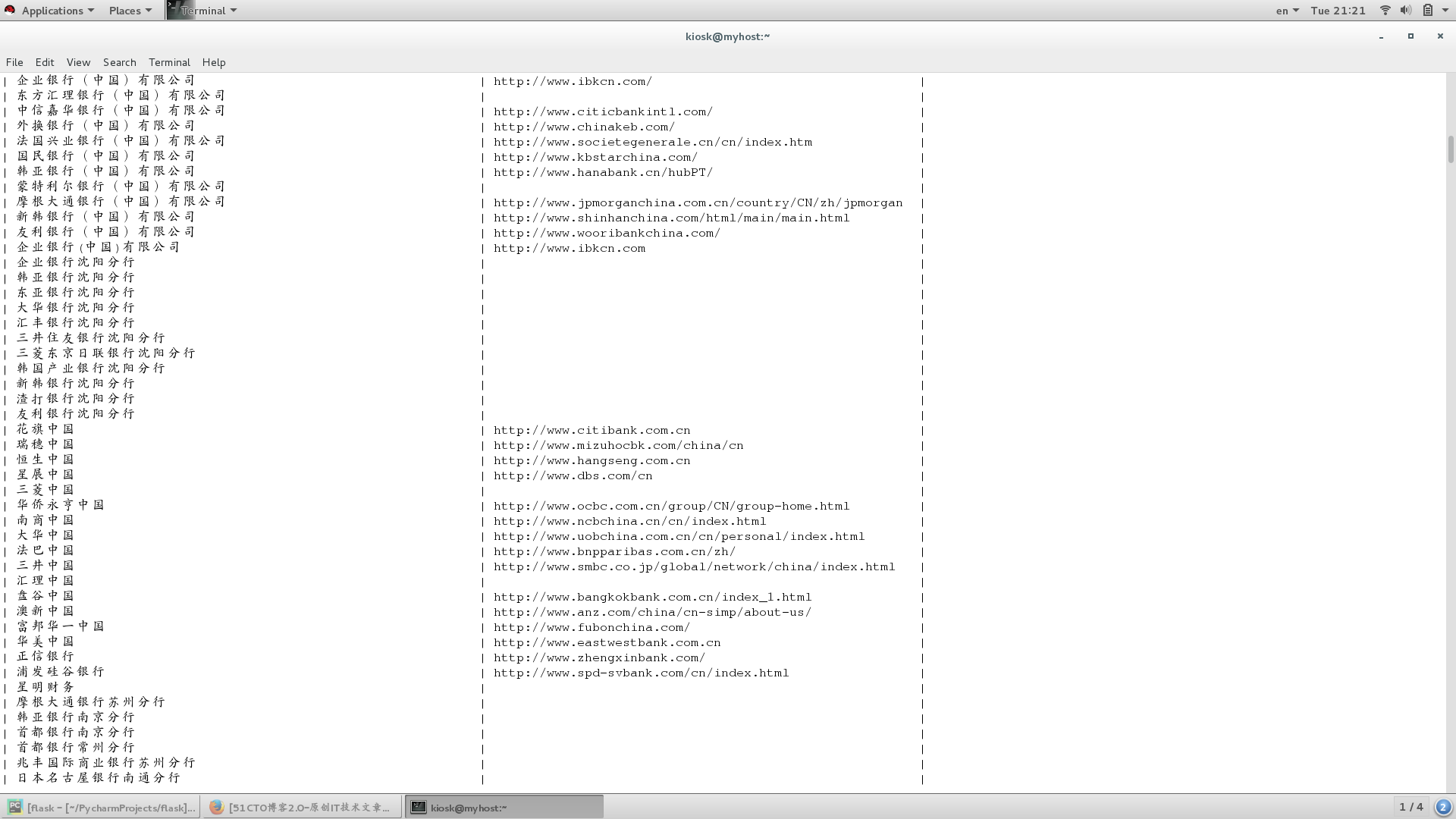
爬取所有銀行的銀行名稱和官網地址(如果沒有官網就忽略),並寫入數據庫。
目標網址:http://www.cbrc.gov.cn/chinese/jrjg/index.html
(因爲此網站做了反爬蟲機制,所以這裏需要我們將爬蟲僞裝瀏覽器進行訪問。)
關於爬蟲僞裝成瀏覽器訪問可以參考這篇文章:
https://blog.csdn.net/a877415861/article/details/79468878
話不多說直接上代碼:
import re
from urllib import request
from urllib.request import urlopen
import pymysql as mysql
u = 'root'
p = 'root'
d = 'python'
sql = 'insert into bank_info values(%s,%s)'
url = 'http://www.cbrc.gov.cn/chinese/jrjg/index.html'
# 爬蟲僞裝瀏覽器步驟:
# 1. 定義一個真實瀏覽器的代理名稱
myAgent = "Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0" #這個是我當前火狐瀏覽器的信息
# 2.將代理寫到請求頁面的header裏面去
myrequest = request.Request(url,headers={'User-Agent': myAgent} )
# 3. 打開網頁, 獲取內容
content = urlopen(myrequest).read().decode('utf-8')
# 獲取對象:<a href="http://www.icbc.com.cn/" target="_blank" style="color:#08619D">中國工商銀行</a>
pattern = r'<li style="margin.*inline;">\s*<a href="(http://.+?)" target="_blank" style="color:#08619D">\s*?([\S]*?)\s*?</a>|<li style="margin.*inline;">\s*?([\S]*?)\s*?</li>'
def main():
res = re.findall(pattern, content)
# [('http://www.hsbc.com.cn', '匯豐中國', ''), ...('', '', '蒙特利爾銀行(中國)有限公司')...]
conn = mysql.connect(user=u, passwd=p, db=d, charset='utf8', autocommit=True)
cur = conn.cursor()
for info in res:
if info[0]:
info = info[1::-1] # 有官網
else:
info = info[:-3:-1] # 無官網
cur.execute(sql, (info[0],info[1]))
conn.commit()
if __name__ == "__main__":
main()運行結果: