




k-means方法實現流程: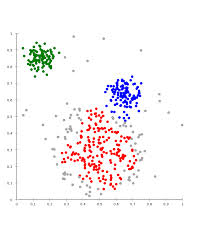
輸入:k, data[n];
(1) 選擇k個初始中心點,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 對於data[0]….data[n], 分別與c[0]…c[k-1]比較,假定與c[i]差值最少,就標記爲i;
(3) 對於所有標記爲i點,重新計算c[i]={ 所有標記爲i的data[j]之和}/標記爲i的個數;
(4) 重複(2)(3),直到所有c[i]值的變化小於給定閾值。
k-means方法具體實現和流程:
import numpy as np
#X樣本點座標矩陣
def kmeans(X, k, maxIt):
#X.shape:矩陣的形狀,返回值爲行和列
numPoints, numDim = X.shape
#得到一個比原矩陣多一列的0矩陣
dataSet = np.zeros((numPoints, numDim + 1))
#前面n-1列爲點的值
dataSet[:, :-1] = X
#Initialize centroids randomls隨機產生初始中心
#中心點爲任意一行數據
centroids = dataSet[np.random.randint(numPoints, size=k), :]
centroids = dataSet[0:2, :]
#爲中心點賦予類名稱,range函數的特點是按順序從前往後賦值1到k,但是k+1必須小於列數,複製到k時,後面的值自動爲0
centroids[:, -1] = range(1, k + 1)
#第一個爲存儲迭代次數,第二個存儲舊的中心
iterations = 0
oldCentroids = None
while not shouldStop(oldCentroids, centroids, iterations, maxIt):
print("iteration: \n", iterations)
print("dataSet: \n", dataSet)
print("centroids: \n", centroids)
#複製一份中心數據,這樣互不影響,引用則不行
oldCentroids = np.copy(centroids)
#每進行一次這個程序,迭代次數就增加1次
iterations += 1
#調用方法更新標籤
updateLabels(dataSet, centroids)
#調用方法更新中心
centroids = getCentroids(dataSet, k)
#We can get the labels too by calling getLabels(dataSet, centroids)
return dataSet
#結束條件:迭代次數大於設定的次數或者舊的迭代中心和新得到的迭代中心相等
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids, centroids)
#Update a label for each piece of data in the dataset.
def updateLabels(dataSet, centroids):
# For each element in the dataset, chose the closest centroid.
#Make that centroid the element's label.
numPoints, numDim = dataSet.shape
#循環獲取每一行數據
for i in range(0, numPoints):
#dataSet[i,-1]表示後面每一行數據的分類標籤
dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i, :-1], centroids)
def getLabelFromClosestCentroid(dataSetRow, centroids):
label = centroids[0, -1];
#第一行數據與目標的距離定義爲最小值
minDist = np.linalg.norm(dataSetRow - centroids[0, :-1])
#依次比較距離,最終得到屬於的標籤
for i in range(1, centroids.shape[0]):
dist = np.linalg.norm(dataSetRow - centroids[i, :-1])
if dist < minDist:
minDist = dist
label = centroids[i, -1]
print("minDist:", minDist)
return label
#Returns k random centroids, each of dimension n.
def getCentroids(dataSet, k):
result = np.zeros((k, dataSet.shape[1]))
#k表示聚類中心個數
for i in range(1, k + 1):
print(dataSet)
#找出同類型的點,取出樣本點的向量值
oneCluster = dataSet[dataSet[:, -1] == i, :-1]
print("--------------------")
print(oneCluster)
print("-------------------")
#通過均值計算中心點
result[i - 1, :-1] = np.mean(oneCluster, axis=0)
#給中心點賦標籤值
result[i - 1, -1] = i
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1, x2, x3, x4))
result = kmeans(testX, 2, 10)
print("final result:")
print(result)