




目錄
HDFS 是做什麼的
HDFS 從何而來
爲什麼選擇 HDFS 存儲數據
HDFS 如何存儲數據
HDFS 如何讀取文件
HDFS 如何寫入文件
HDFS 副本存放策略
Hadoop2.x新特性
1、HDFS 是做什麼的
HDFS(Hadoop Distributed File System)是Hadoop項目的核心子項目,是分佈式計算中數據存儲管理的基礎,是基於流數據模式訪問和處理超大文件的需求而開發的,可以運行於廉價的商用服務器上。它所具有的高容錯、高可靠性、高可擴展性、高獲得性、高吞吐率等特徵爲海量數據提供了不怕故障的存儲,爲超大數據集(Large Data Set)的應用處理帶來了很多便利。
2、HDFS 從何而來
HDFS 源於 Google 在2003年10月份發表的GFS(Google File System) 論文。 它其實就是 GFS 的一個克隆版本
3、爲什麼選擇 HDFS 存儲數據
之所以選擇 HDFS 存儲數據,因爲 HDFS 具有以下優點:
1、高容錯性
數據自動保存多個副本。它通過增加副本的形式,提高容錯性。
某一個副本丟失以後,它可以自動恢復,這是由 HDFS 內部機制實現的,我們不必關心。
2、適合批處理
它是通過移動計算而不是移動數據。
它會把數據位置暴露給計算框架。
3、適合大數據處理
處理數據達到 GB、TB、甚至PB級別的數據。
能夠處理百萬規模以上的文件數量,數量相當之大。
能夠處理10K節點的規模。
4、流式文件訪問
一次寫入,多次讀取。文件一旦寫入不能修改,只能追加。
它能保證數據的一致性。
5、可構建在廉價機器上
它通過多副本機制,提高可靠性。
它提供了容錯和恢復機制。比如某一個副本丟失,可以通過其它副本來恢復。
當然 HDFS 也有它的劣勢,並不適合所有的場合:
1、低延時數據訪問
比如毫秒級的來存儲數據,這是不行的,它做不到。
它適合高吞吐率的場景,就是在某一時間內寫入大量的數據。但是它在低延時的情況下是不行的,比如毫秒級以內讀取數據,這樣它是很難做到的。
2、小文件存儲
存儲大量小文件(這裏的小文件是指小於HDFS系統的Block大小的文件(默認64M))的話,它會佔用 NameNode大量的內存來存儲文件、目錄和塊信息。這樣是不可取的,因爲NameNode的內存總是有限的。
小文件存儲的尋道時間會超過讀取時間,它違反了HDFS的設計目標。
3、併發寫入、文件隨機修改
一個文件只能有一個寫,不允許多個線程同時寫。
僅支持數據 append(追加),不支持文件的隨機修改。
4、HDFS 如何存儲數據
HDFS的架構圖
HDFS 採用Master/Slave的架構來存儲數據,這種架構主要由四個部分組成,分別爲HDFS Client、NameNode、DataNode和Secondary NameNode。下面我們分別介紹這四個組成部分
1、Client:就是客戶端。
文件切分。文件上傳 HDFS 的時候,Client 將文件切分成 一個一個的Block,然後進行存儲。
與 NameNode 交互,獲取文件的位置信息。
與 DataNode 交互,讀取或者寫入數據。
Client 提供一些命令來管理 HDFS,比如啓動或者關閉HDFS。
Client 可以通過一些命令來訪問 HDFS。
2、NameNode:就是 master,它是一個主管、管理者。
管理 HDFS 的名稱空間
管理數據塊(Block)映射信息
配置副本策略
處理客戶端讀寫請求。
3、DataNode:就是Slave。NameNode 下達命令,DataNode 執行實際的操作。
存儲實際的數據塊。
執行數據塊的讀/寫操作。
4、Secondary NameNode:並非 NameNode 的熱備。當NameNode 掛掉的時候,它並不能馬上替換 NameNode 並提供服務。
輔助 NameNode,分擔其工作量。
定期合併 fsimage和fsedits,並推送給NameNode。
在緊急情況下,可輔助恢復 NameNode。
5、HDFS 如何讀取文件
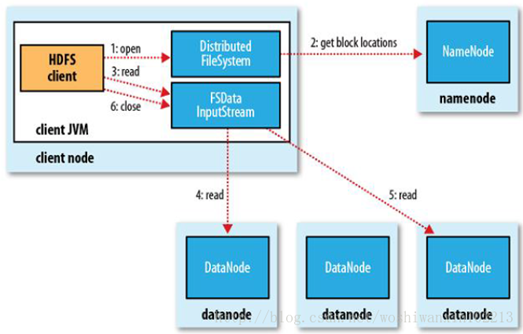
HDFS的文件讀取原理,主要包括以下幾個步驟:
首先調用FileSystem對象的open方法,其實獲取的是一個DistributedFileSystem的實例。
DistributedFileSystem通過RPC(遠程過程調用)獲得文件的第一批block的locations,同一block按照重複數會返回多個locations,這些locations按照hadoop拓撲結構排序,距離客戶端近的排在前面。
前兩步會返回一個FSDataInputStream對象,該對象會被封裝成 DFSInputStream對象,DFSInputStream可以方便的管理datanode和namenode數據流。客戶端調用read方法,DFSInputStream就會找出離客戶端最近的datanode並連接datanode。
數據從datanode源源不斷的流向客戶端。
如果第一個block塊的數據讀完了,就會關閉指向第一個block塊的datanode連接,接着讀取下一個block塊。這些操作對客戶端來說是透明的,從客戶端的角度來看只是讀一個持續不斷的流。
如果第一批block都讀完了,DFSInputStream就會去namenode拿下一批blocks的location,然後繼續讀,如果所有的block塊都讀完,這時就會關閉掉所有的流。
6、HDFS 如何寫入文件
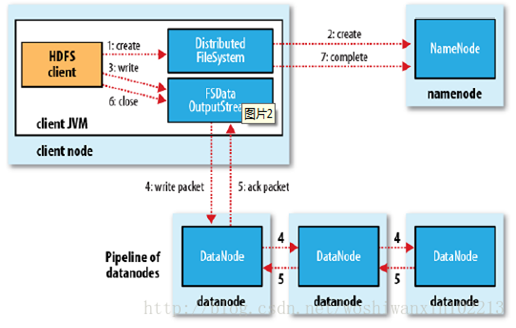
HDFS的文件寫入原理,主要包括以下幾個步驟:
客戶端通過調用 DistributedFileSystem 的create方法,創建一個新的文件。
DistributedFileSystem 通過 RPC(遠程過程調用)調用 NameNode,去創建一個沒有blocks關聯的新文件。創建前,NameNode 會做各種校驗,比如文件是否存在,客戶端有無權限去創建等。如果校驗通過,NameNode 就會記錄下新文件,否則就會拋出IO異常。
前兩步結束後會返回 FSDataOutputStream 的對象,和讀文件的時候相似,FSDataOutputStream 被封裝成 DFSOutputStream,DFSOutputStream 可以協調 NameNode和 DataNode。客戶端開始寫數據到DFSOutputStream,DFSOutputStream會把數據切成一個個小packet,然後排成隊列 data queue。
DataStreamer 會去處理接受 data queue,它先問詢 NameNode 這個新的 block 最適合存儲的在哪幾個DataNode裏,比如重複數是3,那麼就找到3個最適合的 DataNode,把它們排成一個 pipeline。DataStreamer 把 packet 按隊列輸出到管道的第一個 DataNode 中,第一個 DataNode又把 packet 輸出到第二個 DataNode 中,以此類推。
DFSOutputStream 還有一個隊列叫 ack queue,也是由 packet 組成,等待DataNode的收到響應,當pipeline中的所有DataNode都表示已經收到的時候,這時akc queue纔會把對應的packet包移除掉。
客戶端完成寫數據後,調用close方法關閉寫入流。
DataStreamer 把剩餘的包都刷到 pipeline 裏,然後等待 ack 信息,收到最後一個 ack 後,通知 DataNode 把文件標示爲已完成。
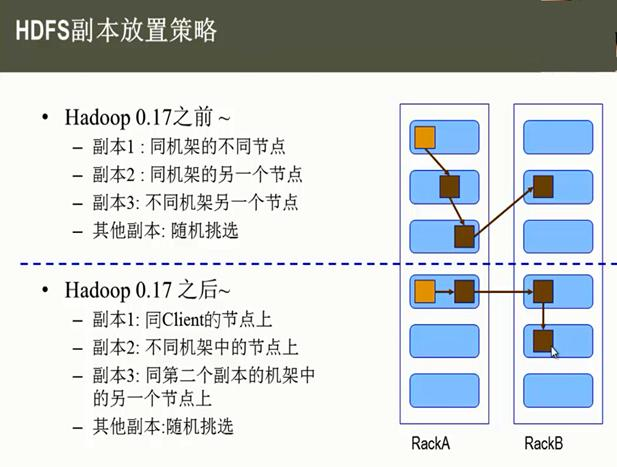
7、HDFS 副本存放策略
namenode如何選擇在哪個datanode 存儲副本(replication)?這裏需要對可靠性、寫入帶寬和讀取帶寬進行權衡。Hadoop對datanode存儲副本有自己的副本策略,在其發展過程中一共有兩個版本的副本策略,分別如下所示
8、hadoop2.x新特性
引入了NameNode Federation,解決了橫向內存擴展
引入了Namenode HA,解決了namenode單點故障
引入了YARN,負責資源管理和調度
增加了ResourceManager HA解決了ResourceManager單點故障
1、NameNode Federation
架構如下圖
存在多個NameNode,每個NameNode分管一部分目錄
NameNode共用DataNode
這樣做的好處就是當NN內存受限時,能擴展內存,解決內存擴展問題,而且每個NN獨立工作相互不受影響,比如其中一個NN掛掉啦,它不會影響其他NN提供服務,但我們需要注意的是,雖然有多個NN,分管不同的目錄,但是對於特定的NN,依然存在單點故障,因爲沒有它沒有熱備,解決單點故障使用NameNode HA
2、NameNode HA
解決方案:
基於NFS共享存儲解決方案
基於Qurom Journal Manager(QJM)解決方案
1、基於NFS方案
Active NN與Standby NN通過NFS實現共享數據,但如果Active NN與NFS之間或Standby NN與NFS之間,其中一處有網絡故障的話,那就會造成數據同步問題
2、基於QJM方案
架構如下圖 
Active NN、Standby NN有主備之分,NN Active是主的,NN Standby備用的
集羣啓動之後,一個namenode是active狀態,來處理client與datanode之間的請求,並把相應的日誌文件寫到本地中或JN中;
Active NN與Standby NN之間是通過一組JN共享數據(JN一般爲奇數個,ZK一般也爲奇數個),Active NN會把日誌文件、鏡像文件寫到JN中去,只要JN中有一半寫成功,那就表明Active NN向JN中寫成功啦,Standby NN就開始從JN中讀取數據,來實現與Active NN數據同步,這種方式支持容錯,因爲Standby NN在啓動的時候,會加載鏡像文件(fsimage)並週期性的從JN中獲取日誌文件來保持與Active NN同步
爲了實現Standby NN在Active NN掛掉之後,能迅速的再提供服務,需要DN不僅需要向Active NN彙報,同時還要向Standby NN彙報,這樣就使得Standby NN能保存數據塊在DN上的位置信息,因爲在NameNode在啓動過程中最費時工作,就是處理所有DN上的數據塊的信息
爲了實現Active NN高熱備,增加了FailoverController和ZK,FailoverController通過Heartbeat的方式與ZK通信,通過ZK來選舉,一旦Active NN掛掉,就選取另一個FailoverController作爲active狀態,然後FailoverController通過rpc,讓standby NN轉變爲Active NN
FailoverController一方面監控NN的狀態信息,一方面還向ZK定時發送心跳,使自己被選舉。當自己被選爲主(Active)的時候,就會通過rpc使相應NN轉變Active狀態