




Python爬蟲獲取招聘網站職位信息
摘要
本文介紹使用Python編寫爬蟲,獲取招聘網站中感興趣的職位信息。
好的開始,成功一半。另一半呢?知己知彼,百戰百勝。
0. 環境
0.1 Python解釋器安裝
推薦使用Anaconda發行版,其包含了多個科學包及其依賴項。官網爲:https://www.anaconda.com/
可以從官網下載安裝包,在本地安裝,將安裝之後的位置作爲環境變量加入到系統環境變量的PATH中。
Anaconda一般安裝之後的位置爲:C:\ProgramData\Anaconda3
0.2 集成開發環境
IDE(集成開發環境,Integrated Development Environment ):這一類開發環境一般包括代碼編輯器、編譯器、調試器和圖形用戶界面等工具。集成了代碼編寫功能、分析功能、編譯功能、調試功能等一體化的開發軟件服務套件。
推薦使用PyCharm的社區版,官網爲:https://www.jetbrains.com/pycharm

1. 確定目標
這裏的目標就是指要爬取的內容,打開招聘網站:https://www.51job.com:在搜索框中輸入python,並點擊搜索,會得到下面的結果,一共63頁,3000餘條職位信息:
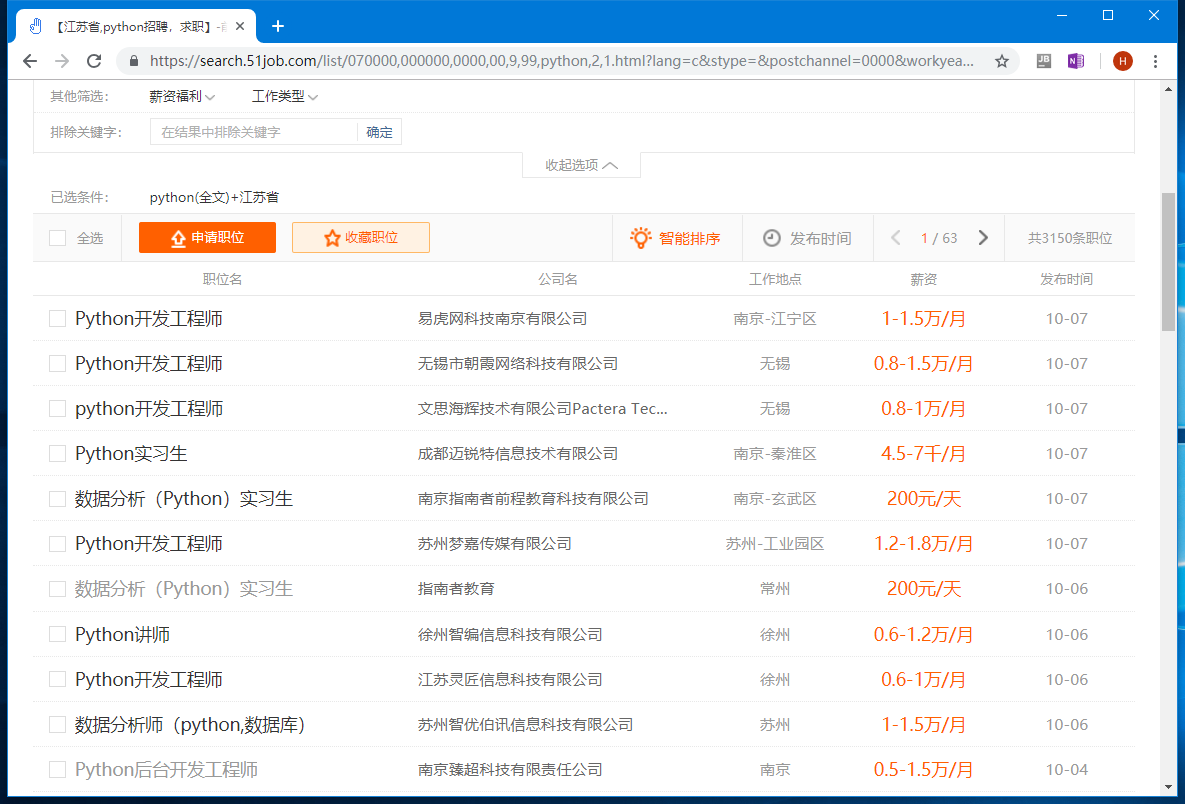
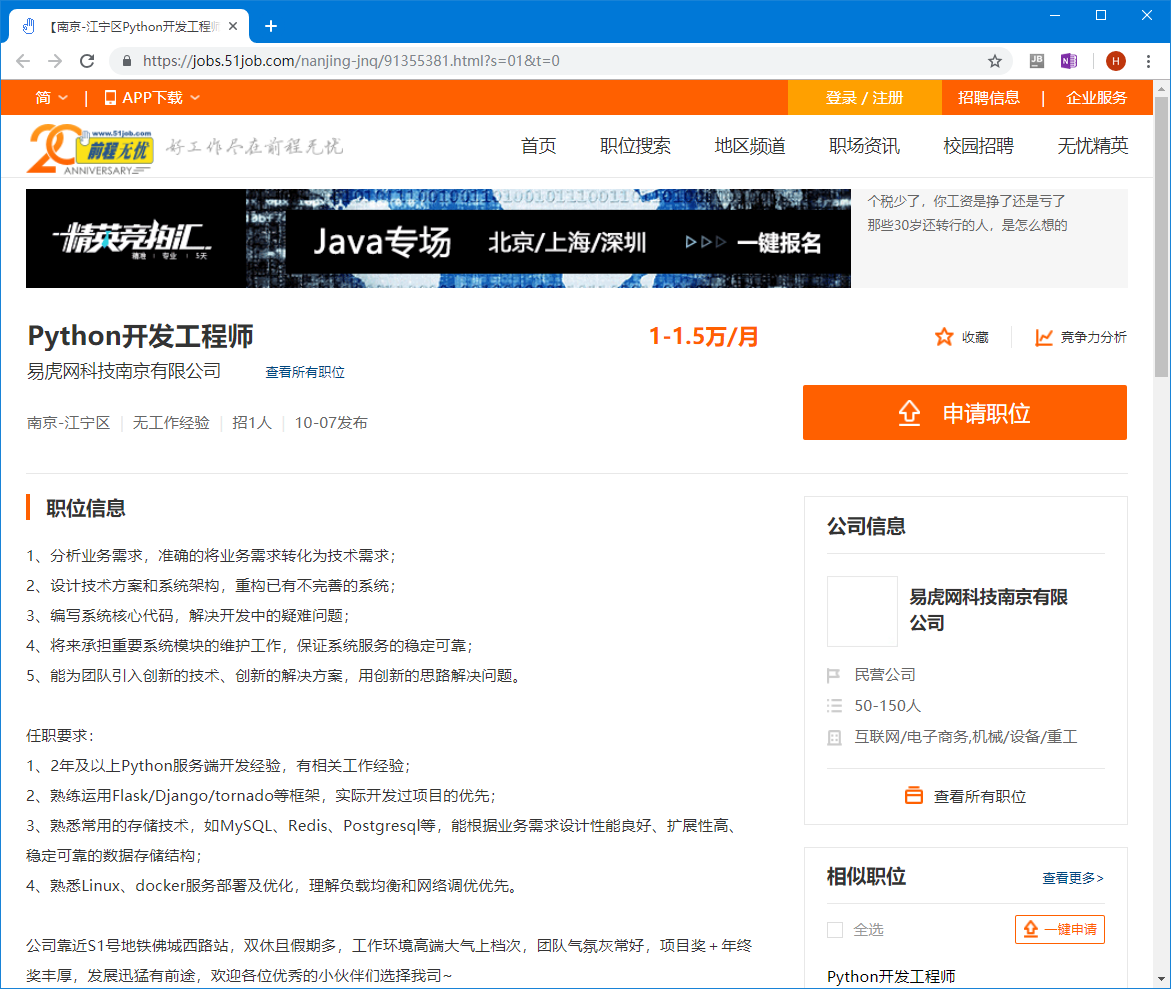
裏面的每一個職位點開之後的頁面包含職位的相關信息,我們的目標就是將這些信息爬取並保存到本地。
2. 請求
所有的職位信息頁面的網址類似於如下形式:
https://jobs.51job.com/nanjing-jnq/91355381.html?s=01&t=0
https://jobs.51job.com/wuxi/97144561.html?s=01&t=0
https://jobs.51job.com/nanjing-qhq/106264137.html?s=01&t=0
。。。這些頁面網址沒有多少規律可循,但是可以從職位搜索結果頁面中獲取到:
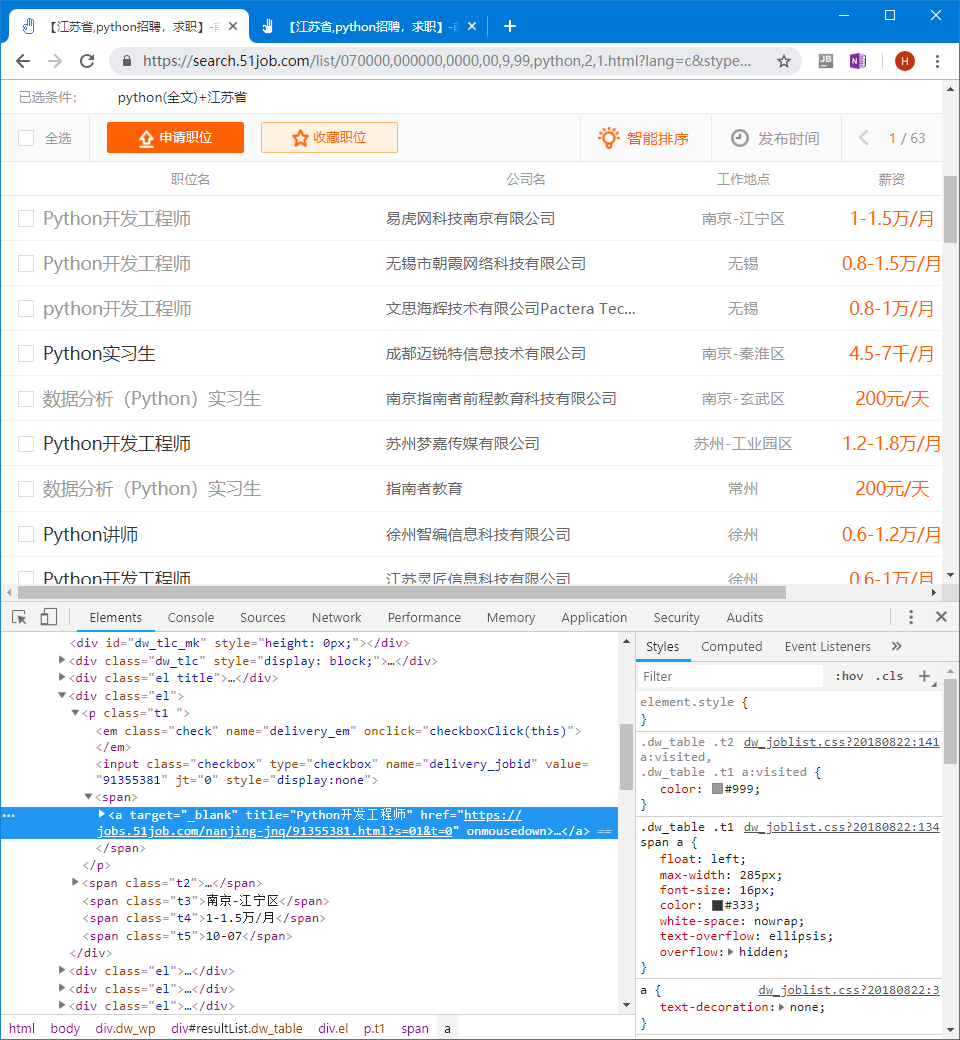
通過獲取任意頁數的職位名這一位置的鏈接,就能夠獲取這些職位信息的鏈接頁面。
https://search.51job.com/list/070000,000000,0000,00,9,99,Python,2,1.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=
https://search.51job.com/list/070000,000000,0000,00,9,99,Python,2,2.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=搜索結果地址中的python是查詢的關鍵字,兩個鏈接的差異之處,就是查詢結果的第幾頁,所以可以根據這一點構建所有的搜索結果頁面。
KEYWORD = 'python'
MAX_PAGE = 10
for i in range(MAX_PAGE + 1):
temp_url = 'https://search.51job.com/list/070000,000000,0000,00,9,99,' + KEYWORD + ',2,' + str(
i) + '.html?lang=c&stype=1&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=4&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='通過requests包的的請求功能,獲取到頁面:
r = requests.get('https://jobs.51job.com/nanjing-jnq/91355381.html?s=01&t=0')
r.encoding = 'gbk'
print(r.text)3. 解析
在搜索結果頁面中需要解析出每一個職位的鏈接,同時在職位詳細信息頁面,要解析出職位名稱,公司名稱,工資,所在城市,職位信息等內容。
解析可以使用python中的lxml庫進行解析,最常用的解析方式爲xpath方式,通過Chrome中的F12開發者工具來獲取xpath並調試。
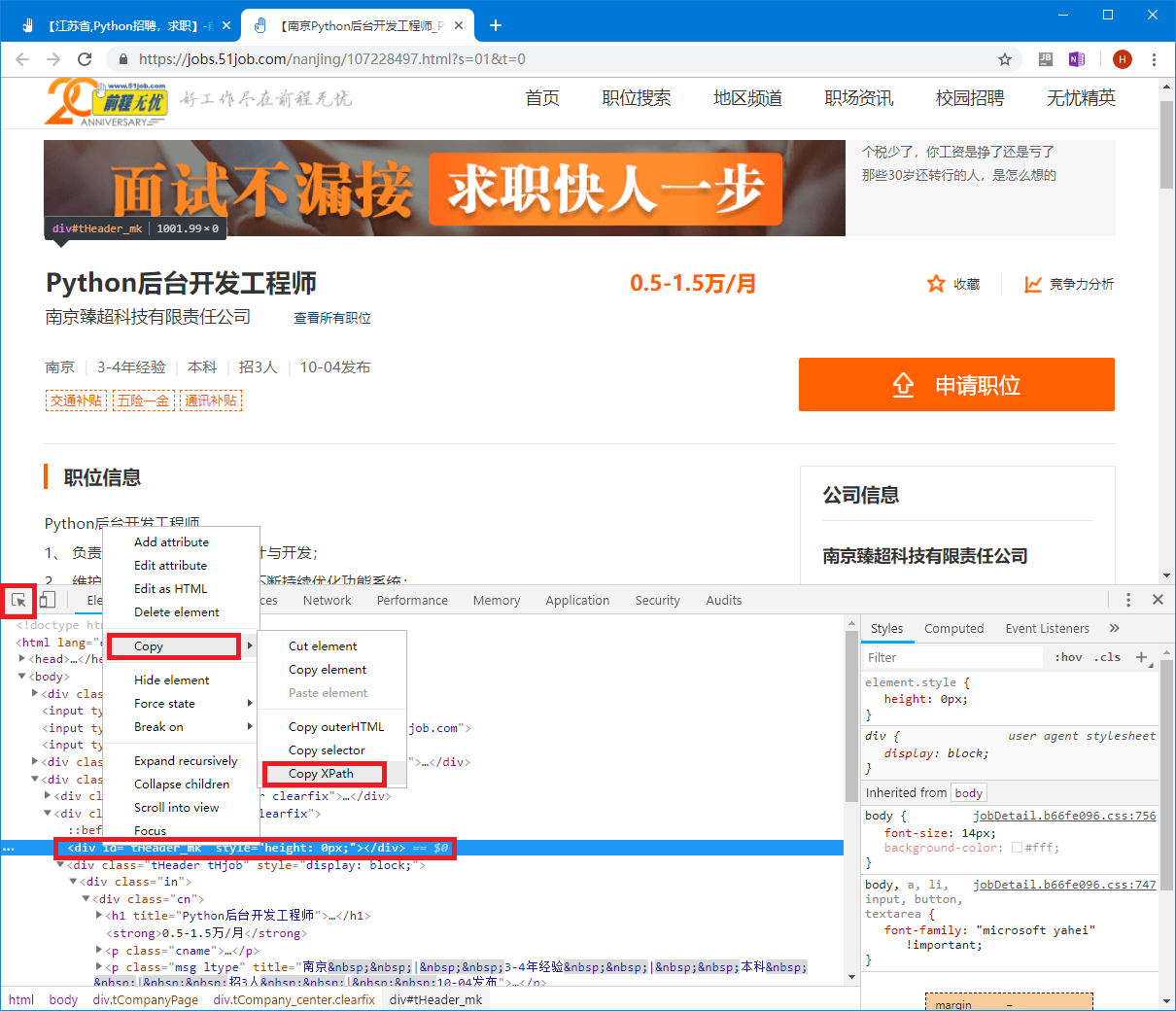
在F12開發者工具中,左上角的選擇按鈕可以在頁面上選取感興趣的元素,然後下面的元素窗口將高亮顯示選中的元素。
在高亮顯示的元素上,右鍵單擊,在彈出的菜單中選擇Copy -> Copy XPath,即可獲得此元素的XPath。
然後在此元素基礎之上,可以通過@屬性的方式獲取元素的屬性值,例如獲得職位的鏈接地址:
//*[@id="resultList"]/div[4]/p/span/a/@href
結果爲:
https://jobs.51job.com/nanjing/107228497.html?s=01&t=0或通過text()方式獲取元素的顯示內容,例如職位詳細信息裏面的各項值:
/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()
結果爲:
0.5-1.5萬/月4. 存儲
爲方便後續的數據分析和繪圖,我們將結果存儲在excel表中,通過openpyxl庫來實現。
在openpyxl中,主要用到三個概念:Workbooks,Sheets,Cells。Workbook就是一個excel工作表;Sheet是工作表中的一張表頁;Cell就是一個單元格。
首先引入庫:
from openpyxl import Workbook然後創建xlsx文件:
wb = Workbook()獲取激活的sheet:
sheet = wb.active在其中編輯單元格的內容,將前面獲取的職位信息寫入到表格中:
sheet.append(list(temp_info.values()))最後將wb保存成一個文件:
wb.save('result.xlsx')5. 代碼
完整代碼參見附件。