




如果對網絡工程基礎不牢,建議通讀《細說OSI七層協議模型及OSI參考模型中的數據封裝過程?》
下面就是TCP/IP(Transmission Control Protoco/Internet Protocol )協議頭部的格式,是理解其它內容的基礎,就關鍵字段做一些說明
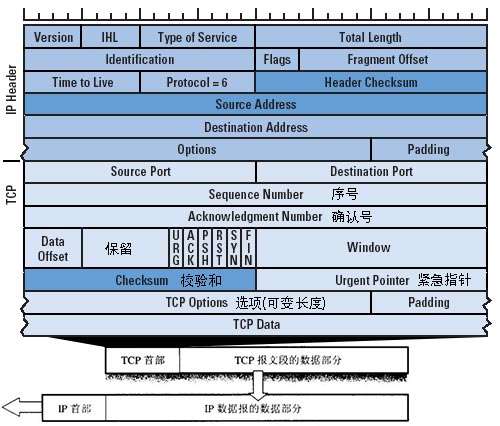
Source Port和Destination Port:分別佔用16位,表示源端口號和目的端口號;用於區別主機中的不同進程,而IP地址是用來區分不同的主機的,源端口號和目的端口號配合上IP首部中的源IP地址和目的IP地址就能唯一的確定一個TCP連接;
Sequence Number:TCP連接中傳送的字節流中的每個字節都按順序編號,用來標識從TCP發送端向TCP收收端發送的數據字節流,它表示在這個報文段中的的第一個數據字節在數據流中的序號;主要用來解決網絡報亂序的問題;
Acknowledgment Number:期望收到對方下一個報文的第一個數據字節的序號個序號,因此,確認序號應當是上次已成功收到數據字節序號加1。不過,只有當標誌位中的ACK標誌(下面介紹)爲1時該確認序列號的字段纔有效。主要用來解決不丟包的問題;
Offset:它指出TCP報文的數據距離TCP報文段的起始處有多遠,給出首部中32 bit字的數目,需要這個值是因爲任選字段的長度是可變的。這個字段佔4bit(最多能表示15個32bit的的字,即4*15=60個字節的首部長度),因此TCP最多有60字節的首部。然而,沒有任選字段,正常的長度是20字節;
TCP Flags:TCP首部中有6個標誌比特,它們中的多個可同時被設置爲1,主要是用於操控TCP的狀態機的,依次爲URG,ACK,PSH,RST,FIN。每個標誌位的意思如下:
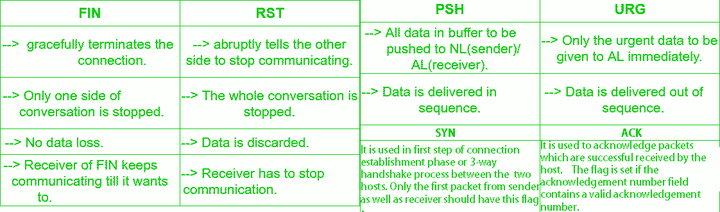
SYN (Synchronize Sequence Numbers)-同步序列編號-同步標籤The segment is a request to synchronize sequence numbers and establish a connection. The sequence number field contains the sender's initial sequence number. 該標誌僅在三次握手建立TCP連接時有效。它提示TCP連接的服務端檢查序列編號,該序列編號爲TCP連接初始端(一般是客戶端)的初始序列編號。在這裏,可以把TCP序列編號看作是一個範圍從0到4,294,967,295的32位計數器。通過TCP連接交換的數據中每一個字節都經過序列編號。在TCP報頭中的序列編號欄包括了TCP分段中第一個字節的序列編號。 在連接建立時用來同步序號。當SYN=1而ACK=0時,表明這是一個連接請求報文。對方若同意建立連接,則應在響應報文中使SYN=1和ACK=1. 因此, SYN置1就表示這是一個連接請求或連接接受報文。
ACK (Acknowledgement Number)-確認編號-確認標誌The segment carries an acknowledgement and the value of the acknowledgement number field is valid and contains the next sequence number that is expected from the receiver. 大多數情況下該標誌位是置位的。TCP報頭內的確認編號欄內包含的確認編號(w+1,Figure-1)爲下一個預期的序列編號,同時提示遠端系統已經成功接收所有數據。 TCP協議規定,只有ACK=1時有效,也規定連接建立後所有發送的報文的ACK必須爲1 網絡上有很多錯誤說法,比如:ACK是可能與SYN,FIN等同時使用的,比如SYN和ACK可能同時爲1,它表示的就是建立連接之後的響應,如果只是單個的一個SYN,它表示的只是建立連接。TCP的幾次握手就是通過這樣的ACK表現出來的。其實:ACK&SYN是標誌位,
FIN (Finish)-結束標誌The sender wants to close the connection 用來釋放一個連接。 當 FIN = 1 時,表明此報文段的發送方的數據已經發送完畢,並要求釋放連接。
URG (The urgent pointer)-緊急標誌Segment is urgent and the urgent pointer field carries valid information. 當URG=1,表明緊急指針字段有效。告訴系統此報文段中有緊急數據
PSH (Push)-推標誌The data in this segment should be immediately pushed to the application layer on arrival. PSH爲1的情況,一般只出現在 DATA內容不爲0的包中,也就是說PSH=1表示有真正的TCP數據包內容被傳遞。
RST (Reset)-復位標誌There was some problem and the sender wants to abort the connection. 當RST=1,表明TCP連接中出現嚴重差錯,必須釋放連接,然後再重新建立連接
Window(Advertised-Window)—窗口大小:滑動窗口,用來進行流量控制。佔2字節,指的是通知接收方,發送本報文你需要有多大的空間來接受
CWR (Congestion Window Reduced)
Set by an ECN-Capable sender when it reduces its congestion window (due to a retransmit timeout, a fast retransmit or in response to an ECN notification.
ECN (Explicit Congestion Notification)
During the three-way handshake it indicates that sender is capable of performing explicit congestion notification. Normally it means that a packet with the IP Congestion Experienced flag set was received during normal transmission. See RFC 3168 for more information.
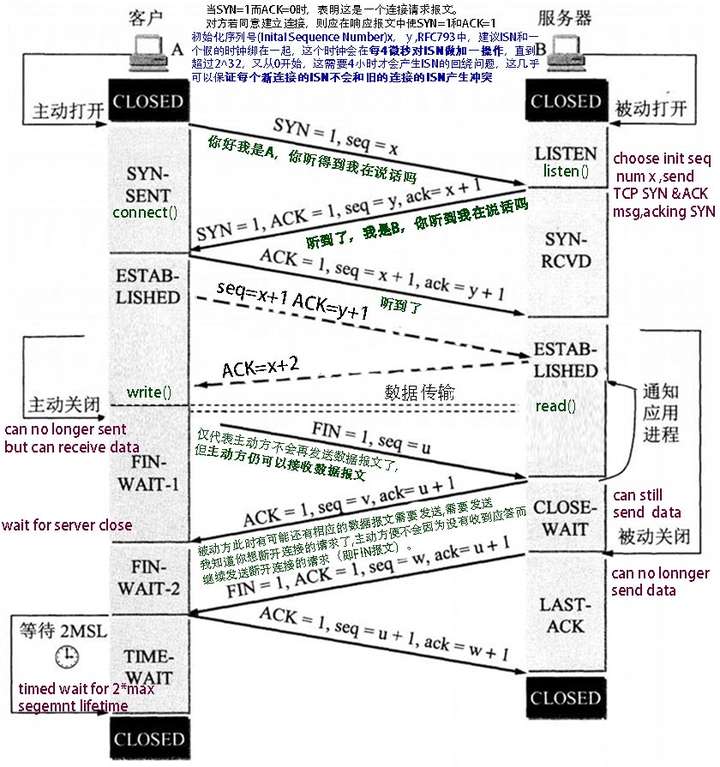
TCP的連接建立和連接關閉,都是通過請求-響應的模式完成的。我們來看下圖,應該基本能夠理解TCP握手揮手過程
Three-way Handshake 三次握手
三次握手的目的是:爲了防止已失效的連接請求報文段突然又傳送到了服務端,因而產生錯誤。推薦閱讀《TCP的三次握手與四次揮手(詳解+動圖》
當然,如果那邊同時打開,就有可能是四次握手
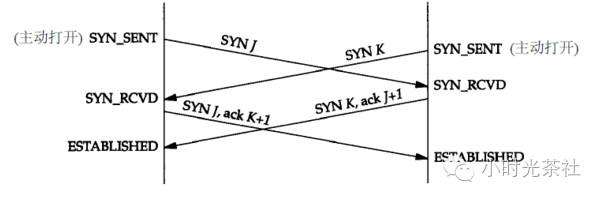
在此推薦閱讀《面試題·TCP 爲什麼要三次握手,四次揮手?》
TCP 連接的初始化序列號能否固定
單個TCP包每次打包1448字節的數據進行發送(以太網Ethernet最大的數據幀是1518字節,以太網幀的幀頭14字節和幀尾CRC校驗4字節(共佔18字節),剩下承載上層協議的地方也就是Data域最大就只剩1500字節. 這個值我們就把它稱之爲MTU(Maximum Transmission Unit))。
那麼一次性發送大量數據,就必須分成多個包。比如,一個 10MB 的文件,需要發送7100多個包。
發送的時候,TCP 協議爲每個包編號(sequence number,簡稱 SEQ),以便接收的一方按照順序還原。萬一發生丟包,也可以知道丟失的是哪一個包。
第一個包的編號是一個隨機數—初始化序列號(縮寫爲ISN:Inital Sequence Number)
爲了便於理解,這裏就把它稱爲1號包。假定這個包的負載長度是100字節,那麼可以推算出下一個包的編號應該是101。這就是說,每個數據包都可以得到兩個編號:自身的編號,以及下一個包的編號。接收方由此知道,應該按照什麼順序將它們還原成原始文件。
如果初始化序列號可以固定,我們來看看會出現什麼問題?
假設ISN固定是1,Client和Server建立好一條TCP連接後,Client連續給Server發了10個包,這10個包不知怎麼被鏈路上的路由器緩存了(路由器會毫無先兆地緩存或者丟棄任何的數據包),這個時候碰巧Client掛掉了,然後Client用同樣的端口號重新連上Server,Client又連續給Server發了幾個包,假設這個時候Client的序列號變成了5。接着,之前被路由器緩存的10個數據包全部被路由到Server端了,Server給Client回覆確認號10,這個時候,Client整個都不好了,這是什麼情況?我的序列號纔到5,你怎麼給我的確認號是10了,整個都亂了。
RFC793中,建議ISN和一個假的時鐘綁在一起,這個時鐘會在每4微秒對ISN做加一操作,直到超過2^32,又從0開始,這需要4小時纔會產生ISN的迴繞問題,這幾乎可以保證每個新連接的ISN不會和舊的連接的ISN產生衝突。這種遞增方式的ISN,很容易讓***者猜測到TCP連接的ISN,現在的實現大多是在一個基準值的基礎上進行隨機的。
注:這些內容引用自《從 TCP 三次握手說起:淺析TCP協議中的疑難雜症 》,推薦查看。
初始化連接的 SYN 超時問題
Client發送SYN包給Server後掛了,Server回給Client的SYN-ACK一直沒收到Client的ACK確認,這個時候這個連接既沒建立起來,也不能算失敗。這就需要一個超時時間讓Server將這個連接斷開,否則這個連接就會一直佔用Server的SYN連接隊列中的一個位置,大量這樣的連接就會將Server的SYN連接隊列耗盡,讓正常的連接無法得到處理。
目前,Linux下默認會進行5次重發SYN-ACK包,重試的間隔時間從1s開始,下次的重試間隔時間是前一次的雙倍,5次的重試時間間隔爲1s, 2s, 4s, 8s, 16s,總共31s,第5次發出後還要等32s都知道第5次也超時了,所以,總共需要 1s + 2s + 4s+ 8s+ 16s + 32s = 63s,TCP纔會把斷開這個連接。由於,SYN超時需要63秒,那麼就給***者一個***服務器的機會,***者在短時間內發送大量的SYN包給Server(俗稱 SYN flood ***),用於耗盡Server的SYN隊列。對於應對SYN 過多的問題,linux提供了幾個TCP參數:tcp_syncookies、tcp_synack_retries、tcp_max_syn_backlog、tcp_abort_on_overflow 來調整應對。
什麼是 SYN ***(SYN Flood)SYN ***指的是,***客戶端在短時間內僞造大量不存在的IP地址,向服務器不斷地發送SYN包,服務器回覆確認包,並等待客戶的確認。由於源地址是不存在的,服務器需要不斷的重發直至超時,這些僞造的SYN包將長時間佔用未連接隊列,正常的SYN請求被丟棄,導致目標系統運行緩慢,嚴重者會引起網絡堵塞甚至系統癱瘓。 SYN ***是一種典型的 DoS(Denial of Service)/DDoS(:Distributed Denial of Service) ***。
如何檢測 SYN ***?檢測 SYN ***非常的方便,當你在服務器上看到大量的半連接狀態時,特別是源IP地址是隨機的,基本上可以斷定這是一次SYN***。在 Linux/Unix 上可以使用系統自帶的 netstats 命令來檢測 SYN ***。
如何防禦 SYN ***?SYN***不能完全被阻止,除非將TCP協議重新設計。我們所做的是儘可能的減輕SYN***的危害,常見的防禦 SYN ***的方法有如下幾種:
縮短超時(SYN Timeout)時間
增加最大半連接數
過濾網關防護
SYN cookies技術
如果已經建立了連接,但是客戶端突然出現故障了怎麼辦?
TCP還設有一個保活計時器,顯然,客戶端如果出現故障,服務器不能一直等下去,白白浪費資源。服務器每收到一次客戶端的請求後都會重新復位這個計時器,時間通常是設置爲2小時,若兩小時還沒有收到客戶端的任何數據,服務器就會發送一個探測報文段,以後每隔75分鐘發送一次。若一連發送10個探測報文仍然沒反應,服務器就認爲客戶端出了故障,接着就關閉連接。
Four-way Handshake 四次揮手
現來看下TCP各種狀態含義解析(節選改編自《TCP、UDP 的區別,三次握手、四次揮手》
FIN_WAIT_1 :這個狀態得好好解釋一下,其實FIN_WAIT_1 和FIN_WAIT_2 兩種狀態的真正含義都是表示等待對方的FIN報文。而這兩種狀態的區別是:- FIN_WAIT_1狀態實際上是當SOCKET在ESTABLISHED狀態時,它想主動關閉連接,向對方發送了FIN報文,此時該SOCKET進入到FIN_WAIT_1 狀態。而當對方迴應ACK報文後,則進入到FIN_WAIT_2 狀態。當然在實際的正常情況下,無論對方處於任何種情況下,都應該馬上回應ACK報文,所以FIN_WAIT_1 狀態一般是比較難見到的,而FIN_WAIT_2 狀態有時仍可以用netstat看到。
FIN_WAIT_2 :上面已經解釋了這種狀態的由來,實際上FIN_WAIT_2狀態下的SOCKET表示半連接,即有一方調用close()主動要求關閉連接。注意:FIN_WAIT_2 是沒有超時的(不像TIME_WAIT 狀態),這種狀態下如果對方不關閉(不配合完成4次揮手過程),那這個 FIN_WAIT_2 狀態將一直保持到系統重啓,越來越多的FIN_WAIT_2 狀態會導致內核crash。
TIME_WAIT :表示收到了對方的FIN報文,併發送出了ACK報文。 TIME_WAIT狀態下的TCP連接會等待2*MSL(Max Segment Lifetime,最大分段生存期,指一個TCP報文在Internet上的最長生存時間。每個具體的TCP協議實現都必須選擇一個確定的MSL值,RFC 1122建議是2分鐘,但BSD傳統實現採用了30秒,Linux可以cat /proc/sys/net/ipv4/tcp_fin_timeout看到本機的這個值),然後即可回到CLOSED 可用狀態了。如果FIN_WAIT_1狀態下,收到了對方同時帶FIN標誌和ACK標誌的報文時,可以直接進入到TIME_WAIT狀態,而無須經過FIN_WAIT_2狀態。
CLOSING :這種狀態在實際情況中應該很少見,屬於一種比較罕見的例外狀態。正常情況下,當一方發送FIN報文後,按理來說是應該先收到(或同時收到)對方的ACK報文,再收到對方的FIN報文。但是CLOSING 狀態表示一方發送FIN報文後,並沒有收到對方的ACK報文,反而卻也收到了對方的FIN報文。什麼情況下會出現此種情況呢?那就是當雙方幾乎在同時close()一個SOCKET的話,就出現了雙方同時發送FIN報文的情況,這是就會出現CLOSING 狀態,表示雙方都正在關閉SOCKET連接。
CLOSE_WAIT :表示正在等待關閉。怎麼理解呢?當對方close()一個SOCKET後發送FIN報文給自己,你的系統毫無疑問地將會迴應一個ACK報文給對方,此時TCP連接則進入到CLOSE_WAIT狀態。接下來呢,你需要檢查自己是否還有數據要發送給對方,如果沒有的話,那你也就可以close()這個SOCKET併發送FIN報文給對方,即關閉自己到對方這個方向的連接。有數據的話則看程序的策略,繼續發送或丟棄。簡單地說,當你處於CLOSE_WAIT 狀態下,需要完成的事情是等待你去關閉連接。
LAST_ACK :當被動關閉的一方在發送FIN報文後,等待對方的ACK報文的時候,就處於LAST_ACK 狀態。當收到對方的ACK報文後,也就可以進入到CLOSED 可用狀態了。
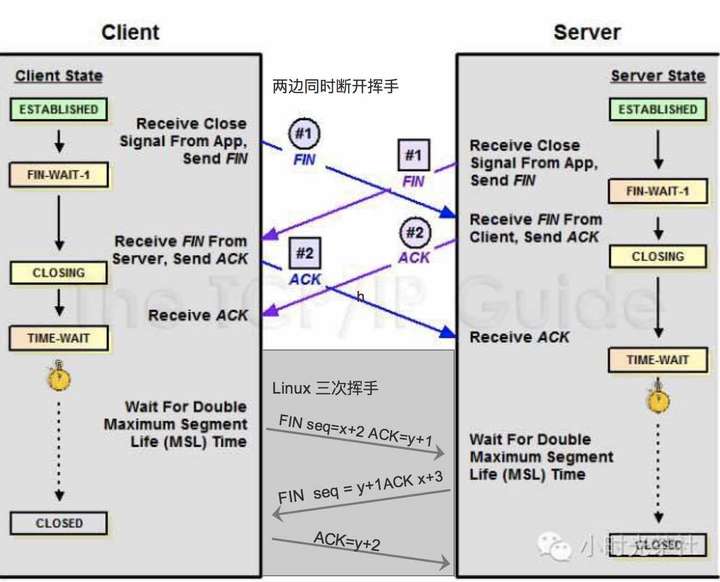
TCP 的 Peer 兩端同時斷開連接
由上面的”TCP協議狀態機 “圖可以看出
TCP的Peer端在收到對端的FIN包前 發出了FIN包,那麼該Peer的狀態就變成了FIN_WAIT1
Peer在FIN_WAIT1狀態下收到對端Peer對自己FIN包的ACK包的話,那麼Peer狀態就變成FIN_WAIT2,
Peer在FIN_WAIT2下收到對端Peer的FIN包,在確認已經收到了對端Peer全部的Data數據包後,就響應一個ACK給對端Peer,然後自己進入TIME_WAIT狀態。
但是如果Peer在FIN_WAIT1狀態下首先收到對端Peer的FIN包的話,那麼該Peer在確認已經收到了對端Peer全部的Data數據包後,就響應一個ACK給對端Peer,然後自己進入CLOSEING狀態,Peer在CLOSEING狀態下收到自己的FIN包的ACK包的話,那麼就進入TIME WAIT 狀態。於是
TCP的Peer兩端同時發起FIN包進行斷開連接,那麼兩端Peer可能出現完全一樣的狀態轉移 FIN_WAIT1——>CLOSEING——->TIME_WAIT,也就會Client和Server最後同時進入TIME_WAIT狀態
TCP 的 TIME_WAIT 狀態
要說明TIME_WAIT的問題,需要解答以下幾個問題:
Peer兩端,哪一端會進入TIME_WAIT呢?爲什麼?相信大家都知道,TCP主動關閉連接的那一方會最後進入TIME_WAIT。 那麼怎麼界定主動關閉方呢? 是否主動關閉是由FIN包的先後決定的,就是在自己沒收到對端Peer的FIN包之前自己發出了FIN包,那麼自己就是主動關閉連接的那一方。對於TCP 的 Peer 兩端同時斷開連接 描述的情況,那麼Peer兩邊都是主動關閉的一方,兩邊都會進入TIME_WAIT。爲什麼是主動關閉的一方進行TIME_WAIT呢,被動關閉的進入TIME_WAIT可以不呢? 我們來看看TCP四次揮手可以簡單分爲下面三個過程
過程一.主動關閉方 發送FIN;
過程二.被動關閉方 收到主動關閉方的FIN後 發送該FIN的ACK,被動關閉方發送FIN;
過程三.主動關閉方 收到被動關閉方的FIN後發送該FIN的ACK,被動關閉方等待自己FIN的ACK問題就在過程三中,據TCP協議規範,不對ACK進行ACK。 如果主動關閉方不進入TIME_WAIT,那麼主動關閉方在發送完ACK就走了的話:如果最後發送的ACK在路由過程中丟掉了,最後沒能到被動關閉方,這個時候被動關閉方 沒收到自己FIN的ACK就不能關閉連接,接着被動關閉方 會超時重發FIN包,但是這個時候已經沒有對端會給該FIN回ACK,被動關閉方就無法正常關閉連接了,所以主動關閉方需要進入TIME_WAIT 以便能夠重發丟掉的被動關閉方FIN的ACK。
TIME_WAIT狀態爲什麼需要經過2MSL的時間才關閉連接呢?
爲了保證A發送的最後一個確認報文段能夠到達B。這個確認報文段可能會丟失,如果B收不到這個確認報文段,其會重傳第三次“揮手”發送的FIN+ACK報文,而A則會在2MSL時間內收到這個重傳的報文段,每次A收到這個重傳報文段後,就會重啓2MSL計時器。這樣可以保證A和B都能正常關閉連接。
爲了防止已失效的報文段出現在下一次連接中。A經過2MSL時間後,可以保證在本次連接中傳輸的報文段都在網絡中消失,這樣一來就能保證在後面的連接中不會出現舊的連接產生的報文段了。
TIME_WAIT狀態是用來解決或避免什麼問題呢? TIME_WAIT主要是用來解決以下幾個問題:
上面解釋爲什麼主動關閉方需要進入TIME_WAIT狀態中提到的: 主動關閉方需要進入TIME_WAIT 以便能夠重發丟掉的被動關閉方FIN的ACK。如果主動關閉方不進入TIME_WAIT,那麼在主動關閉方對被動關閉方FIN包的ACK丟失了的時候,被動關閉方由於沒收到自己FIN的ACK,會進行重傳FIN包,這個FIN包到主動關閉方後,由於這個連接已經不存在於主動關閉方了,這個時候主動關閉方無法識別這個FIN包,協議棧會認爲對方瘋了,都還沒建立連接你給我來個FIN包?於是回覆一個RST包給被動關閉方,被動關閉方就會收到一個錯誤(我們見的比較多的:connect reset by peer,這裏順便說下 Broken pipe,在收到RST包的時候,還往這個連接寫數據,就會收到 Broken pipe錯誤了),原本應該正常關閉的連接,給我來個錯誤,很難讓人接受。
防止已經斷開的連接1中在鏈路中殘留的FIN包終止掉新的連接2(重用了連接1的所有的5元素(源IP,目的IP,TCP,源端口,目的端口)),這個概率比較低,因爲涉及到一個匹配問題,遲到的FIN分段的序列號必須落在連接2的一方的期望序列號範圍之內,雖然概率低,但是確實可能發生,因爲初始序列號都是隨機產生的,並且這個序列號是32位的,會迴繞。
防止鏈路上已經關閉的連接的殘餘數據包(a lost duplicate packet or a wandering duplicate packet) 干擾正常的數據包,造成數據流的不正常。這個問題和2)類似
TIME_WAIT會帶來哪些問題呢TIME_WAIT帶來的問題注意是源於:一個連接進入TIME_WAIT狀態後需要等待2*MSL(一般是1到4分鐘)那麼長的時間才能斷開連接釋放連接佔用的資源,會造成以下問題
作爲服務器,短時間內關閉了大量的Client連接,就會造成服務器上出現大量的TIME_WAIT連接,佔據大量的tuple,嚴重消耗着服務器的資源。
作爲客戶端,短時間內大量的短連接,會大量消耗的Client機器的端口,畢竟端口只有65535個,端口被耗盡了,後續就無法在發起新的連接了。
( 由於上面兩個問題,作爲客戶端需要連本機的一個服務的時候,首選UNIX域套接字而不是TCP )
TIME_WAIT很令人頭疼,很多問題是由TIME_WAIT造成的,但是TIME_WAIT又不是多餘的不能簡單將TIME_WAIT去掉,那麼怎麼來解決或緩解TIME_WAIT問題呢?可以進行TIME_WAIT的快速回收和重用來緩解TIME_WAIT的問題。
有沒一些清掉TIME_WAIT的技巧呢?
修改tcp_max_tw_buckets:tcp_max_tw_buckets 控制併發的TIME_WAIT的數量,默認值是180000。如果超過默認值,內核會把多的TIME_WAIT連接清掉,然後在日誌裏打一個警告。官網文檔說這個選項只是爲了阻止一些簡單的DoS***,平常不要人爲的降低它。
利用RST包從外部清掉TIME_WAIT鏈接:根據TCP規範,收到任何的發送到未偵聽端口、已經關閉的連接的數據包、連接處於任何非同步狀態(LISTEN, SYS-SENT, SYN-RECEIVED)並且收到的包的ACK在窗口外,或者安全層不匹配,都要回執以RST響應(而收到滑動窗口外的序列號的數據包,都要丟棄這個數據包,並回復一個ACK包),內核收到RST將會產生一個錯誤並終止該連接。我們可以利用RST包來終止掉處於TIME_WAIT狀態的連接,其實這就是所謂的RST***了。爲了描述方便:假設Client和Server有個連接Connect1,Server主動關閉連接並進入了TIME_WAIT狀態,我們來描述一下怎麼從外部使得Server的處於 TIME_WAIT狀態的連接Connect1提前終止掉。要實現這個RST***,首先我們要知道Client在Connect1中的端口port1(一般這個端口是隨機的,比較難猜到,這也是RST***較難的一個點),利用IP_TRANSPARENT這個socket選項,它可以bind不屬於本地的地址,因此可以從任意機器綁定Client地址以及端口port1,然後向Server發起一個連接,Server收到了窗口外的包於是響應一個ACK,這個ACK包會路由到Client處,這個時候99%的可能Client已經釋放連接connect1了,這個時候Client收到這個ACK包,會發送一個RST包,server收到RST包然後就釋放連接connect1提前終止TIME_WAIT狀態了。提前終止TIME_WAIT狀態是可能會帶來(問題二、)中說的三點危害,具體的危害情況可以看下RFC1337。RFC1337中建議,不要用RST過早的結束TIME_WAIT狀態。
TCP的延遲確認機制
TCP在何時發送ACK的時候有如下規定:
當有響應數據發送的時候,ACK會隨着數據一塊發送
如果沒有響應數據,ACK就會有一個延遲,以等待是否有響應數據一塊發送,但是這個延遲一般在40ms~500ms之間,一般情況下在40ms左右,如果在40ms內有數據發送,那麼ACK會隨着數據一塊發送,對於這個延遲的需要注意一下,這個延遲並不是指的是收到數據到發送ACK的時間延遲,而是內核會啓動一個定時器,每隔200ms就會檢查一次,比如定時器在0ms啓動,200ms到期,180ms的時候data來到,那麼200ms的時候沒有響應數據,ACK仍然會被髮送,這個時候延遲了20ms. 這樣做有兩個目的。
這樣做的目的是ACK是可以合併的,也就是指如果連續收到兩個TCP包,並不一定需要ACK兩次,只要回覆最終的ACK就可以了,可以降低網絡流量。
如果接收方有數據要發送,那麼就會在發送數據的TCP數據包裏,帶上ACK信息。這樣做,可以避免大量的ACK以一個單獨的TCP包發送,減少了網絡流量。
如果在等待發送ACK期間,第二個數據又到了,這時候就要立即發送ACK!
按照TCP協議,確認機制是累積的。也就是確認號X的確認指示的是所有X之前但不包括X的數據已經收到了。確認號(ACK)本身就是不含數據的分段,因此大量的確認號消耗了大量的帶寬,雖然大多數情況下,ACK還是可以和數據一起捎帶傳輸的,但是如果沒有捎帶傳輸,那麼就只能單獨回來一個ACK,如果這樣的分段太多,網絡的利用率就會下降。爲緩解這個問題,RFC建議了一種延遲的ACK,也就是說,ACK在收到數據後並不馬上回復,而是延遲一段可以接受的時間。延遲一段時間的目的是看能不能和接收方要發給發送方的數據一起回去,因爲TCP協議頭中總是包含確認號的,如果能的話,就將數據一起捎帶回去,這樣網絡利用率就提高了。延遲ACK就算沒有數據捎帶,那麼如果收到了按序的兩個包,那麼只要對第二包做確認即可,這樣也能省去一個ACK消耗。由於TCP協議不對ACK進行ACK的,RFC建議最多等待2個包的積累確認,這樣能夠及時通知對端Peer,我這邊的接收情況。Linux實現中,有延遲ACK(Delay Ack)和快速ACK,並根據當前的包的收發情況來在這兩種ACK中切換:在收到數據包的時候需要發送ACK,進行快速ACK;否則進行延遲ACK(在無法使用快速確認的條件下也是)。
一般情況下,ACK並不會對網絡性能有太大的影響,延遲ACK能減少發送的分段從而節省了帶寬,而快速ACK能及時通知發送方丟包,避免滑動窗口停等,提升吞吐率。
關於ACK分段,有個細節需要說明一下:
ACK的確認號,是確認按序收到的最後一個字節序,對於亂序到來的TCP分段,接收端會回覆相同的ACK分段,只確認按序到達的最後一個TCP分段。TCP連接的延遲確認時間一般初始化爲最小值40ms,隨後根據連接的重傳超時時間(RTO)、上次收到數據包與本次接收數據包的時間間隔等參數進行不斷調整。
推薦查看《TCP-IP詳解:Delay ACK》
TCP的重傳機制以及重傳的超時計算
前面說過,每一個數據包都帶有下一個數據包的編號。如果下一個數據包沒有收到,那麼 ACK 的編號就不會發生變化
如果發送方發現收到三個連續的重複 ACK,或者超時了還沒有收到任何 ACK,就會確認丟包,從而再次發送這個包。
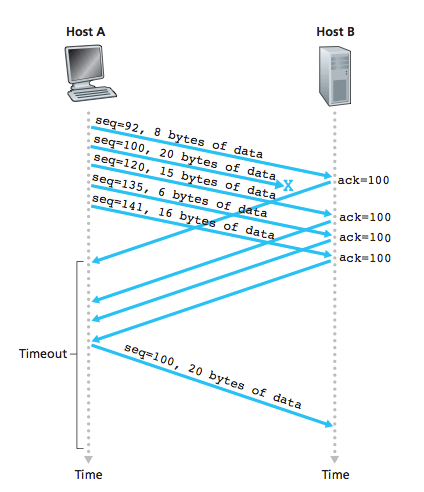
TCP的重傳超時計算
TCP交互過程中,如果發送的包一直沒收到ACK確認,是要一直等下去嗎?
顯然不能一直等(如果發送的包在路由過程中丟失了,對端都沒收到又如何給你發送確認呢?),這樣協議將不可用,既然不能一直等下去,那麼該等多久呢?等太長時間的話,數據包都丟了很久了才重發,沒有效率,性能差;等太短時間的話,可能ACK還在路上快到了,這時候卻重傳了,造成浪費,同時過多的重傳會造成網絡擁塞,進一步加劇數據的丟失。也是,我們不能去猜測一個重傳超時時間,應該是通過一個算法去計算,並且這個超時時間應該是隨着網絡的狀況在變化的。爲了使我們的重傳機制更高效,如果我們能夠比較準確知道在當前網絡狀況下,一個數據包從發出去到回來的時間RTT(Round Trip Time),那麼根據這個RTT(我們就可以方便設置RTO(Retransmission TimeOut)了。
如何計算設置這個RTO?
設長了,重發就慢,丟了老半天才重發,沒有效率,性能差;
設短了,會導致可能並沒有丟就重發。於是重發的就快,會增加網絡擁塞,導致更多的超時,更多的超時導致更多的重發。
RFC793中定義了一個經典算法——加權移動平均(Exponential weighted moving average),算法如下:
首先採樣計算RTT(Round Trip Time)值——也就是一個數據包從發出去到回來的時間
然後計算平滑的RTT,稱爲SRTT(Smoothed Round Trip Time),SRTT = ( ALPHA * SRTT ) + ((1-ALPHA) * RTT)——其中的 α 取值在0.8 到 0.9之間
RTO = min[UpBOUND,max[LowBOUND,(BETA*SRTT)]]——BETA(延遲方差因子(BETA is a delay variance factor (e.g., 1.3 to 2.0))
針對上面算法問題,有衆多大神改進,難以長篇累牘,推薦閱讀《TCP 的那些事兒》、《TCP中RTT的測量和RTO的計算》
TCP的重傳機制
通過上面我們可以知道,TCP的重傳是由超時觸發的,這會引發一個重傳選擇問題,假設TCP發送端連續發了1、2、3、4、5、6、7、8、9、10共10包,其中4、6、8這3個包全丟失了,由於TCP的ACK是確認最後連續收到序號,這樣發送端只能收到3號包的ACK,這樣在TIME_OUT的時候,發送端就面臨下面兩個重傳選擇:
僅重傳4號包
優點:按需重傳,能夠最大程度節省帶寬。
缺點:重傳會比較慢,因爲重傳4號包後,需要等下一個超時纔會重傳6號包
重傳3號後面所有的包,也就是重傳4~10號包
優點:重傳較快,數據能夠較快交付給接收端。
缺點:重傳了很多不必要重傳的包,浪費帶寬,在出現丟包的時候,一般是網絡擁塞,大量的重傳又可能進一步加劇擁塞。
上面的問題是由於單純以時間驅動來進行重傳的,都必須等待一個超時時間,不能快速對當前網絡狀況做出響應,如果加入以數據驅動呢?
TCP引入了一種叫Fast Retransmit(快速重傳 )的算法,就是在連續收到3次相同確認號的ACK,那麼就進行重傳。這個算法基於這麼一個假設,連續收到3個相同的ACK,那麼說明當前的網絡狀況變好了,可以重傳丟失的包了。
快速重傳解決了timeout的問題,但是沒解決重傳一個還是重傳多個的問題。出現難以決定是否重傳多個包問題的根源在於,發送端不知道那些非連續序號的包已經到達接收端了,但是接收端是知道的,如果接收端告訴一下發送端不就可以解決這個問題嗎?於是,RFC2018提出了 SACK(Selective Acknowledgment)——選擇確認機制,SACK是TCP的擴展選項

一個SACK的例子如下圖,紅框說明:接收端收到了0-5500,8000-8500,7000-7500,6000-6500的數據了,這樣發送端就可以選擇重傳丟失的5500-6000,6500-7000,7500-8000的包。
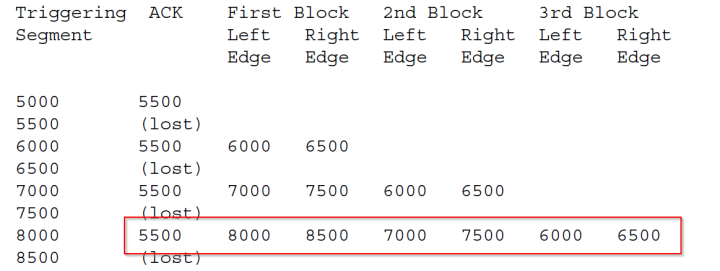
SACK依靠接收端的接收情況反饋,解決了重傳風暴問題,這樣夠了嗎?接收端能不能反饋更多的信息呢?顯然是可以的,於是,RFC2883對對SACK進行了擴展,提出了D-SACK,也就是利用第一塊SACK數據中描述重複接收的不連續數據塊的序列號參數,其他SACK數據則描述其他正常接收到的不連續數據。這樣發送方利用第一塊SACK,可以發現數據段被網絡複製、錯誤重傳、ACK丟失引起的重傳、重傳超時等異常的網絡狀況,使得發送端能更好調整自己的重傳策略。
D-SACK,有幾個優點:
發送端可以判斷出,是發包丟失了,還是接收端的ACK丟失了。(發送方,重傳了一個包,發現並沒有D-SACK那個包,那麼就是發送的數據包丟了;否則就是接收端的ACK丟了,或者是發送的包延遲到達了)
發送端可以判斷自己的RTO是不是有點小了,導致過早重傳(如果收到比較多的D-SACK就該懷疑是RTO小了)。
發送端可以判斷自己的數據包是不是被複制了。(如果明明沒有重傳該數據包,但是收到該數據包的D-SACK)
發送端可以判斷目前網絡上是不是出現了有些包被delay了,也就是出現先發的包卻後到了。
TCP的流量控制
ACK攜帶兩個信息。
期待要收到下一個數據包的編號
接收方的接收窗口的剩餘容量
TCP的標準窗口最大爲2^16-1=65535個字節
TCP的選項字段中還包含了一個TCP窗口擴大因子,option-kind爲3,option-length爲3個字節,option-data取值範圍0-14
窗口擴大因子用來擴大TCP窗口,可把原來16bit的窗口,擴大爲31bit。這個窗口是接收端告訴發送端自己還有多少緩衝區可以接收數據。於是發送端就可以根據這個接收端的處理能力來發送數據,而不會導致接收端處理不過來。也就是:
發送端是根據接收端通知的窗口大小來調整自己的發送速率的,以達到端到端的流量控制——Sliding Window(滑動窗口)。
TCP的窗口機制
TCP協議裏窗口機制有2種:一種是固定的窗口大小;一種是滑動的窗口。
這個窗口大小就是我們一次傳輸幾個數據。對所有數據幀按順序賦予編號,發送方在發送過程中始終保持着一個發送窗口,只有落在發送窗口內的幀才允許被髮送;同時接收方也維持着一個接收窗口,只有落在接收窗口內的幀才允許接收。這樣通過調整發送方窗口和接收方窗口的大小可以實現流量控制。
下面一張圖來分析一下固定窗口大小有什麼問題
假設窗口的大小是1,也是就每次只能發送一個數據只有接受方對這個數據進行確認了以後才能發送第2個數據。我們可以看到發送方每發送一個數據接受方就要給發送方一個ACK對這個數據進行確認。只有接受到了這個確認數據以後發送方纔能傳輸下個數據。 這樣我們考慮一下如果說窗口過小,那麼當傳輸比較大的數據的時候需要不停的對數據進行確認,這個時候就會造成很大的延遲。如果說窗口的大小定義的過大。我們假設發送方一次發送100個數據。但是接收方只能處理50個數據。這樣每次都會只對這50個數據進行確認。發送方下一次還是發送100個數據,但是接受方還是隻能處理50個數據。這樣就避免了不必要的數據來擁塞我們的鏈路。所以我們就引入了滑動窗口機制,窗口的大小並不是固定的而是根據我們之間的鏈路的帶寬的大小,這個時候鏈路是否擁護塞。接受方是否能處理這麼多數據了。
我們看看滑動窗口是如何工作的
圖片上傳失敗
重試
首先是第一次發送數據這個時候的窗口大小是根據鏈路帶寬的大小來決定的。我們假設這個時候窗口的大小是3。這個時候接受方收到數據以後會對數據進行確認告訴發送方我下次希望手到的是數據是多少。這裏我們看到接收方發送的ACK=3(這是發送方發送序列2的回答確認,下一次接收方期望接收到的是3序列信號)。這個時候發送方收到這個數據以後就知道我第一次發送的3個數據對方只收到了2個。就知道第3個數據對方沒有收到。下次在發送的時候就從第3個數據開始發。這個時候窗口大小就變成了2 。
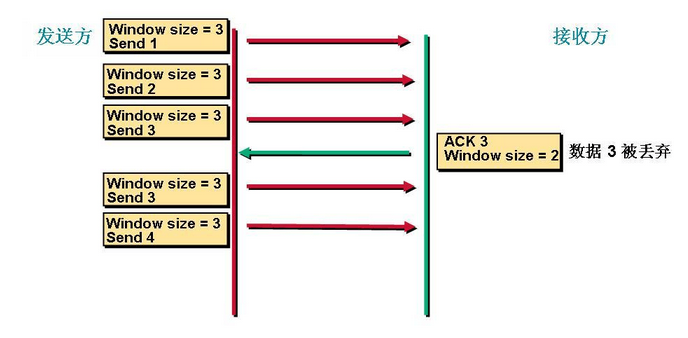
這個時候發送方發送2個數據。
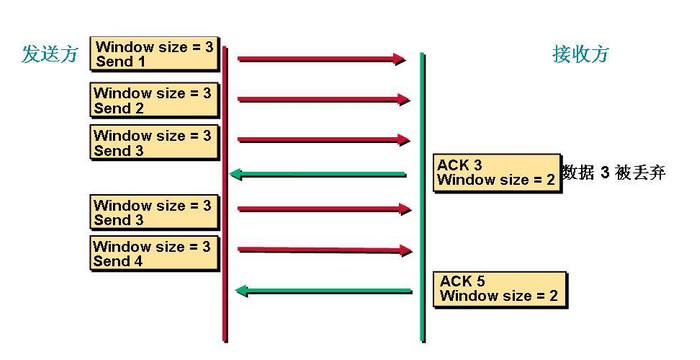
看到接收方發送的ACK是5就表示他下一次希望收到的數據是5,發送方就知道我剛纔發送的2個數據對方收了這個時候開始發送第5個數據。
這就是滑動窗口的工作機制,當鏈路變好了或者變差了這個窗口還會發生變話,並不是第一次協商好了以後就永遠不變了。
TCP滑動窗口剖析
滑動窗口協議的基本原理就是在任意時刻,發送方都維持了一個連續的允許發送的幀的序號,稱爲發送窗口;同時,接收方也維持了一個連續的允許接收的幀的序號,稱爲接收窗口。發送窗口和接收窗口的序號的上下界不一定要一樣,甚至大小也可以不同。不同的滑動窗口協議窗口大小一般不同。
窗口有3種動作:展開(右邊向右),合攏(左邊向右),收縮(右邊向左)這三種動作受接收端的控制。
合攏:表示已經收到相應字節的確認了
展開:表示允許緩存發送更多的字節
收縮(非常不希望出現的,某些實現是禁止的):表示本來可以發送的,現在不能發送;但是如果收縮的是那些已經發出的,就會有問題;爲了避免,收端會等待到緩存中有更多緩存空間時才進行通信。
滑動窗口機制
比特滑動窗口協議
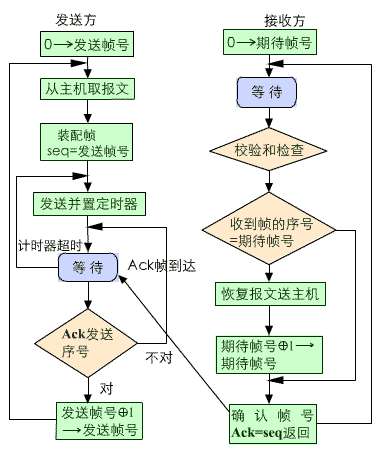
當發送窗口和接收窗口的大小固定爲1時,滑動窗口協議退化爲停等協議(stop-and-wait)。該協議規定發送方每發送一幀後就要停下來,等待接收方已正確接收的確認(acknowledgement)返回後才能繼續發送下一幀。由於接收方需要判斷接收到的幀是新發的幀還是重新發送的幀,因此發送方要爲每一個幀加一個序號。由於停等協議規定只有一幀完全發送成功後才能發送新的幀,因而只用一比特來編號就夠了。其發送方和接收方運行的流程圖如圖所示。
後退n協議
由於停等協議要爲每一個幀進行確認後才繼續發送下一幀,大大降低了信道利用率,因此又提出了後退n協議。後退n協議中,發送方在發完一個數據幀後,不停下來等待應答幀,而是連續發送若干個數據幀,即使在連續發送過程中收到了接收方發來的應答幀,也可以繼續發送。且發送方在每發送完一個數據幀時都要設置超時定時器。只要在所設置的超時時間內仍收到確認幀,就要重發相應的數據幀。如:當發送方發送了N個幀後,若發現該N幀的前一個幀在計時器超時後仍未返回其確認信息,則該幀被判爲出錯或丟失,此時發送方就不得不重新發送出錯幀及其後的N幀。
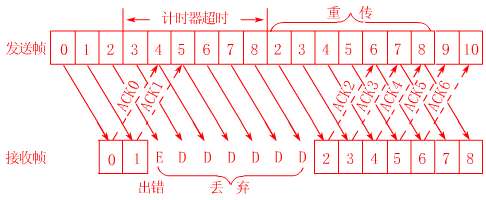
從這裏不難看出,後退n協議一方面因連續發送數據幀而提高了效率,但另一方面,在重傳時又必須把原來已正確傳送過的數據幀進行重傳(僅因這些數據幀之前有一個數據幀出了錯),這種做法又使傳送效率降低。由此可見,若傳輸信道的傳輸質量很差因而誤碼率較大時,連續測協議不一定優於停止等待協議。此協議中的發送窗口的大小爲k,接收窗口仍是1。
選擇重傳協議
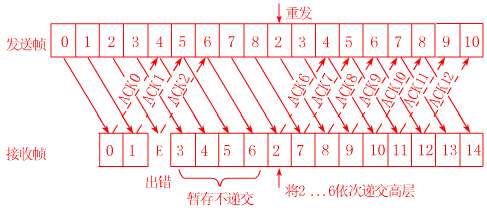
在後退n協議中,接收方若發現錯誤幀就不再接收後續的幀,即使是正確到達的幀,這顯然是一種浪費。另一種效率更高的策略是當接收方發現某幀出錯後,其後繼續送來的正確的幀雖然不能立即遞交給接收方的高層,但接收方仍可收下來,存放在一個緩衝區中,同時要求發送方重新傳送出錯的那一幀。一旦收到重新傳來的幀後,就可以原已存於緩衝區中的其餘幀一併按正確的順序遞交高層。這種方法稱爲選擇重發(SELECTICE REPEAT),其工作過程如圖所示。顯然,選擇重發減少了浪費,但要求接收方有足夠大的緩衝區空間。
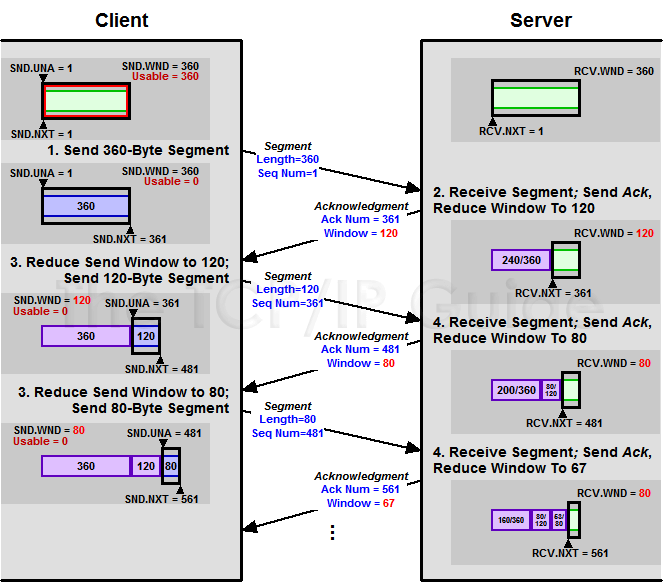
流量控制
所謂流量控制,主要是接收方傳遞信息給發送方,使其不要發送數據太快,是一種端到端的控制。主要的方式就是返回的ACK中會包含自己的接收窗口的大小,並且利用大小來控制發送方的數據發送。
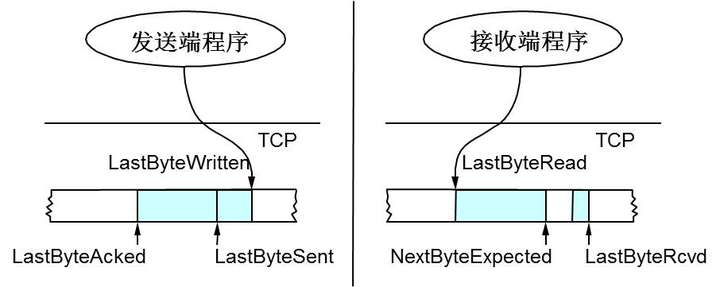
上圖中,我們可以看到:
接收端LastByteRead指向了TCP緩衝區中讀到的位置,NextByteExpected指向的地方是收到的連續包的最後一個位置,LastByteRcved指向的是收到的包的最後一個位置,我們可以看到中間有些數據還沒有到達,所以有數據空白區。
發送端的LastByteAcked指向了被接收端Ack過的位置(表示成功發送確認),LastByteSent表示發出去了,但還沒有收到成功確認的Ack,LastByteWritten指向的是上層應用正在寫的地方。
於是:
接收端在給發送端回ACK中會彙報自己的AdvertisedWindow = MaxRcvBuffer – LastByteRcvd – 1;
而發送方會根據這個窗口來控制發送數據的大小,以保證接收方可以處理。
下面我們來看一下發送方的滑動窗口示意圖:
圖片上傳失敗
重試
發送端是怎麼做到比較方便知道自己哪些包可以發,哪些包不能發呢?
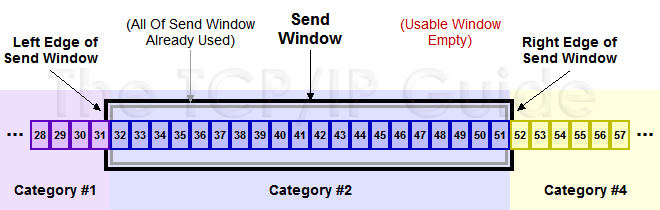
一個簡明的方案就是按照接收方的窗口通告,發送方維護一個一樣大小的發送窗口就可以了。在窗口內的可以發,窗口外的不可以發,窗口在發送序列上不斷後移,這就是TCP中的滑動窗口。如下圖所示,對於TCP發送端其發送緩存內的數據都可以分爲4類
[1]-已經發送並得到接收端ACK的;
[2]-已經發送但還未收到接收端ACK的;
[3]-未發送但允許發送的(接收方還有空間);
[4]-未發送且不允許發送(接收方沒空間了)。
其中,[2]和[3]兩部分合起來稱之爲發送窗口。
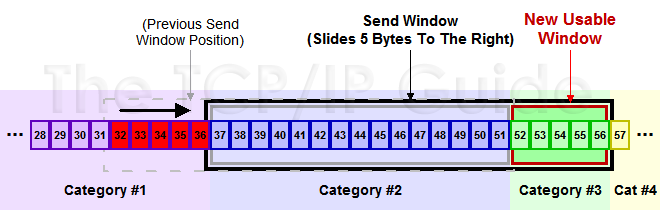
下面兩圖演示的窗口的滑動情況,收到36的ACK後,窗口向後滑動5個byte。
如果接收端通知一個零窗口給發送端,這個時候發送端還能不能發送數據呢?如果不發數據,那一直等接收端口通知一個非0窗口嗎,如果接收端一直不通知呢?
下圖,展示了一個發送端是怎麼受接收端控制的。
由上圖我們知道,當接收端通知一個zero窗口的時候,發送端的發送窗口也變成了0,也就是發送端不能發數據了。如果發送端一直等待,直到接收端通知一個非零窗口在發數據的話,這似乎太受限於接收端,如果接收端一直不通知新的窗口呢?顯然發送端不能幹等,起碼有一個主動探測的機制。爲解決0窗口的問題,TCP使用了ZWP(Zero Window Probe)。
Zero Window
發送端在窗口變成0後,會發ZWP的包給接收方,來探測目前接收端的窗口大小,讓接收方來ack他的Window尺寸。一般這個值會設置成3次,每次大約30-60秒(不同的實現可能會不一樣)。如果3次過後還是0的話,有的TCP實現就會發RST掉這個連接。
注意:只要有等待的地方都可能出現DDoS***。***者可以在和Server建立好連接後,就向Server通告一個0窗口,然後Server端就只能等待進行ZWP,於是***者會併發大量的這樣的請求,把Server端的資源耗盡。
Silly Window Syndrome
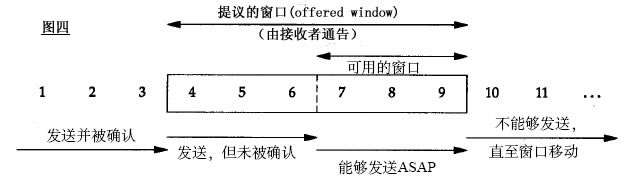
如果接收端處理能力很慢,這樣接收端的窗口很快被填滿,然後接收處理完幾個字節,騰出幾個字節的窗口後,通知發送端,這個時候發送端馬上就發送幾個字節給接收端嗎?發送的話會不會太浪費了,就像一艘萬噸油輪只裝上幾斤的油就開去目的地一樣。我們的TCP+IP頭有40個字節,爲了幾個字節,要達上這麼大的開銷,這太不經濟了。
對於發送端產生數據的能力很弱也一樣,如果發送端慢吞吞產生幾個字節的數據要發送,這個時候該不該立即發送呢?還是累積多點在發送?
本質就是一個避免發送大量小包的問題。造成這個問題原因有二:
接收端一直在通知一個小的窗口; 在接收端解決這個問題,David D Clark’s 方案,如果收到的數據導致window size小於某個值,就ACK一個0窗口,這就阻止發送端在發數據過來。等到接收端處理了一些數據後windows size 大於等於了MSS,或者buffer有一半爲空,就可以通告一個非0窗口。
發送端本身問題,一直在發送小包。這個問題,TCP中有個術語叫Silly Window Syndrome(糊塗窗口綜合症)。解決這個問題的思路有兩:
接收端不通知小窗口,
發送端積累一下數據在發送。
是在發送端解決這個問題,有個著名的Nagle’s algorithm。Nagle 算法的規則
如果包長度達到 MSS ,則允許發送;
如果該包含有 FIN ,則允許發送;
設置了 TCP_NODELAY 選項,則允許發送;
設置 TCP_CORK 選項時,若所有發出去的小數據包(包長度小於 MSS )均被確認,則允許發送;
上述條件都未滿足,但發生了超時(一般爲 200ms ),則立即發送。
規則[4]指出TCP連接上最多只能有一個未被確認的小數據包。從規則[4]可以看出Nagle算法並不禁止發送小的數據包(超時時間內),而是避免發送大量小的數據包。由於Nagle算法是依賴ACK的,如果ACK很快的話,也會出現一直髮小包的情況,造成網絡利用率低。TCP_CORK選項則是禁止發送小的數據包(超時時間內),設置該選項後,TCP會盡力把小數據包拼接成一個大的數據包(一個 MTU)再發送出去,當然也不會一直等,發生了超時(一般爲 200ms ),也立即發送。Nagle 算法和CP_CORK 選項提高了網絡的利用率,但是增加是延時。從規則[3]可以看出,設置TCP_NODELAY 選項,就是完全禁用Nagle 算法了。
這裏要說一個小插曲,Nagle算法和延遲確認(Delayed Acknoledgement)一起,當出現( write-write-read)的時候會引發一個40ms的延時問題,這個問題在HTTP svr中體現的比較明顯。場景如下:
客戶端在請求下載HTTP svr中的一個小文件,一般情況下,HTTP svr都是先發送HTTP響應頭部,然後在發送HTTP響應BODY(特別是比較多的實現在發送文件的實施採用的是sendfile系統調用,這就出現write-write-read模式了)。當發送頭部的時候,由於頭部較小,於是形成一個小的TCP包發送到客戶端,這個時候開始發送body,由於body也較小,這樣還是形成一個小的TCP數據包,根據Nagle算法,HTTP svr已經發送一個小的數據包了,在收到第一個小包的ACK後或等待200ms超時後才能在發小包,HTTP svr不能發送這個body小TCP包;
客戶端收到http響應頭後,由於這是一個小的TCP包,於是客戶端開啓延遲確認,客戶端在等待Svr的第二個包來在一起確認或等待一個超時(一般是40ms)在發送ACK包;這樣就出現了你等我、然而我也在等你的死鎖狀態,於是出現最多的情況是客戶端等待一個40ms的超時,然後發送ACK給HTTP svr,HTTP svr收到ACK包後在發送body部分。大家在測HTTP svr的時候就要留意這個問題了。
推薦閱讀《TCP/IP之TCP協議:流量控制(滑動窗口協議)》
TCP的擁塞控制
由於TCP看不到網絡的狀況,那麼擁塞控制是必須的並且需要採用試探性的方式來控制擁塞,於是擁塞控制要完成兩個任務:[1]公平性;[2]擁塞過後的恢復。
重介紹一下Reno算法(RFC5681),其包含4個部分:
[1]慢熱啓動算法 – Slow Start
[2]擁塞避免算法 – Congestion Avoidance;
[3]快速重傳 - Fast Retransimit;
[4]快速恢復算法 – Fast Recovery。
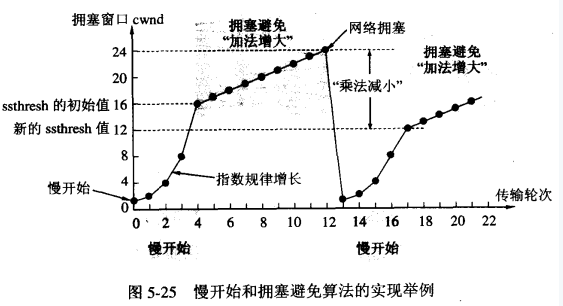
慢熱啓動算法 – Slow Start
我們怎麼知道,對方線路的理想速率是多少呢?答案就是慢慢試。
開始的時候,發送得較慢,然後根據丟包的情況,調整速率:如果不丟包,就加快發送速度;如果丟包,就降低發送速度。慢啓動的算法如下(cwnd全稱Congestion Window):
連接建好的開始先初始化cwnd = N,表明可以傳N個MSS大小的數據。
每當收到一個ACK,++cwnd; 呈線性上升
每當過了一個RTT,cwnd = cwnd*2; 呈指數讓升
還有一個慢啓動門限ssthresh(slow start threshold),是一個上限,當cwnd >= ssthresh時,就會進入"擁塞避免算法 - Congestion Avoidance"
根據RFC5681,如果MSS > 2190 bytes,則N = 2;如果MSS < 1095 bytes,則N = 4;如果2190 bytes >= MSS >= 1095 bytes,則N = 3;一篇Google的論文《An Argument for Increasing TCP’s Initial Congestion Window》建議把cwnd 初始化成了 10個MSS。Linux 3.0後採用了這篇論文的建議(Linux 內核裏面設定了(常量TCP_INIT_CWND),剛開始通信的時候,發送方一次性發送10個數據包,即"發送窗口"的大小爲10。然後停下來,等待接收方的確認,再繼續發送)
擁塞避免算法 – Congestion Avoidance
慢啓動的時候說過,cwnd是指數快速增長的,但是增長是有個門限ssthresh(一般來說大多數的實現ssthresh的值是65535字節)的,到達門限後進入擁塞避免階段。在進入擁塞避免階段後,cwnd值變化算法如下:
每收到一個ACK,調整cwnd 爲 (cwnd + 1/cwnd) * MSS個字節
每經過一個RTT的時長,cwnd增加1個MSS大小。
TCP是看不到網絡的整體狀況的,那麼TCP認爲網絡擁塞的主要依據是它重傳了報文段。前面我們說過TCP的重傳分兩種情況:
出現RTO超時,重傳數據包。這種情況下,TCP就認爲出現擁塞的可能性就很大,於是它反應非常'強烈'
調整門限ssthresh的值爲當前cwnd值的1/2。
reset自己的cwnd值爲1
然後重新進入慢啓動過程。
在RTO超時前,收到3個duplicate ACK進行重傳數據包。這種情況下,收到3個冗餘ACK後說明確實有中間的分段丟失,然而後面的分段確實到達了接收端,因爲這樣纔會發送冗餘ACK,這一般是路由器故障或者輕度擁塞或者其它不太嚴重的原因引起的,因此此時擁塞窗口縮小的幅度就不能太大,此時進入快速重傳。
快速重傳 - Fast Retransimit 做的事情有:
調整門限ssthresh的值爲當前cwnd值的1/2。
將cwnd值設置爲新的ssthresh的值
重新進入擁塞避免階段。
在快速重傳的時候,一般網絡只是輕微擁堵,在進入擁塞避免後,cwnd恢復的比較慢。針對這個,“快速恢復”算法被添加進來,當收到3個冗餘ACK時,TCP最後的[3]步驟進入的不是擁塞避免階段,而是快速恢復階段。
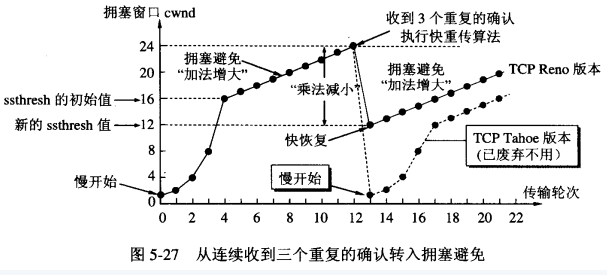
快速恢復算法 – Fast Recovery :
快速恢復的思想是“數據包守恆”原則,即帶寬不變的情況下,在網絡同一時刻能容納數據包數量是恆定的。當“老”數據包離開了網絡後,就能向網絡中發送一個“新”的數據包。既然已經收到了3個冗餘ACK,說明有三個數據分段已經到達了接收端,既然三個分段已經離開了網絡,那麼就是說可以在發送3個分段了。於是只要發送方收到一個冗餘的ACK,於是cwnd加1個MSS。快速恢復步驟如下(在進入快速恢復前,cwnd 和 sshthresh已被更新爲:sshthresh = cwnd /2,cwnd = sshthresh):
把cwnd設置爲ssthresh的值加3,重傳Duplicated ACKs指定的數據包
如果再收到 duplicated Acks,那麼cwnd = cwnd +1
如果收到新的ACK,而非duplicated Ack,那麼將cwnd重新設置爲【3】中1)的sshthresh的值。然後進入擁塞避免狀態。
細心的同學可能會發現快速恢復有個比較明顯的缺陷就是:它依賴於3個冗餘ACK,並假定很多情況下,3個冗餘的ACK只代表丟失一個包。但是3個冗餘ACK也很有可能是丟失了很多個包,快速恢復只是重傳了一個包,然後其他丟失的包就只能等待到RTO超時了。超時會導致ssthresh減半,並且退出了Fast Recovery階段,多個超時會導致TCP傳輸速率呈級數下降。出現這個問題的主要原因是過早退出了Fast Recovery階段。爲解決這個問題,提出了New Reno算法,該算法是在沒有SACK的支持下改進Fast Recovery算法(SACK改變TCP的確認機制,把亂序等信息會全部告訴對方,SACK本身攜帶的信息就可以使得發送方有足夠的信息來知道需要重傳哪些包,而不需要重傳哪些包),具體改進如下:
發送端收到3個冗餘ACK後,重傳冗餘ACK指示可能丟失的那個包segment1,如果segment1的ACK通告接收端已經收到發送端的全部已經發出的數據的話,那麼就是隻丟失一個包,如果沒有,那麼就是有多個包丟失了。
發送端根據segment1的ACK判斷出有多個包丟失,那麼發送端繼續重傳窗口內未被ACK的第一個包,直到sliding window內發出去的包全被ACK了,才真正退出Fast Recovery階段。
我們可以看到,擁塞控制在擁塞避免階段,cwnd是加性增加的,在判斷出現擁塞的時候採取的是指數遞減。爲什麼要這樣做呢?這是出於公平性的原則,擁塞窗口的增加受惠的只是自己,而擁塞窗口減少受益的是大家。這種指數遞減的方式實現了公平性,一旦出現丟包,那麼立即減半退避,可以給其他新建的連接騰出足夠的帶寬空間,從而保證整個的公平性。
TCP發展到現在,擁塞控制方面的算法很多,請查看《wiki-具體實現算法》,《斐訊面試記錄—TCP滑動窗口及擁塞控制》
總的來說TCP是一個有連接的、可靠的、帶流量控制和擁塞控制的端到端的協議。TCP的發送端能發多少數據,由發送端的發送窗口決定(當然發送窗口又被接收端的接收窗口、發送端的擁塞窗口限制)的,那麼一個TCP連接的傳輸穩定狀態應該體現在發送端的發送窗口的穩定狀態上,這樣的話,TCP的發送窗口有哪些穩定狀態呢?
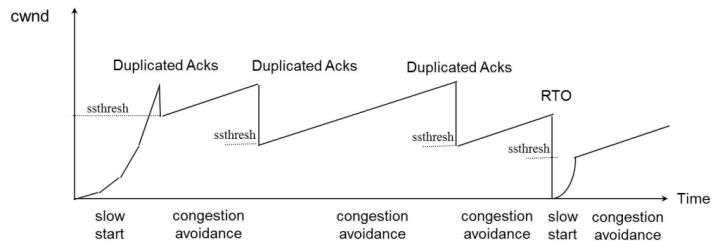
TCP的發送窗口穩定狀態主要有上面三種穩定狀態:
【1】接收端擁有大窗口的經典鋸齒狀
大多數情況下都是處於這樣的穩定狀態,這是因爲,一般情況下機器的處理速度就是比較快,這樣TCP的接收端都是擁有較大的窗口,這時發送端的發送窗口就完全由其擁塞窗口cwnd決定了;網絡上擁有成千上萬的TCP連接,它們在相互爭用網絡帶寬,TCP的流量控制使得它想要獨享整個網絡,而擁塞控制又限制其必要時做出犧牲來體現公平性。於是在傳輸穩定的時候TCP發送端呈現出下面過程的反覆
[1]用慢啓動或者擁塞避免方式不斷增加其擁塞窗口,直到丟包的發生;
[2]然後將發送窗口將下降到1或者下降一半,進入慢啓動或者擁塞避免階段(要看是由於超時丟包還是由於冗餘ACK丟包);過程如下圖:
【2】接收端擁有小窗口的直線狀態
這種情況下是接收端非常慢速,接收窗口一直很小,這樣發送窗口就完全有接收窗口決定了。由於發送窗口小,發送數據少,網絡就不會出現擁塞了,於是發送窗口就一直穩定的等於那個較小的接收窗口,呈直線狀態。
【3】兩個直連網絡端點間的滿載狀態下的直線狀態
這種情況下,Peer兩端直連,並且只有位於一個TCP連接,那麼這個連接將獨享網絡帶寬,這裏不存在擁塞問題,在他們處理能力足夠的情況下,TCP的流量控制使得他們能夠跑慢整個網絡帶寬。
通過上面我們知道,在TCP傳輸穩定的時候,各個TCP連接會均分網絡帶寬的。相信大家學生時代經常會發生這樣的場景,自己在看視頻的時候突然出現視頻卡頓,於是就大叫起來,哪個開了迅雷,趕緊給我停了。其實簡單的下載加速就是開啓多個TCP連接來分段下載就達到加速的效果,假設宿舍的帶寬是1000K/s,一開始兩個在看視頻,每人平均網速是500k/s,這速度看起視頻來那叫一個順溜。突然其中一個同學打打開迅雷開着99個TCP連接在下載愛情動作片,這個時候平均下來你能分到的帶寬就剩下10k/s,這網速下你的視頻還不卡成幻燈片。在通信鏈路帶寬固定(假設爲W),多人公用一個網絡帶寬的情況下,利用TCP協議的擁塞控制的公平性,多開幾個TCP連接就能多分到一些帶寬(當然要忽略有些用UDP協議帶來的影響),然而不管怎麼最多也就能把整個帶寬搶到,於是在佔滿整個帶寬的情況下,下載一個大小爲FS的文件,那麼最快需要的時間是FS/W,難道就沒辦法加速了嗎?
答案是有的,這樣因爲網絡是網狀的,一個節點是要和很多幾點互聯的,這就存在多個帶寬爲W的通信鏈路,如果我們能夠將要下載的文件,一半從A通信鏈路下載,另外一半從B通信鏈路下載,這樣整個下載時間就減半了爲FS/(2W),這就是p2p加速。
其實《不爲人知的網絡編程:淺析TCP協議中的疑難雜症》講的非常細,而且一遍文章根本總結不了(我也只是搬運工而已,因爲所知的太少,都不像筆記了
基礎科普類:https://hit-alibaba.github.io/interview/basic/network/HTTP.html
推薦文章:
《TCP 協議簡介》(阮一峯)
推薦書本:
圖解HTTP,圖解TCP/IP 系列書(日本人出的)或者head first 系列的,嗑書的話:清華大學出版社的TCP/IP原理(美版教程翻譯版)。不要讀啥 十天學會網絡工程、tcp ip 這樣學的 一些水貨文章,基本上是浪費時間。
本文原文出處:《在深談TCP/IP三步握手&四步揮手原理及衍生問題-長文解剖IP - Network - 周陸軍的個人網站》,不妥之處,請留言告知,多謝
本文原文出處:《在深談TCP/IP三步握手&四步揮手原理及衍生問題-長文解剖IP - Network - 周陸軍的個人網站》,不妥之處,請留言告知,多謝