




爲了把百度文檔的內容弄下來,就弄了一下這個
- 基本環境
操作系統:win7 64位系統
python版本:3.7
2.安裝配套環境
2.1 首先安裝OCR字符識別庫Tesseract 下載網址:https://digi.bib.uni-mannheim.de/tesseract/
我下載的是:tesseract-ocr-w64-setup-v4.0.0-beta.4.20180912.exe
2.2 下載後雙擊進行安裝,這裏因爲我們要識別中文字符,所以在安裝界面中需要進行額外的語言勾選,展開Additional language data(這裏添加語言可能會出現語言包安裝失敗,可單獨下載語言包,放入安裝目錄下的tessdata下即可)
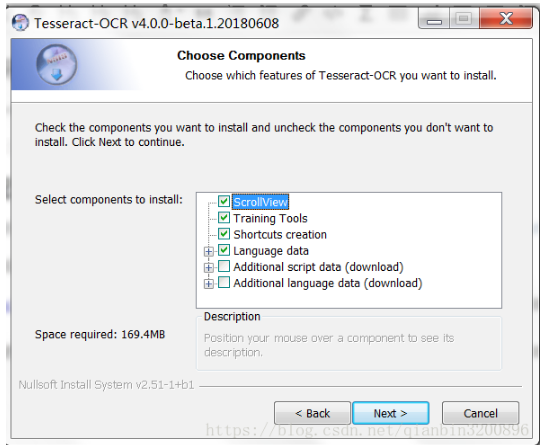
然後按照下圖進行勾選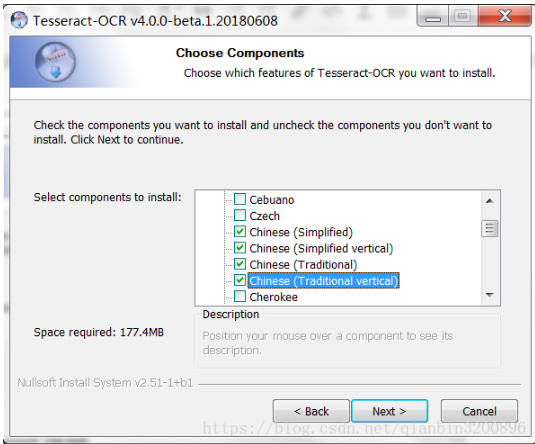
2.3 安裝python環境
pip install Pillow
pip install pytesseract
2.4 修改pytesseract.py(在這路徑下 python37\Scripts)
tesseract_cmd = 'D:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
3.測試(識別中文的時候,在剪切圖片,要讓數字稍微大一點,把數字放在圖片中心,若識別出來,錯別字比較多的話,再重新弄一次圖片來識別)
#coding=utf-8
from PIL import Image
import pytesseract
text=pytesseract.image_to_string(Image.open('H:/2.png'),lang='chi_sim')
for i in text.split("\n"):
print(i.replace(" ",""))
報錯提示語言包,可在這下面進行下載
https://github.com/tesseract-ocr/tessdata
參考文檔:
還有一些關閉了,沒有copy到url,可以百度後google,一大堆
https://blog.csdn.net/a519395243/article/details/80447038