今天一位網友突然在deepin羣裏問怎麼抓取一個站點。他自己用的wget嘗試了一下,太繁瑣。失敗了。有網友建議他學習爬蟲技術的,也有說右鍵保存的,直到有個網友提到了webhttrack這個工具。
webhttrack這個工具算是一個簡單的,只需要點擊幾個按鈕就能抓取整個站點的工具。簡單又好用。本來是不打算寫博的,無奈那位網友又沒解決。隨寫博客以示之。
webhttrack這個工具在deepin的官方源裏面就有,所以不必下載deb包,也不需要添加源或者下載源碼編譯安裝。我能確定的是在ubuntu的官方源裏也有。其他的Linux發行版用戶可以嘗試一下官方源,官方源沒有再去webhttrack的官網去下載相應的軟件包安裝吧。下面是deepin下的安裝方式:
$ sudo apt-get install webhttrack
安裝完直接在終端下運行就行了:
$ webhttrack
然後會啓動一個瀏覽器引導着你一步一步完成一個網站的抓取。1、2、3……step by step超級簡單。
下面以一個實例來展示一下webhttrack的應用。我們以抓取菜鳥網中的一個c++學習部分內容爲例來展開。- $ webhttrack 啓動webhttrack
- webhttrack會自動啓動瀏覽器出現引導界面。如圖:
![輕而易舉的抓取一個web站點]()
直接點擊“next”進入下一步。
3.在這一步裏會出現選擇工程名稱和保存路徑的選擇。由於是第一次操作不會有現有工程名供選擇也不會有次級Project category供選擇。什麼意思呢?意思是你只要用過一次,下一次操作你可以選擇上一次的工程名稱及次級名稱會在下拉列表顯示。這裏直接取名:“菜鳥教程網”,Project category就取名c++吧。保存路徑默認就行。然後“next”。由於我做過了,名稱就不在圖片輸入了,請讀者自行輸入。附圖:![輕而易舉的抓取一個web站點]()
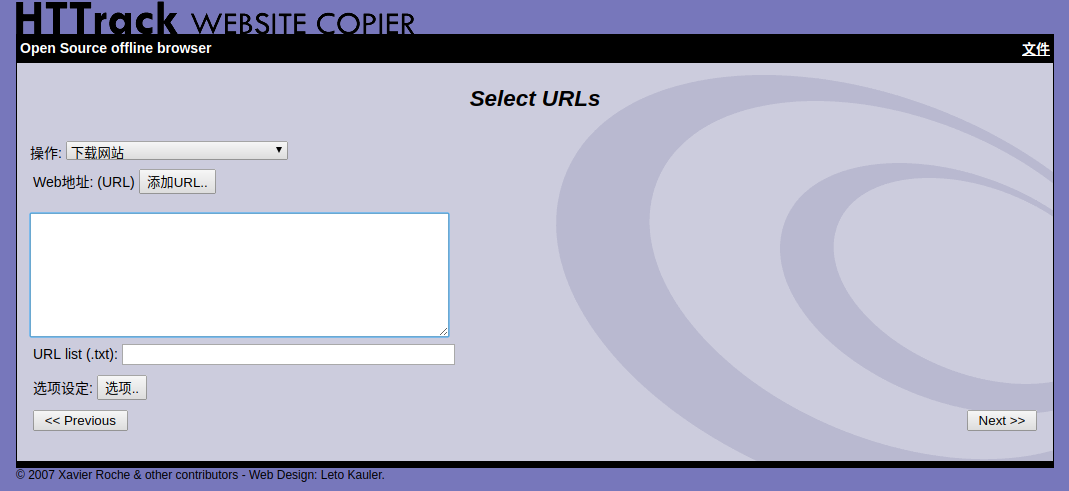
4. 到這一步直接輸入URL就行。操作項目列表其實就是個篩選,你可以下載整個網站或者下載個別文件等等。你甚至可以輸入多個url下載,只需編輯多個URL爲txt文本文件導入就行。“選項”按鈕的設定其實也是一個篩選,是一個更高級的全面的篩選。如果需要的話。默認我們只輸入url來抓取我們需要的c++教程部分;http://www.runoob.com/cplusplus/cpp-tutorial.html 點擊“next”下一步。附圖:![輕而易舉的抓取一個web站點]()
5. 這一步就自動化進行了,你可以人爲忽略其中的某些部分,也可以隨時終止。附圖:![輕而易舉的抓取一個web站點]()
- 最後一步,“站點鏡像完畢!”在點擊“退出”之前你可以選擇“查看日誌”或“瀏覽已鏡像的網站”。退出以後也可已瀏覽,不必輸入長長的網址。只要在你用戶名目錄下找到一個目錄“websites”進入雙擊index.html文件就可以瀏覽了,打開還需要點擊一下鏈接就是你要瀏覽的內容。
![輕而易舉的抓取一個web站點]()