




Zipkin是什麼
Zipkin分佈式跟蹤系統;它可以幫助收集時間數據,解決在microservice架構下的延遲問題;它管理這些數據的收集和查找;Zipkin的設計是基於谷歌的Google Dapper論文。願意瞭解源碼的朋友直接求求交流分享技術:二一四七七七五六三三
每個應用程序向Zipkin報告定時數據,Zipkin UI呈現了一個依賴圖表來展示多少跟蹤請求經過了每個應用程序;如果想解決延遲問題,可以過濾或者排序所有的跟蹤請求,並且可以查看每個跟蹤請求佔總跟蹤時間的百分比。
爲什麼使用Zipkin
隨着業務越來越複雜,系統也隨之進行各種拆分,特別是隨着微服務架構和容器技術的興起,看似簡單的一個應用,後臺可能有幾十個甚至幾百個服務在支撐;一個前端的請求可能需要多次的服務調用最後才能完成;當請求變慢或者不可用時,我們無法得知是哪個後臺服務引起的,這時就需要解決如何快速定位服務故障點,Zipkin分佈式跟蹤系統就能很好的解決這樣的問題。
Zipkin原理
針對服務化應用全鏈路追蹤的問題,Google發表了Dapper論文,介紹了他們如何進行服務追蹤分析。其基本思路是在服務調用的請求和響應中加入ID,標明上下游請求的關係。利用這些信息,可以可視化地分析服務調用鏈路和服務間的依賴關係。
對應Dpper的開源實現是Zipkin,支持多種語言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多種不同的庫來支持
Spring Cloud Sleuth是對Zipkin的一個封裝,對於Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server發送採集信息等全部自動完成。
Zipkin架構
跟蹤器(Tracer)位於你的應用程序中,並記錄發生的操作的時間和元數據,提供了相應的類庫,對用戶的使用來說是透明的,收集的跟蹤數據稱爲Span;將數據發送到Zipkin的儀器化應用程序中的組件稱爲Reporter,Reporter通過幾種傳輸方式之一將追蹤數據發送到Zipkin收集器(collector),然後將跟蹤數據進行存儲(storage),由API查詢存儲以向UI提供數據。
架構圖如下: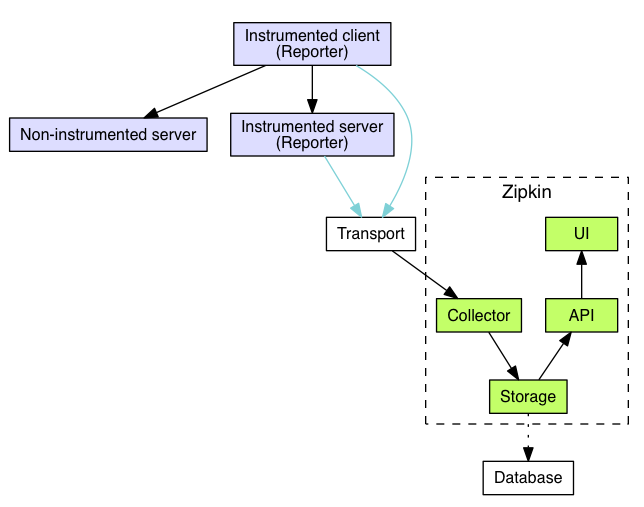
1.Trace
Zipkin使用Trace結構表示對一次請求的跟蹤,一次請求可能由後臺的若干服務負責處理,每個服務的處理是一個Span,Span之間有依賴關係,Trace就是樹結構的Span集合;
2.Span
每個服務的處理跟蹤是一個Span,可以理解爲一個基本的工作單元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等。
3.Transport
收集的Spans必須從被追蹤的服務運輸到Zipkin collector,有三個主要的傳輸方式:HTTP, Kafka和Scribe;
4.Components
有4個組件組成Zipkin:collector,storage,search,web UI
collector:一旦跟蹤數據到達Zipkin collector守護進程,它將被驗證,存儲和索引,以供Zipkin收集器查找;
storage:Zipkin最初數據存儲在Cassandra上,因爲Cassandra是可擴展的,具有靈活的模式,並在Twitter中大量使用;但是這個組件可插入,除了Cassandra之外,還支持ElasticSearch和MySQL; 存儲,zipkin默認的存儲方式爲in-memory,即不會進行持久化操作。如果想進行收集數據的持久化,可以存儲數據在Cassandra,因爲Cassandra是可擴展的,有一個靈活的模式,並且在Twitter中被大量使用,我們使這個組件可插入。除了Cassandra,我們原生支持ElasticSearch和MySQL。其他後端可能作爲第三方擴展提供。
search:一旦數據被存儲和索引,我們需要一種方法來提取它。查詢守護進程提供了一個簡單的JSON API來查找和檢索跟蹤,主要給Web UI使用;
web UI:創建了一個GUI,爲查看痕跡提供了一個很好的界面;Web UI提供了一種基於服務,時間和註釋查看跟蹤的方法。
整體代碼結構如下: